
!版权声明:本博客内容均均为原创,每篇博文作为知识积累,写博不易,转载请注明出处。
目录[-]
系统环境:
Kubernetes 版本:1.14.0
kafka 版本:2.3.0
zookeeper 版本:3.4.14
kafka manager 版本:1.3.3
示例部署文件 Github 地址:https://github.com/my-dlq/blog-example/tree/master/kubernetes/kafka-zookeeper-deploy
一、简介
Kafka 简介
Kafka 是由 Apache 软件基金会开发的一个开源流处理平台,由 Scala 和 Java 编写。它是一个分布式、支持分区的的、多副本,基于 zookeeper 协调的分布式消息系统。它最大特性是可以实时的处理大量数据以满足各种需求场景,比如基于 Hadoop 的批处理系统、低延时的实时系统、storm/Spark 流式处理引擎,web/nginx 日志,访问日志,消息服务等等。
Zookeeper 简介
ZooKeeper 是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper 通过其简单的架构和 API 解决了这个问题。 ZooKeeper 允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
Kafka 中主要利用 zookeeper 解决分布式一致性问题。Kafka 使用 Zookeeper 的分布式协调服务将生产者,消费者,消息储存结合在一起。同时借助 Zookeeper,Kafka 能够将生产者、消费者和 Broker 在内的所有组件在无状态的条件下建立起生产者和消费者的订阅关系,实现生产者的负载均衡。
Kafka Manager 简介
Kafka Manager 是目前最受欢迎的 Kafka 集群管理工具,最早由雅虎开源,用户可以在 Web 界面执行一些简单的集群管理操作。
支持以下功能:
管理 Kafka 集群
方便集群状态监控 (包括topics, consumers, offsets, brokers, replica distribution, partition distribution)
方便选择分区副本
配置分区任务,包括选择使用哪些 Brokers
可以对分区任务重分配
提供不同的选项来创建及删除 Topic
Topic List 会指明哪些topic被删除
批量产生分区任务并且和多个topic和brokers关联
批量运行多个主题对应的多个分区
向已经存在的主题中添加分区
对已经存在的 Topic 修改配置
可以在 Broker Level 和 Topic Level 的度量中启用 JMX Polling 功能
可以过滤在 ZooKeeper 上没有 ids/owners/offsets/directories 的 consumer
二、部署过程
这个流程需要部署三个组件,分别为 Zookeeper、Kafka、Kafka Manager:
(1)、Zookeeper: 首先部署 Zookeeper,方便后续部署 Kafka 节点注册到 Zookeeper,用 StatefulSet 方式部署三个节点。
(2)、Kafka: 第二个部署的是 Kafka,设置环境变量来指定 Zookeeper 地址,用 StatefulSet 方式部署。
(3)、Kafka Manager: 最后部署的是 Kafka Manager,用 Deployment 方式部署,然后打开 Web UI 界面来管理、监控 Kafka。
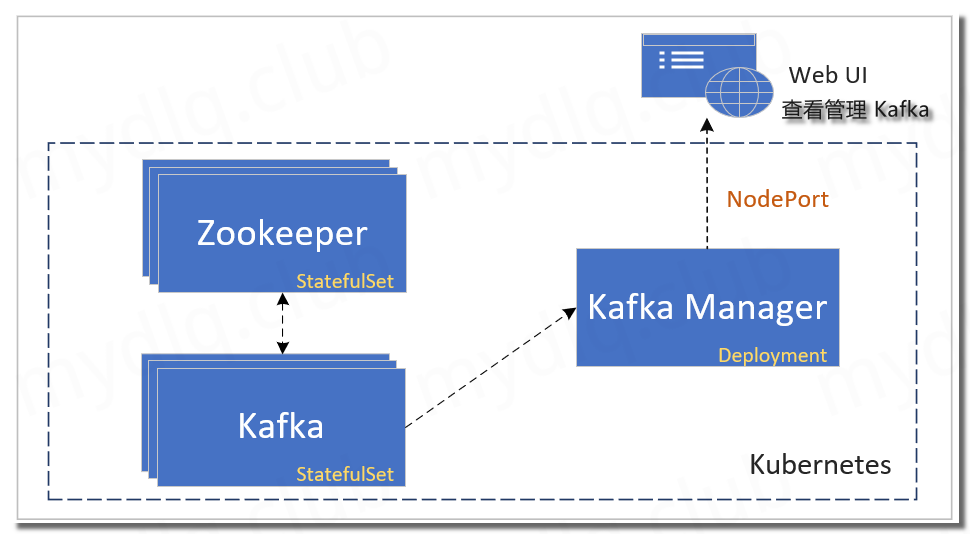
三、Kubernetes 部署 Zookeeper & Kafka & Kafka Manager
1、创建 StorageClass
由于都是使用 StatefulSet 方式部署的有状态服务,所以 Kubernetes 集群需要提前设置一个 StorageClass 方便后续部署时指定存储分配(如果想指定为已经存在的 StorageClass 创建 PV 则跳过此步骤)。
此处用的是 NFS 存储驱动,如果是其它存储需要提前设置好相关配置
创建 StorageClass 部署文件
nfs-storage.yaml
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: nfs-storage provisioner: nfs-client #动态卷分配服务指定的名称 parameters: archiveOnDelete: "true" #设置为"false"时删除PVC不会保留数据,"true"则保留数据 mountOptions: - hard #指定为硬挂载方式 - nfsvers=4 #指定NFS版本
