1.前置准备
若之前未了解过ElasticSearch的安装,在安装集群版之前,建议先了解一下单机版创建。集群版无非就是拷贝了几套单机版的安装包,配置稍加改。
单机版安装详细教程以及安装过程容易遇到的问题
详见:ElasticSearch单机版安装
集群环境准备
| IP | 监听端口 | 主机名 | 系统 | es实例名称 | es版本 |
|---|
| 192.168.3.21 | 9201/9301 | elastic | CentOS 7 | node-a | 7.4.0 |
| 192.168.3.22 | 9201/9301 | elastic | CentOS 7 | node-b | 7.4.0 |
| 192.168.3.23 | 9201/9301 | elastic | CentOS 7 | node-c | 7.4.0 |
2.下载安装包
官方下载地址:传送门
历史版本下载:传送门
本文以7.4.0为例: 7.4.0下载地址
命令下载
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.0-linux-x86_64.tar.gz
3.创建集群目录
每一台服务器都需要操作。
#创建集群存储主目录
mkdir /usr/local/elasticsearch-cluster
#解压到集群目录下
tar zxvf elasticsearch-7.4.0-linux-x86_64.tar.gz -C /usr/local/elasticsearch-cluster
#切换到目录下
cd /usr/local/elasticsearch-cluster
#修改解压后的文件名为 elasticsearch-a,(为了方便区分根据节点名)
mv elasticsearch-7.4.0 elasticsearch-a
# 创建数据存储目录
mkdir -p /usr/local/elasticsearch-cluster/elasticsearch-a/data
# 创建日志存储目录
mkdir -p /usr/local/elasticsearch-cluster/elasticsearch-a/logs
注:这里为了区分是es的多个节点,
第1台的目录文件夹为 elasticsearch-a
第2台的目录文件夹为 elasticsearch-b
第3台的目录文件夹为 elasticsearch-c
注:安装包不用下载多次可以使用SCP命令传输到另外两台示例:
scp -r elasticsearch-7.4.0-linux-x86_64.tar.gz root@192.168.3.23:/usr/local
4.节点node-a配置
进入到es安装目录下的config文件夹中,修改elasticsearch.yml 文件
#配置es的集群名称,同一个集群中的多个节点使用相同的标识
#如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
cluster.name: my-es-cluster
#节点名称
node.name: node-a
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#数据存储路径
path.data: /usr/local/elasticsearch-cluster/elasticsearch-a/data
#日志存储路径
path.logs: /usr/local/elasticsearch-cluster/elasticsearch-a/logs
#节点所绑定的IP地址,并且该节点会被通知到集群中的其他节点
#通过指定相同网段的其他节点会加入该集群中 0.0.0.0任意IP都可以访问elasticsearch
network.host: 192.168.3.21
#对外提供服务的http端口,默认为9200
http.port: 9201
#内部节点之间沟通端口
transport.tcp.port: 9301
