大数据平台概念和架构
前言
今天为什么来写这个内容了,一是前些天有个非行业内的好朋友想了解下大数据相关概念的内容,搜了下网上平台相关的介绍,对于业内和业外的感觉都不太完善和直观。另外就是自己也想定时归纳下认知。所以今天特意描述下自己的拙见,也欢迎大家指点。
问题
在开始今天的描述前,这里我先提一个问题。假设双11马总让大家来计算下淘宝过去1小时购物车的点击次数,你打算怎么做了?我们一步步来看这个问题。
什么是大数据
首先既然是要获取购物车点击次数,那么我们首先得把用户的点击数据保存下来,对于淘宝来说双11数亿人1个小时数据,脑补下也是只能用海量(Volume) 形容吧。当然实际存储的肯定是更加多样的(Variety) 数据,比如马总又想单独看国内用户的点击,是不是又得记录用户信息相关数据。
接下来当我们存好数据后,是不是只要筛选出点击标签为购物车的记录汇总就行了。不过万亿级数据我们用一个台计算机来做,就算它真的能处理,计算出结果也不知道是何年何月了。那如何快速(Velocity) 计算统计出这个有价值(Value) 的数据,这就正是我们从事大数据要考虑的事了,因为老板还在那里等着了。
以上描述的4V也就是大数据的4大特征。其中Value的产出正是大数据的价值体现。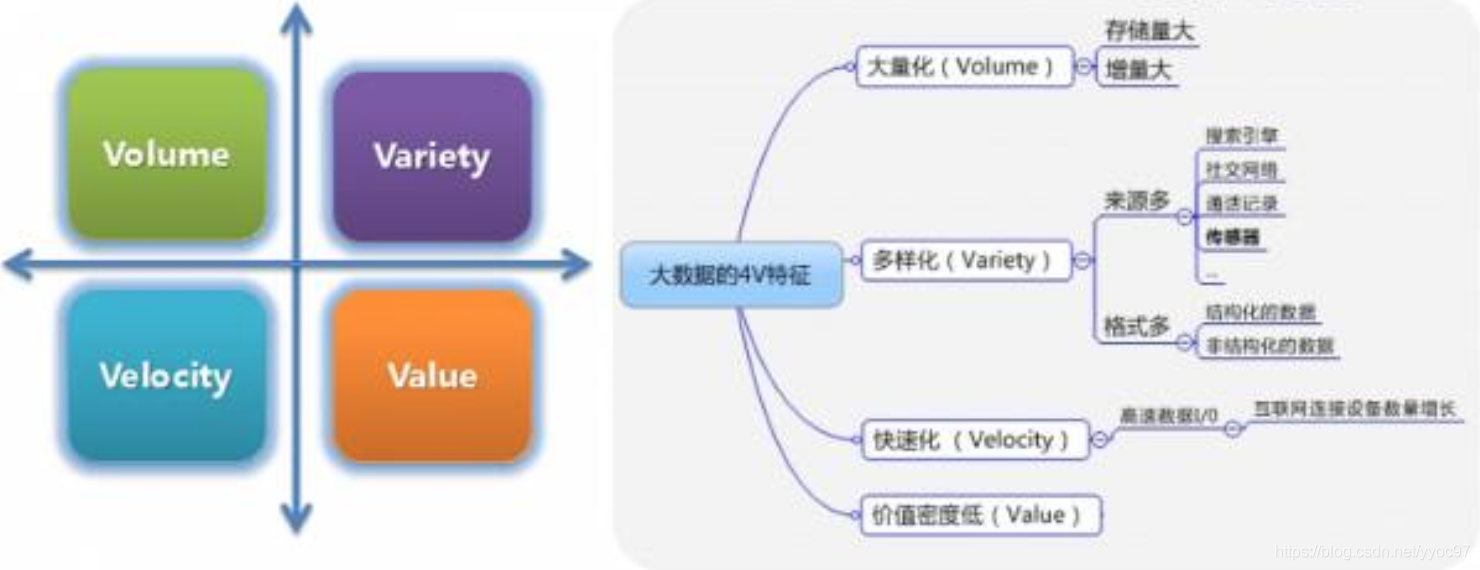
为什么需要数据平台
提供上述多样化、海量数据的存储能力,又提供强大、快速的计算能力。然后通过这两个能力得到我们所想要的价值Value,这个价值可以是直观的报表数据,可以网易云音乐根据大家喜好生成的每日推荐,也可以是对股票未来趋势预测等(如何你会的话记得联系我)。而这些能力真正的提供者,是多台计算机(之后都称节点)、多个应用组件共同的支持。