部署 StorageClass
$ kubectl apply -f nfs-storage.yaml
2、Kubernetes 部署 Zookeeper
创建 Zookeeper 部署文件
zookeeper.yaml
#部署 Service Headless,用于Zookeeper间相互通信
apiVersion: v1
kind: Service
metadata:
name: zookeeper-headless
labels:
app: zookeeper
spec:
type: ClusterIP
clusterIP: None
publishNotReadyAddresses: true
ports:
- name: client
port: 2181
targetPort: client
- name: follower
port: 2888
targetPort: follower
- name: election
port: 3888
targetPort: election
selector:
app: zookeeper
---
#部署 Service,用于外部访问 Zookeeper
apiVersion: v1
kind: Service
metadata:
name: zookeeper
labels:
app: zookeeper
spec:
type: ClusterIP
ports:
- name: client
port: 2181
targetPort: client
- name: follower
port: 2888
targetPort: follower
- name: election
port: 3888
targetPort: election
selector:
app: zookeeper
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: zookeeper
labels:
app: zookeeper
spec:
serviceName: zookeeper-headless
replicas: 3
podManagementPolicy: Parallel
updateStrategy:
type: RollingUpdate
selector:
matchLabels:
app: zookeeper
template:
metadata:
name: zookeeper
labels:
app: zookeeper
spec:
securityContext:
fsGroup: 1001
containers:
- name: zookeeper
image: docker.io/bitnami/zookeeper:3.4.14-debian-9-r25
imagePullPolicy: IfNotPresent
securityContext:
runAsUser: 1001
command:
- bash
- -ec
- |
# Execute entrypoint as usual after obtaining ZOO_SERVER_ID based on POD hostname
HOSTNAME=`hostname -s`
if [[ $HOSTNAME =~ (.*)-([0-9]+)$ ]]; then
ORD=${BASH_REMATCH[2]}
export ZOO_SERVER_ID=$((ORD+1))
else
echo "Failed to get index from hostname $HOST"
exit 1
fi
. /opt/bitnami/base/functions
. /opt/bitnami/base/helpers
print_welcome_page
. /init.sh
nami_initialize zookeeper
exec tini -- /run.sh
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 250m
memory: 256Mi
env:
- name: ZOO_PORT_NUMBER
value: "2181"
- name: ZOO_TICK_TIME
value: "2000"
- name: ZOO_INIT_LIMIT
value: "10"
- name: ZOO_SYNC_LIMIT
value: "5"
- name: ZOO_MAX_CLIENT_CNXNS
value: "60"
- name: ZOO_SERVERS
value: "