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["192.168.3.21:9301","192.168.3.22:9301","192.168.3.23:9301"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-a", "node-b","node-c"]
#ES默认开启了内存地址锁定,为了避免内存交换提高性能。但是Centos6不支持SecComp功能,启动会报错,所以需要将其设置为false
bootstrap.memory_lock: false
# 是否支持跨域
http.cors.enabled: true
# *表示支持所有域名
http.cors.allow-origin: "*"
5.节点node-b配置
#配置es的集群名称,同一个集群中的多个节点使用相同的标识
#如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
cluster.name: my-es-cluster
#节点名称
node.name: node-b
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#数据存储路径
path.data: /usr/local/elasticsearch-cluster/elasticsearch-b/data
#日志存储路径
path.logs: /usr/local/elasticsearch-cluster/elasticsearch-b/logs
#节点所绑定的IP地址,并且该节点会被通知到集群中的其他节点
#通过指定相同网段的其他节点会加入该集群中 0.0.0.0任意IP都可以访问elasticsearch
network.host: 192.168.3.22
#对外提供服务的http端口,默认为9200
http.port: 9201
#内部节点之间沟通端口
transport.tcp.port: 9301
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["192.168.3.21:9301","192.168.3.22:9301","192.168.3.23:9301"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-a", "node-b","node-c"]
#ES默认开启了内存地址锁定,为了避免内存交换提高性能。但是Centos6不支持SecComp功能,启动会报错,所以需要将其设置为false
bootstrap.memory_lock: false
# 是否支持跨域
http.cors.enabled: true
# *表示支持所有域名
http.cors.allow-origin: "*"
6.节点node-c配置
#配置es的集群名称,同一个集群中的多个节点使用相同的标识
#如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
cluster.name: my-es-cluster
#节点名称
node.name: node-c
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#数据存储路径
path.data: /usr/local/elasticsearch-cluster/elasticsearch-c/data
#日志存储路径
path.logs: /usr/local/elasticsearch-cluster/elasticsearch-c/logs
#节点所绑定的IP地址,并且该节点会被通知到集群中的其他节点
#通过指定相同网段的其他节点会加入该集群中 0.0.0.0任意IP都可以访问elasticsearch
network.host: 192.168.3.23