为保证这些能力能够正常施展,并在之后升级更强大的力量。就需要有个地方统一管理这些机器和组件。比如1000个节点组件需要修改一个配置,大家不能手动一个个修改吧,肯定是考虑通过一键配置的方式。平台另一个重要作用就是对整个集群进行监控管理,大家平时在网吧是不是偶尔听人说死机、蓝屏什么的。同样大规模集群中节点出问题也是常有的事。就需要系统有监控、报警的机制才能方便管理。
数据平台
整体模型
下图描述了数据平台简单结构。我会结合自己的理解做一些说明和补充。接下来描述的内容会更侧重技术范畴。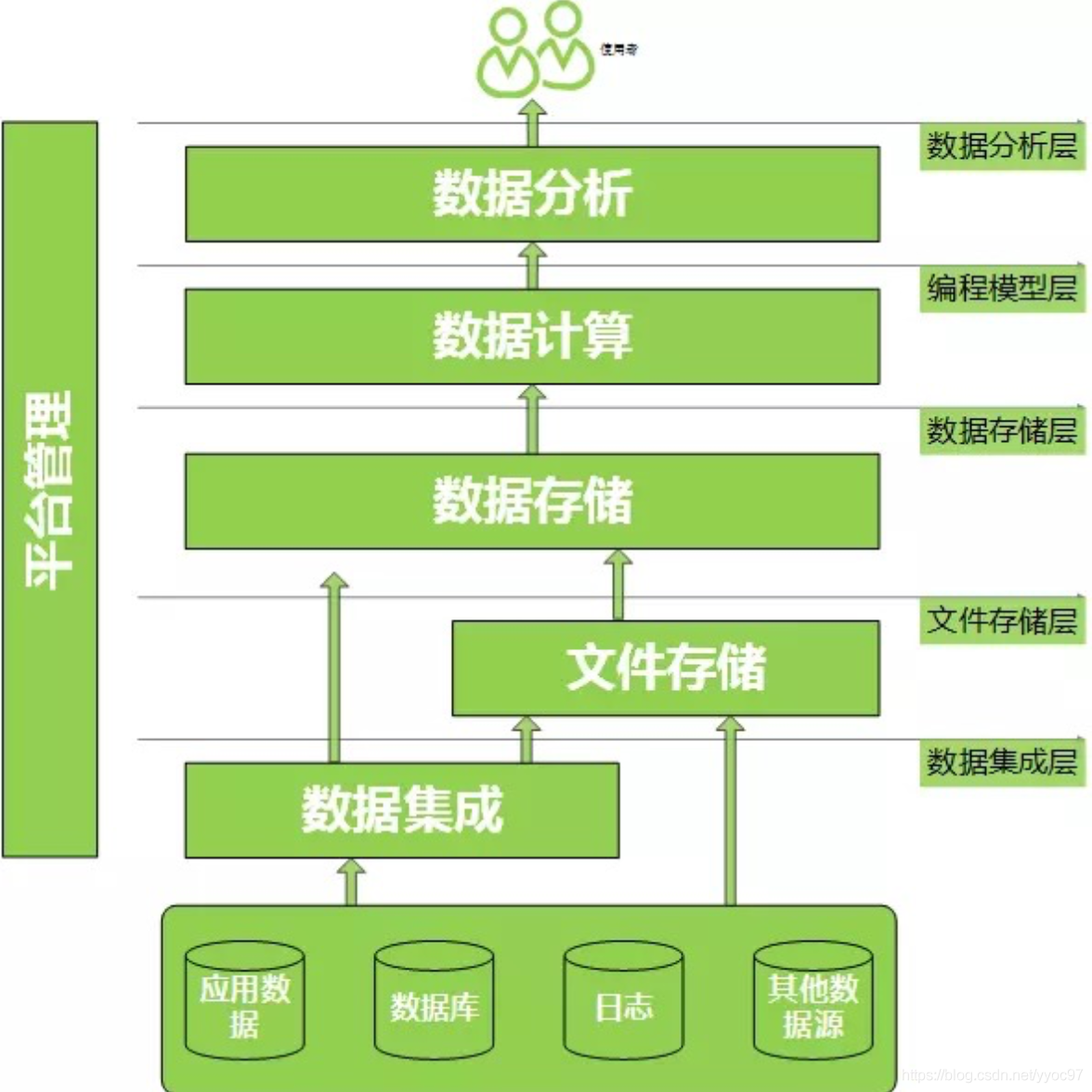
模块分析
数据源
如上图所示最下面的部分。观察仔细的话会发现它并没有纳入数据平台中,是的,严格来说这些丰富的数据源并非数据平台所管理的范畴。但这些底层数据确实是数据仓库中很重要的一环,所以数据平台虽然没有直接管理,通常情况会通过一系列的组件和方式同步到数仓中。
其中数据类型包括有RDBMS的结构化数据、JSON格式的半结构化数据、音频文件的非结构化数据等。数据集成
上面我们提到数据要同步到数据仓库中,那通过何种方式来进行,这就到了数据平台所管辖的范畴了。常用的非实时接入有Sqoop、DataX等组件,侧重实时处理的组件有JAVA NIO、消息队列(如Kafka、Pulsar等)、Flume等工具。这个环节也可以简单理解为数据传输。