zookeeper-0.zookeeper-headless:2888:3888,
zookeeper-1.zookeeper-headless:2888:3888,
zookeeper-2.zookeeper-headless:2888:3888
"
- name: ZOO_ENABLE_AUTH
value: "no"
- name: ZOO_HEAP_SIZE
value: "1024"
- name: ZOO_LOG_LEVEL
value: "ERROR"
- name: ALLOW_ANONYMOUS_LOGIN
value: "yes"
ports:
- name: client
containerPort: 2181
- name: follower
containerPort: 2888
- name: election
containerPort: 3888
livenessProbe:
tcpSocket:
port: client
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 6
readinessProbe:
tcpSocket:
port: client
initialDelaySeconds: 5
periodSeconds: 10
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 6
volumeMounts:
- name: data
mountPath: /bitnami/zookeeper
volumeClaimTemplates:
- metadata:
name: data
annotations:
spec:
storageClassName: nfs-storage #指定为上面创建的 storageclass
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi部署 Zookeeper
-n:指定应用启动的 Namespace,替换自己集群的 Namespace
$ kubectl apply -f zookeeper.yaml -n mydlqcloud
3、Kubernetes 部署 Kafka
创建 Kafka 部署文件
kafka.yaml
#部署 Service Headless,用于Kafka间相互通信 apiVersion: v1 kind: Service metadata: name: kafka-headless labels: app: kafka spec: type: ClusterIP clusterIP: None ports: - name: kafka port: 9092 targetPort: kafka selector: app: kafka --- #部署 Service,用于外部访问 Kafka apiVersion: v1 kind: Service metadata: name: kafka labels: app: kafka spec: type: ClusterIP ports: - name: kafka port: 9092 targetPort: kafka selector: app: kafka --- apiVersion: apps/v1 kind: StatefulSet metadata: name: "kafka" labels: app: kafka spec: selector: matchLabels: app: kafka serviceName: kafka-headless podManagementPolicy: "Parallel" replicas: 3 updateStrategy: type: "RollingUpdate" template: metadata: name: "kafka" labels: app: kafka spec: securityContext: fsGroup: 1001 runAsUser: 1001 containers: - name: kafka image: "docker.io/bitnami/kafka:2.3.0-debian-9-r4" imagePullPolicy: "IfNotPresent" resources: limits: cpu: 500m memory: 512Mi requests: cpu: 250m memory: 256Mi env: - name: MY_POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: MY_POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: