PostgreSQL中的位图索引扫描(bitmap index scan)
从MySQL的MRR开始
开始之前,先从MySQL入手,看一下MySQL中的MRR机制原理,也就是Multi-Range Read。
MySQL中在按照非聚集索引的范围查找且需要回表的情况下,比如select * from t where c2>100 and c2<200;c2为非聚集索引。
如果直接根据非聚集索引(二级索引)键中的聚集索引键去回表,会产生大量的随机性IO读取(图1)。
为了避免频繁的回表造成的随机IO,读取完非聚集索引上符合条件的key值之后,对key值对应的聚集索引键(图2的rowid)排序,然后根据排序后的聚集索引键顺序地回表,从而避免大量的随机性IO。
因为MySQL的Innodb表都是聚集表,那么图2中的rowid排序后,是顺序性的映射到聚集索引的page,从而避回表过程中的随机性IO。
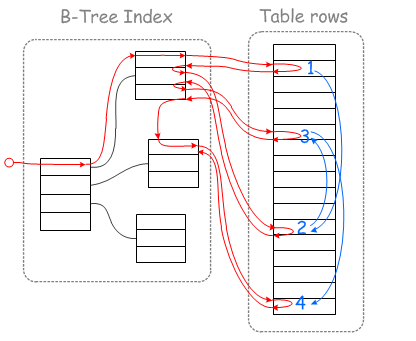 (图1)
(图1) 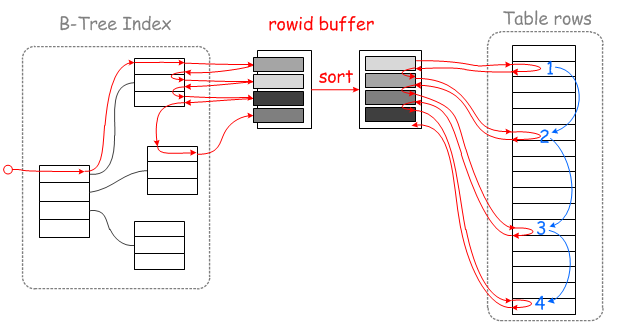 (图2)
(图2)
以上原理清楚后,继续引申出来另外一个经典的问题:
MySQL中的Innodb总是聚集索引表,或者SqlServer中的聚集表,非聚集索引为什么要拿聚集索引键(而非物理地址)作为其行指针?
对于聚集表,表中数据的物理位置因为需要保证按聚集索引建有序,同时意味着其真正的物理的rowid可能会发生变化(比如聚集索引非线性写入的时候,会导致叶分裂,页分裂会导致原始记录的物理位置变化),此时非聚集索引的行指针rowid也要做修改,这样会导致聚集表中的数据发生物理位置变化的时候,非聚集索引也要做相应的变化,如果非聚集索引用对应的聚集索引键做指针的话,就不会发生该问题。
由以上两个问题做铺垫,来看看Postgresql中如何处理类似的问题。
Postgresql中的位图扫描(bitmap scan)
如果遇到类似于上述的查询(select * from t where c2>100 and c2<200;c2为非聚集索引的)情况下,查询结果是一个范围,那么Postgresql在回表的过程中,如何避免类似于上述图1中的随机性IO?
先弄清楚Postgresql的数据存储特点,Postgresql表的数据都是以堆表(heap)的形式存储的,因此Postgresql中不存在所谓的聚集索引,同时意味着其记录在物理结构上可以是无序存储,不会产生所谓的页分裂(page split)。
那么Postgresql中的行指针,这里称作rowid,正常情况是不会因为新数据的写入导致类似于MySQL或者sqlserver中的页拆分(page split)。
然后再说Postgresql的bitmap scan,bitmap scan的作用就是通过建立位图的方式,将回表过程中对标访问随机性IO的转换为顺行性行为,从而减少查询过程中IO的消耗。
先从一个非常简单的demo入手,如下查询,是一个典型的根据非聚集索引且需要回表的查询,满足以上的条件。
可以看到在对idx_c5上执行了一个Bitmap Index Scan,由于Bitmap Index Scan记录的是符合条件的记录所在的block,而非记录的指针,通过类似于Oracle位图索引的检索模式进行数据的筛选,然后对这些位图信息指向的block排序后再进行回表(查询),Bitmap Index Scan之后有一个Recheck Cond是因为解析block的时候需要Recheck 。
参考这里:The bitmap is one bit per heap page. The bitmap index scan sets the bits based on the heap page address that the index entry points to.