#对外提供服务的http端口,默认为9200
http.port: 9201
#内部节点之间沟通端口
transport.tcp.port: 9301
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["192.168.3.21:9301","192.168.3.22:9301","192.168.3.23:9301"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-a", "node-b","node-c"]
#ES默认开启了内存地址锁定,为了避免内存交换提高性能。但是Centos6不支持SecComp功能,启动会报错,所以需要将其设置为false
bootstrap.memory_lock: false
# 是否支持跨域
http.cors.enabled: true
# *表示支持所有域名
http.cors.allow-origin: "*"
7.启动用户与赋权
由于ES限制不能使用root 用户启动,与单机版教程一致
这里与单机版安装时使用了相同的elasticsearch用户
创建用户:elasticsearch
adduser elasticsearch
设置用户密码,需要输入两次
passwd elasticsearch
赋权
注:由于是伪集群,都在同一台服务器,所以3个节点目录都需要赋权,多台服务器的话,都需要操作
chown -R elasticsearch /usr/local/elasticsearch-cluster/elasticsearch-a
8.启动集群环境
启动之前,建议针对实际使用场景,设置合适的JVM内存,详见文末附录
#切换到用户
su elasticsearch
#切换到a节点
cd /usr/local/elasticsearch-cluster/elasticsearch-a/bin
#控制台启动命令
./elasticsearch
#后台启动命令
#./elasticsearch -d
同启动a节点一致,分别再次启动 b节点、C节点
注:启动小妙招,先不要着急后台启动,直接使用 ./elasticsearch 启动看一下是否报错。若出现报错,可以到前一篇文章单机版ES搭建中找下,列举出来了常见的几种启动问题。
注:开机自启设置方式,详见单机版搭建过程
9.查看集群
9.1查看集群状态
可以通过访问(任选一个)浏览器输入,查看集群节点:[http://IP:9201/_cat/nodes?v]

命令查看
注:若已经设置了账密则需要输入账密
# curl -u 用户名:密码 -XGET 'http://IP:9201/_cat/nodes?v'
curl -u elastic:1234567 -XGET 'http://localhost:9201/_cat/nodes?v'12

可以通过访问(任选一个)查看集群状态:[http://IP:9201/_cluster/stats?pretty]
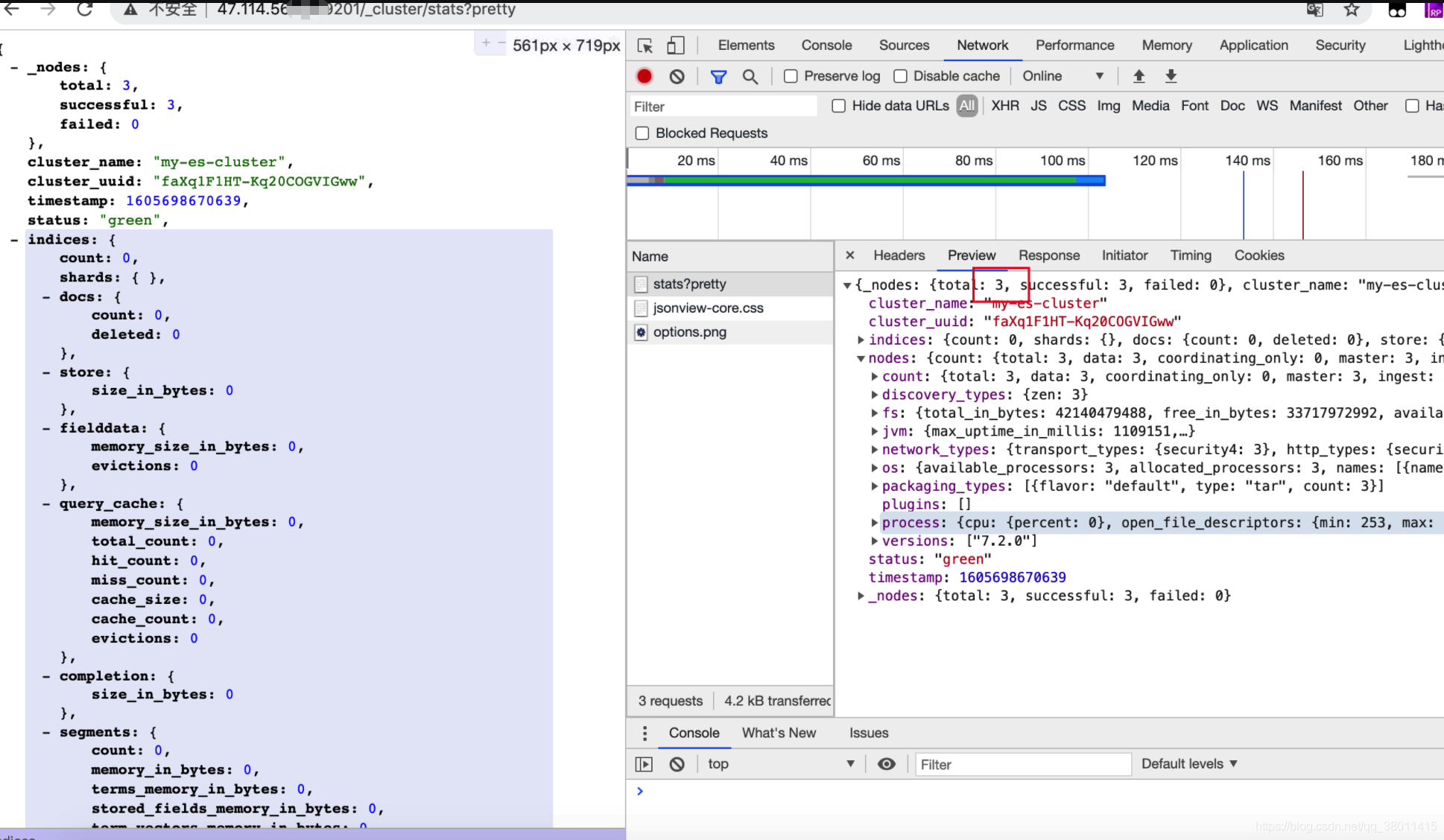
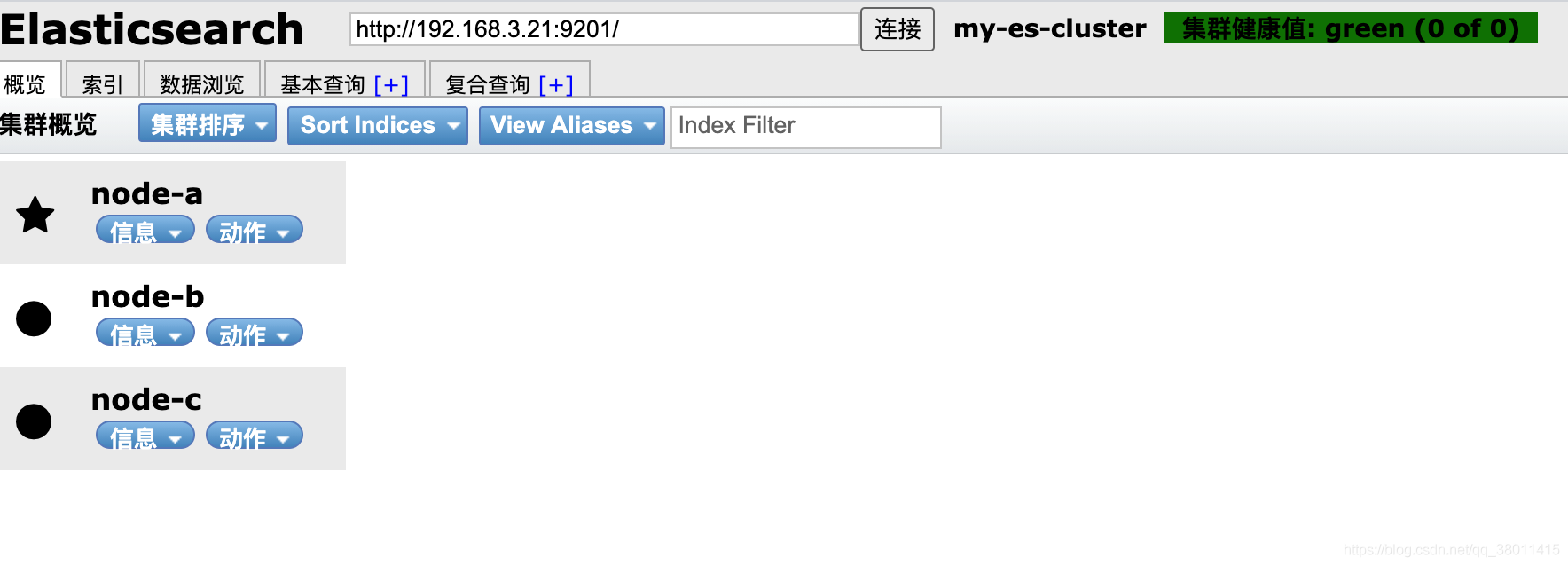
9.2ElasticSearch-Head可视化插件查看
也可以使用head查看集群信息如下,说明搭建成功
附录:
1.修改JVM参数
官网也介绍了如何 设置堆大小。
默认情况,ES 告诉 JVM 使用一个最小和最大都为 1GB 的堆。但是到了生产环境,这个配置就比较重要了,确保 ES 有足够堆空间可用。
ES 使用 Xms(minimum heap size) 和 Xmx(maxmimum heap size) 设置堆大小。你应该将这两个值设为同样的大小。
Xms 和 Xmx 不能大于你物理机内存的 50%。
设置的示例:
切换到 conf/
打开 vim jvm.options

建议:可用 RAM 的 50%,最多最大 30GB RAM,以避免垃圾回收。
官方文档最大指 32 GB,官网JVM最大值设置:传送门