KAFKA_CFG_ZOOKEEPER_CONNECT value: "zookeeper" #Zookeeper Service 名称 - name: KAFKA_PORT_NUMBER value: "9092" - name: KAFKA_CFG_LISTENERS value: "PLAINTEXT://:$(KAFKA_PORT_NUMBER)" - name: KAFKA_CFG_ADVERTISED_LISTENERS value: 'PLAINTEXT://$(MY_POD_NAME).kafka-headless:$(KAFKA_PORT_NUMBER)' - name: ALLOW_PLAINTEXT_LISTENER value: "yes" - name: KAFKA_HEAP_OPTS value: "-Xmx512m -Xms512m" - name: KAFKA_CFG_LOGS_DIRS value: /opt/bitnami/kafka/data - name: JMX_PORT value: "9988" ports: - name: kafka containerPort: 9092 livenessProbe: tcpSocket: port: kafka initialDelaySeconds: 10 periodSeconds: 10 timeoutSeconds: 5 successThreshold: 1 failureThreshold: 2 readinessProbe: tcpSocket: port: kafka initialDelaySeconds: 5 periodSeconds: 10 timeoutSeconds: 5 successThreshold: 1 failureThreshold: 6 volumeMounts: - name: data mountPath: /bitnami/kafka volumeClaimTemplates: - metadata: name: data spec: storageClassName: nfs-storage #指定为上面创建的 storageclass accessModes: - "ReadWriteOnce" resources: requests: storage: 5Gi
部署 Kafka
-n:指定应用启动的 Namespace,替换自己集群的 Namespace
$ kubectl apply -f kafka.yaml -n mydlqcloud
4、Kubernetes 部署 Kafka Manager
创建 Kafka Manager 部署文件
kafka-manager.yaml
apiVersion: v1 kind: Service metadata: name: kafka-manager labels: app: kafka-manager spec: type: NodePort ports: - name: kafka port: 9000 targetPort: 9000 nodePort: 30900 selector: app: kafka-manager --- apiVersion: apps/v1 kind: Deployment metadata: name: kafka-manager labels: app: kafka-manager spec: replicas: 1 selector: matchLabels: app: kafka-manager template: metadata: labels: app: kafka-manager spec: containers: - name: kafka-manager image: zenko/kafka-manager:1.3.3.22 imagePullPolicy: IfNotPresent ports: - name: kafka-manager containerPort: 9000 protocol: TCP env: - name: ZK_HOSTS value: "zookeeper:2181" livenessProbe: httpGet: path: /api/health port: kafka-manager readinessProbe: httpGet: path: /api/health port: kafka-manager resources: limits: cpu: 500m memory: 512Mi requests: cpu: 250m memory: 256Mi
部署 Kafka Manager
