Spark2.4.8集成并读写hive表数据
Spark2.4.8集成并读写hive表数据
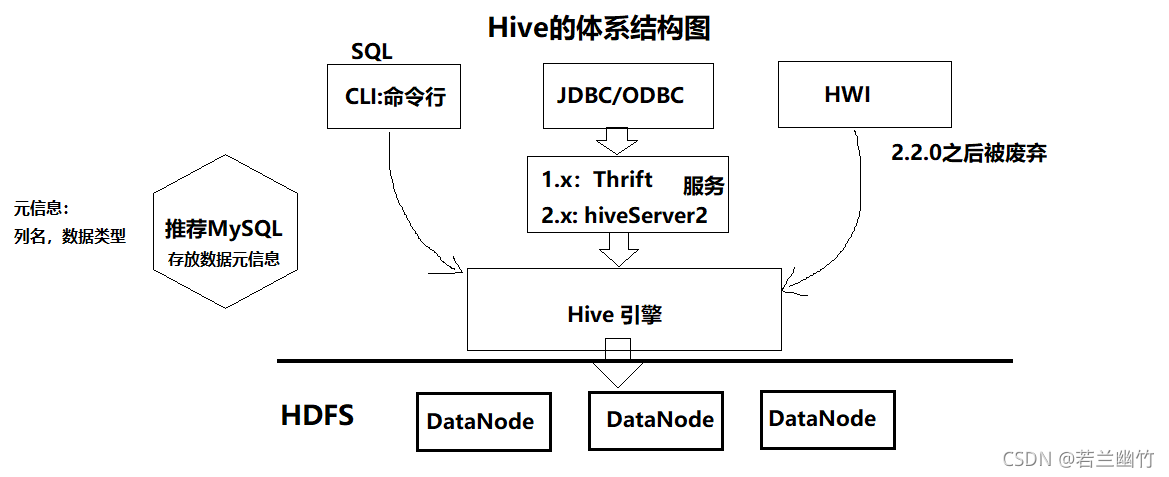
一、Hive简介
Apache Hive™数据仓库软件通过SQL实现对分布式存储中的大型数据集的读写和管理。结构可以投射到存储中的数据上。Hive提供命令行工具和JDBC驱动程序连接用户。
本质上:Hive是一个翻译器,借助Hive引擎将SQL语句转成MR程序且构建于HDFS上的一个数据仓库。
它支持SQL(SQL99的一个子集),可以写SQL语句来分析海量的数据
二、Hive安装
下载Hive(下载地址),并上传至虚拟机上
解压安装
tar -zxvf apache-hive-2.3.0-bin.tar.gz -C ~/training/
设置环境变量
export HIVE_HOME=/training/apache-hive-2.3.0-binexport PATH=$PATH:$HIVE_HOME/bin
让环境变量生效
source ~/.bash_profile
三、Hive的本地模式和远程模式配置
1. 本地模式配置
安装MySQL
需要借助MySQL来存储metadata元数据,所以需要安装mysql。MySQL可以安装在与hive所在的同一台虚拟机上,也可以安装在Windows上或者其他的服务器上,你喜欢哪种选择哪种。如果你已经有了MySQL数据库,那直接配置即可。如果没有,则需要先安装MySQL数据库。
以下为在centos7上安装的MySQL的过程,仅供大家参考:
先获取临时密码:
grep 'temporary password' /var/log/mysqld.log登录到mysql中去修改:
2.1 命令行登录:
mysql -uroot -p123456
2.2 命令行修改密码:
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Sjm_123456';删除掉centos7自带的mariadb相关库