集成的过程,也是数据平台开始收纳数据的开始,这个过程实现了平台和外部系统的解耦。至于数据内容可以是完全一致,也可以做初步的格式处理。比如同时多个系统数据流入,就可以通过简单处理实现数据格式的归一。文件存储
数据平台接收到多种类型的数据后,我们肯定就要考虑把他们安置好。那么现在市面上主流的分布式文件系统就有Hadoop的hdfs、新兴的clickhouse、专注时序的Druid、Amazon的s3,也有少部分公司使用kudu、Delta Lake等这些其他工具。(这里我们提到的存储介质限于元数据的接入、后续数据处理后会有更多不同特性工具)
而这些文件系统主要为我们做了什么了。第一就是管理元数据,因为我们海量数据肯定是要存在N台计算机的吧,没有管家我们怎么高效查找、存储数据了。第二个很重要的就是帮我们做数据的备份冗余。我们前面提到节点一多,那么集群机器故障的概率也就大大提升了。数据只有同时存在多个节点、才能更好的保障数据的完整性。数据计算
这个过程也常被称作Transform,也就是数据间的一些转换,包括机器学习相关的一些算法处理。我们常把一次完整计算叫做一个任务job。目前常见的计算引擎有spark、presto、impala、flink-sql等,实时处理框架有flink、spark streaming、storm等,预计算框架kylin,存储计算一体的clickhouse。这个阶段也是数据开发来实现各种业务的主要层级之一。结果落地