-n:指定应用启动的 Namespace,替换自己集群的 Namespace
$ kubectl apply -f kafka-manager.yaml -n mydlqcloud
四、进入 Kafka Manager 管理 Kafka 集群
这里的 Kubernetes 集群地址为:192.168.2.11,并且在上面设置 Kafka-Manager 网络策略为 NodePort 方式,且设置端口为 30900,这里输入地址:http://192.168.2.11:30900 访问 Kafka Manager。
进入后先配置 Kafka Manager,增加一个 Zookeeper 地址。
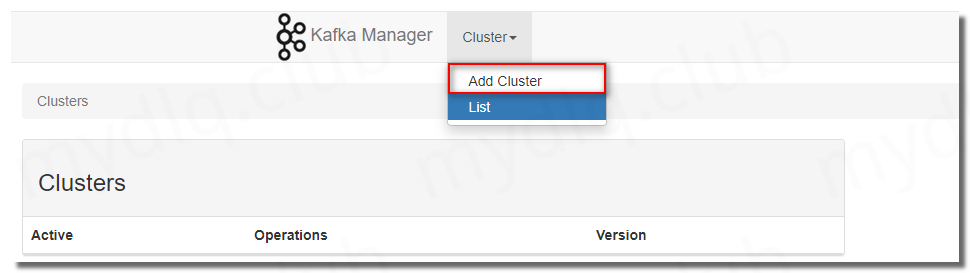
配置三个必填参数:
Cluster Name:自定义一个名称,任意输入即可。
Zookeeper Hosts:输入 Zookeeper 地址,这里设置为 Zookeeper 服务名+端口。
Kafka Version:选择 kafka 版本。

配置完成后就可以看到新增了一条记录,点进去就可以查看相关集群信息。
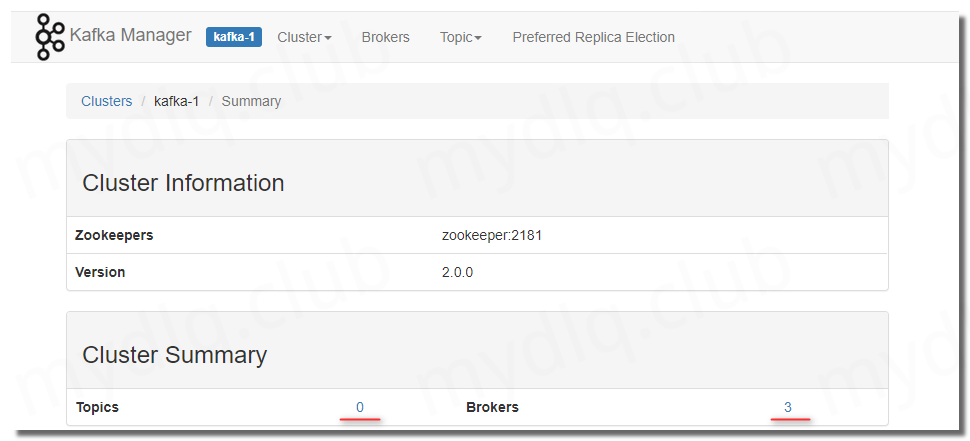

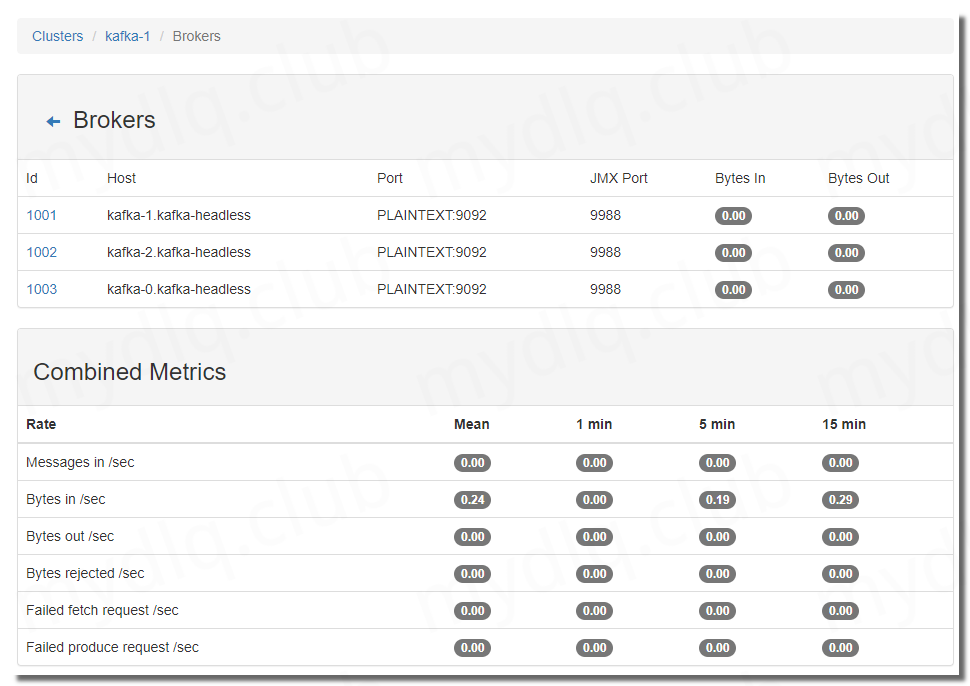
五、附录:镜像参数配置
Zookeeper 镜像可配置变量参数
镜像 github 地址:https://github.com/bitnami/bitnami-docker-zookeeper
| 参数名称 | 描述 |
|---|---|
| ZOO_PORT_NUMBER | Zookeeper客户端端口。默认值:2181 |
| ZOO_SERVER_ID | 集合中服务器的ID。默认值:1 |
| ZOO_TICK_TIME | ZooKeeper用于心跳的基本时间单位(以毫秒为单位)。默认值:2000 |
| ZOO_INIT_LIMIT | ZooKeeper用于限制仲裁中ZooKeeper服务器连接到领导者的时间长度。默认值:10 |
| ZOO_SYNC_LIMIT | 服务器与领导者的过时距离。默认值:5 |
| ZOO_MAX_CLIENT_CNXNS | 限制单个客户端可能对ZooKeeper集合的单个成员进行的并发连接数。默认60 |
| ZOO_SERVERS | 逗号,空格或冒号分隔的服务器列表。示例:zoo1:2888:3888,zoo2:2888:3888。没有默认值。 |
| ZOO_CLIENT_USER | 将使用Zookeeper客户端进行身份验证的用户。默认值:无默认值。 |
| ZOO_CLIENT_PASSWORD | 将使用Zookeeper客户端进行身份验证的密码。没有默认值。 |
| ZOO_SERVER_USERS | 逗号,分号或空格分隔的要创建的用户列表。示例:user1,user2,admin。没有默认值 |
| ZOO_SERVER_PASSWORDS | 逗号,半精或空格分隔的密码列表,在创建时分配给用户。示例:pass4user1,pass4user2,pass4admin。没有默认值 |
| ZOO_ENABLE_AUTH | 启用Zookeeper身份验证。它使用SASL / Digest-MD5。默认值:否 |
| ZOO_RECONFIG_ENABLED | 启用ZooKeeper动态重配置。默认值:否 |
| ZOO_HEAP_SIZE | Java堆选项(Xmx和XM)的大小(MB)。如果通过Xmx配置Xm,则忽略此env var JVMFLAGS。默认值:1024 |
| ZOO_LOG_LEVEL | Zookeeper日志级别。可用级别为:ALL,DEBUG,INFO,WARN,ERROR,FATAL,OFF,TRACE。默认值:INFO |
| ALLOW_ANONYMOUS_LOGIN | 如果设置为true,则允许接受来自未经身份验证的用户的连接。默认值:否 |
| JVMFLAGS | ZooKeeper进程的默认JVMFLAGS。没有默认值 |
Kafka 镜像可配置变量参数
镜像 github 地址:https://github.com/bitnami/bitnami-docker-kafka
| 参数名称 | 描述 |
|---|---|
| KAFKA_CFG_ZOOKEEPER_CONNECT | Zookeeper集群地址,例如”zookeeper:2181” |
| KAFKA_PORT_NUMBER | Kafka端口,例如”9092” |
| ALLOW_PLAINTEXT_LISTENER | 是否启用Plaintext侦听器,默认”false” |