最后,bitmap scan之后,对表的访问,总是通过bitmap Heap Scan完成。也就是执行计划的第一行。
这里的bitmap scan与上文中提到的MySQL中的MRR的思路算是一致的,都是通过中间一个缓存来避免随机性的IO访问,提升查询效率。
与基于聚集索引的总是从B+树的根节点通过二分法查找访问相比,对于postgresql中的这种直接基于物理Id的访问,从这一点上看,效率并不一定低。
bitmap scan的访问优化是基于代价考虑的,对于类似的查询,不总是一定走bitmap scan,如下,当访问的数据范围足够小的时候,可能不会走bitmap scan。
另外,bitmap scan的优化可以是基于不同字段或者不同筛选条件的,比如 where a>m and b>n(BitmapAndPath),亦或是where a>x or b>y(BitmapOrPath)这种访问方式,都可以通过bitmap scan来优化实现。
如果了解Oracle中的bitmap类似索引,加上这里的一个图例,应该比较容易理解bitmap生成机制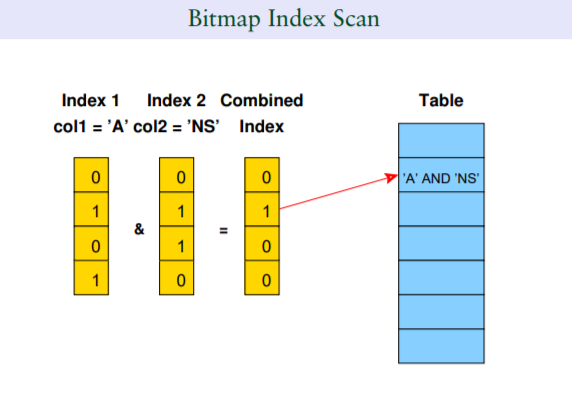
只不过笔者这里还有一个问题,因为postgresql中对行的update都是直接删除原始记录,然后新写入一条记录来实现的,只要这条记录的物理页面不变,那么非聚集索引的行指针就不变,如果这个记录的物理页面发生了变话,是不是索引的指针也会发生变化?
相关参数
正常情况下,是否用到bitmap scan优化,postgresql 优化器是可以选择出来一种最优的方式来执行的,但不保证总是可以生成最优化的执行计划,可以通过禁用bitmap scan或者 seqscan来尝试对比和调优。
任何优化都是一个系统工程,而不是一个单点工程,通过不同资源的消耗比例来提升整体性能,bitmap scan也并非完美无瑕,其优化理念是通过bitmap 的生成过程中增加内存和CPU字段消耗来减少IO消耗。
如果是高性能存储或者有充足的内存,并不一定总是发生物理IO,那么IO并不一定会是瓶颈,相反机械地去做bitmap的生成的话,反倒是一种浪费。
此时可以根据具体的IO能力,比如磁盘的随机读和顺序读代价参数,或者是禁用bitm scan等,来做整体上的优化方案。
参考
https://dba.stackexchange.com/questions/119386/understanding-bitmap-heap-scan-and-bitmap-index-scan
https://blog.csdn.net/weixin_33672400/article/details/89734245
https://www.cybertec-postgresql.com/en/postgresql-indexing-index-scan-vs-bitmap-scan-vs-sequential-scan-basics/
目录 返回
首页