上图的数据分析层可以由结果落地和数据服务层来替代。通过上面计算出来的结果通常是我们可以直接或者间接使用的数据了,这类上层数据一般会要求有查询低延迟特性,甚至有高并发的场景。所以我们会根据场景和数据类型选取合适的存储介质,比如Hbase、Elasticsearch、Mysql、MongoDB、Redis等。为后续的数据服务提供更好的支持。数据服务
通常数据服务可以是数据组的同学来负责,也可以是后台的同事来支持。主要是搜索落地的数据,提供相关API给到外部系统。统一资源调度
这个模块没有在图中画出,理论上它是跨越数据集成至结果落地的。我们数据集成有些是实时、有些是离线。数据计算有些是5分钟、有些是每天执行。而任务job之间也可能存在多种依赖,成千上万个任务如果让人手动维护肯定是不现实的。所以会专门的工具Azkaban、Airflow、Oozie等来管理这些任务。这里也能做一层数据权限控制。可视化平台
可视化界面可以更方面的管理集群、比如增删节点和组件,统一修改配置等。另外也能更直观监控集群状态,包括节点状态、cpu、内存、网络情况等。如下图是Ambari的Dashborad。这块也涵盖了运维不少内容。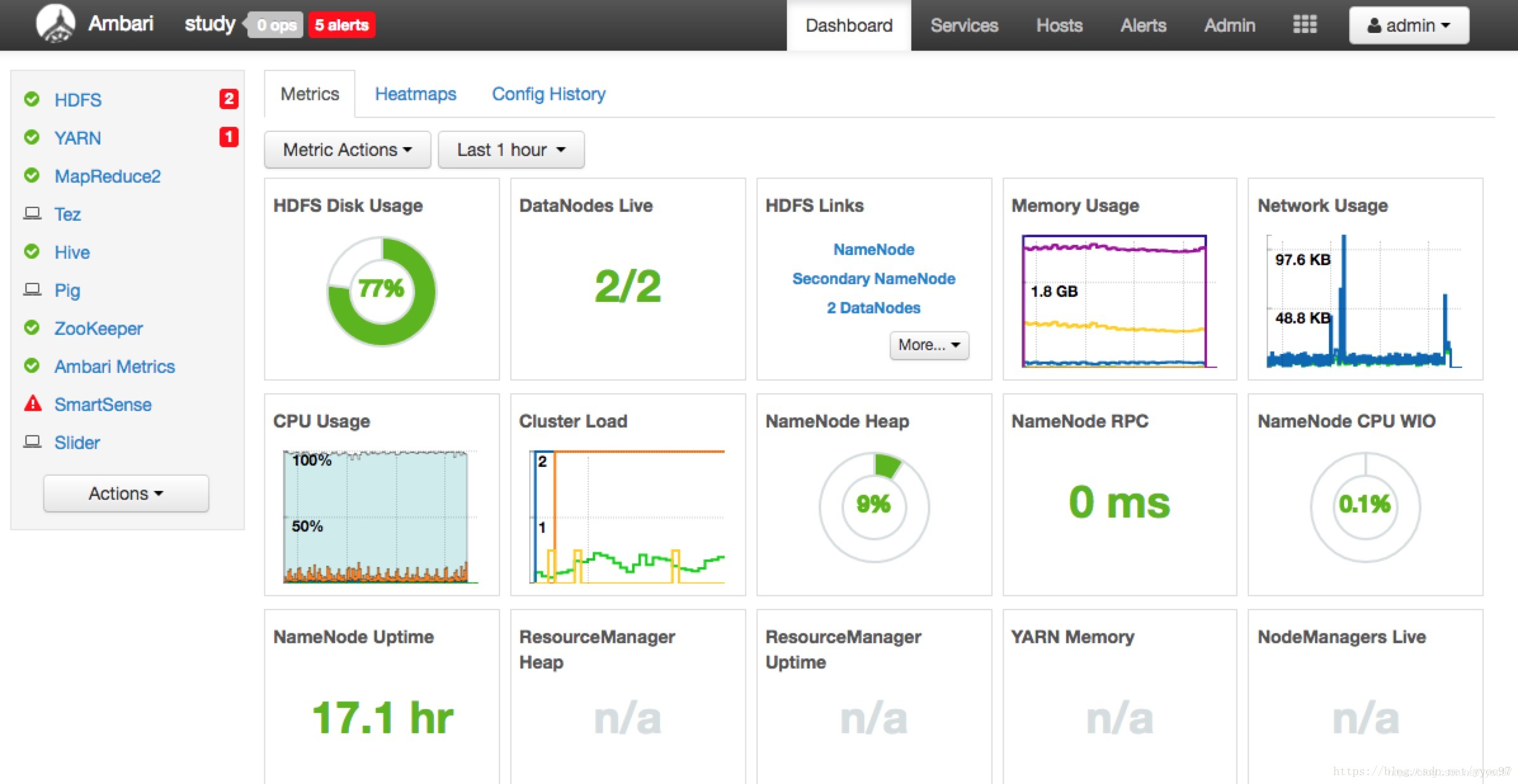
冰川之下
上述提到的层级是我们能直观感受到的链路,除此之外撑起数据平台还有常被大家忽略的冰山之下的模块。包括数据质量校验、元数据管理、多用户管理等。
另外个人视野有限,大家可以在github awesome big-data 里,看看各个层级当下最主流和有潜力的框架。
主流平台
CDH
HDP
上述Ambari就是其产品。目前已和CDH合并、预计在2021年会推出CDP的新产品。
目录 返回
首页