| KAFKA_CFG_LISTENERS | Kafka 监听列表,broker对外提供服务时绑定的IP和端口 |
| KAFKA_CFG_ADVERTISED_LISTENERS | 给客户端用的发布至zookeeper的监听,broker 会上送此地址到zookeeper,zookeeper会将此地址提供给消费者,消费者根据此地址获取消息。 |
| KAFKA_HEAP_OPTS | Java JVM堆内存大小配置,例如”-Xmx512m -Xms512m” |
| KAFKA_CFG_LOGS_DIRS | Kafka 日志存储目录 |
| JMX_PORT | JMX端口配置,设置此参数才能开启JMX,例如设置为”9988” |
| KAFKA_CFG_SSL_ENDPOINT_IDENTIFICATION_ALGORITHM | 是否启用基于主机名的认证认证,例如想开启可以设置为”https” |
| KAFKA_CFG_BROKER_ID | Broker ID值,每个节点值都唯一。默认为”-1”,自动生成BrokerId |
| KAFKA_CFG_DELETE_TOPIC_ENABLE | 是否允许删除Topic,默认”false” |
| KAFKA_CFG_LOG_FLUSH_INTERVAL_MESSAGES | 此项配置指定时间间隔,强制进行fsync日志,默认”10000” |
| KAFKA_CFG_LOG_FLUSH_INTERVAL_MS | 此项配置用来置顶强制进行fsync日志到磁盘的时间间隔”1000” |
| KAFKA_CFG_LOG_RETENTION_BYTES | 每个Topic下每个Partition保存数据的总量,超过限制都会删除一个段文件,默认”1073741824” |
| KAFKA_CFG_LOG_RETENTION_CHECK_INTERVALS_MS | 检查日志分段文件的间隔时间,以确定是否文件属性是否到达删除要求,默认”300000” |
| KAFKA_CFG_LOG_RETENTION_HOURS | 每个日志文件删除之前保存的时间,默认数据保存时间对所有topic都一样,默认”168” |
| KAFKA_CFG_LOG_MESSAGE_FORMAT_VERSION | 指定broker将用于将消息添加到日志文件的消息格式版本 |
| KAFKA_CFG_MAX_MESSAGE_BYTES | Kafka允许的最大记录批大小。默认”1000000” |
| KAFKA_CFG_SEGMENT_BYTES | 日志段文件的最大大小。当达到这个大小时,将创建一个新的日志段。默认”1073741824” |
| KAFKA_CFG_DEFAULT_REPLICATION_FACTOR | 对replica的数目进行配置,默认值为”1”,表示不对topic进行备份。如果配置为2,表示除了leader节点,对于topic里的每一个partition,都会有一个额外的备份。 |
| KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR | Topic的offset的备份份数。建议设置更高的数字保证更高的可用性 |
| KAFKA_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR | 事务Topic的复制因子(设置得更高以确保可用性) |
| KAFKA_CFG_TRANSACTION_STATE_LOG_MIN_ISR | 事务Topic的副本数 |
| KAFKA_CFG_NUM_IO_THREADS | 用来处理请求的I/O线程的数目 |
| KAFKA_CFG_NUM_NETWORK_THREADS | 用来处理网络请求的网络线程数目 |
| KAFKA_CFG_NUM_PARTITIONS | 每个主题的日志分区的默认数量 |
| KAFKA_CFG_NUM_RECOVERY_THREADS_PER_DATA_DIR | 每个数据目录中的线程数,用于在启动时日志恢复,并在关闭时刷新。默认”1” |
| KAFKA_CFG_SOCKET_RECEIVE_BUFFER_BYTES | SO_RCVBUFF缓存大小,server进行socket连接时所用 |
| KAFKA_CFG_SOCKET_REQUEST_MAX_BYTES | 允许的最大请求尺寸,这将避免server溢出,它应该小于Java heap size,默认”104857600” |
| KAFKA_CFG_SOCKET_SEND_BUFFER_BYTES | Kafka追加消息的最大尺寸 |
| KAFKA_CFG_ZOOKEEPER_CONNECT_TIMEOUT_MS | 连接到zookeeper的超时时间(ms) |