yum remove mysql-libs配置MySQLyum源:
(0) 在虚拟机上先查看MySQL的yum源:yum repolist all | grep mysql(1)下载并安装mysql的yum源:
地址:
https://dev.mysql.com/downloads/repo/yum/
版本:mysql80-community-release-el7-3.noarch.rpm
安装:rpm -Uvh mysql80-community-release-el7-3.noarch.rpm(2)修改MySQL的yum源文件:
编辑:vi /etc/yum.repos.d/mysql-community.repo,添加如下内容:# 我们使用MySQL57版本,其他版本禁用即可 # Enable to use MySQL 5.7 [mysql57-community] name=MySQL 5.7 Community Server baseurl=http://repo.mysql.com/yum/mysql-5.7-community/el/6/$basearch/ enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
MySQL的yum源配置如下图所示:
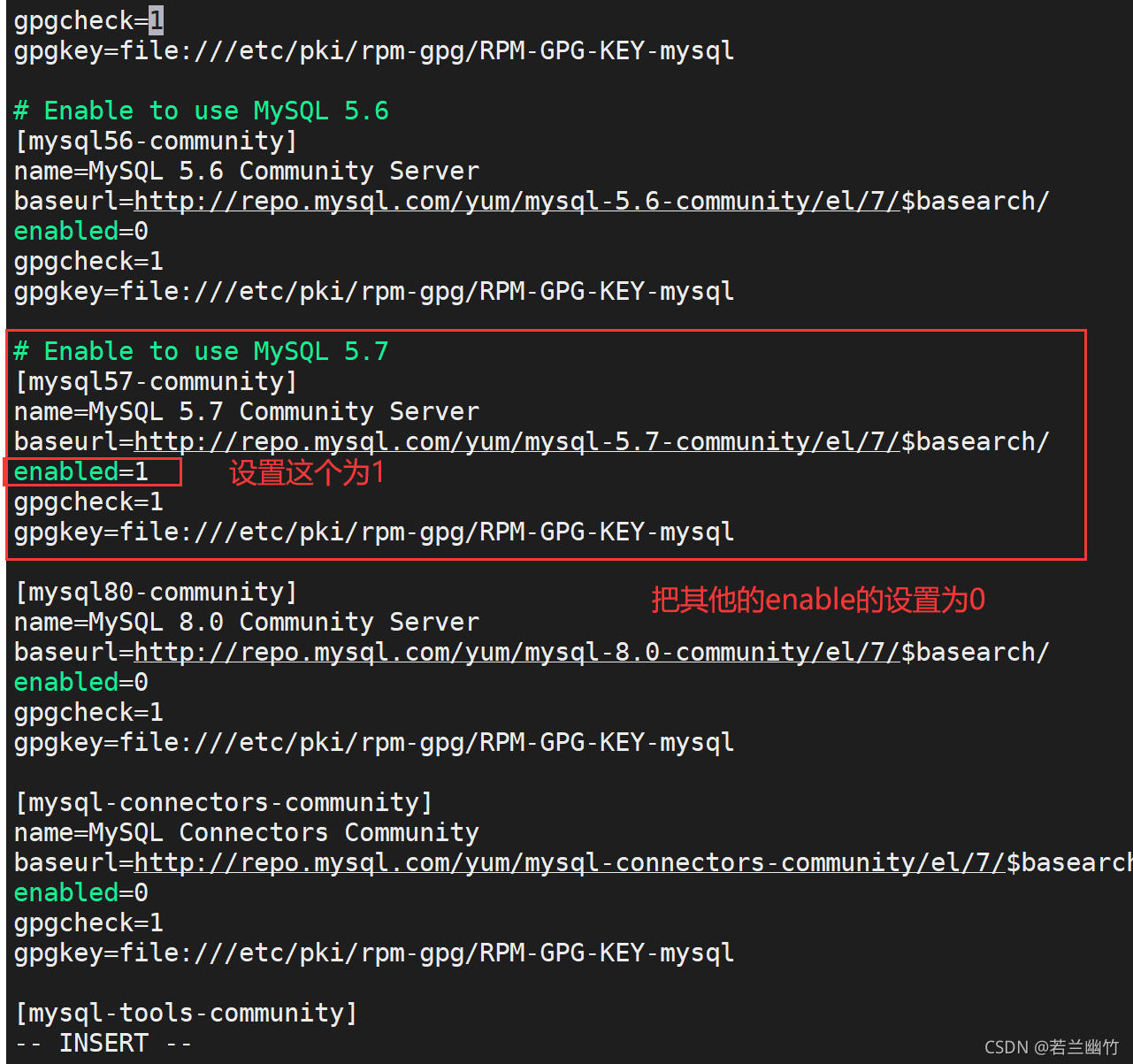
(3)再次确认下,当前的yum源是不是mysql57:
yum repolist enabled | grep mysql

(4)安装MySQL:
yum -y install mysql-community-server(5)启动MySQL服务器:
systemctl start mysqld.service(6)查看MySQL启动状态:
systemctl status mysqld.service(7)修改root默认密码:
配置Hive数据库
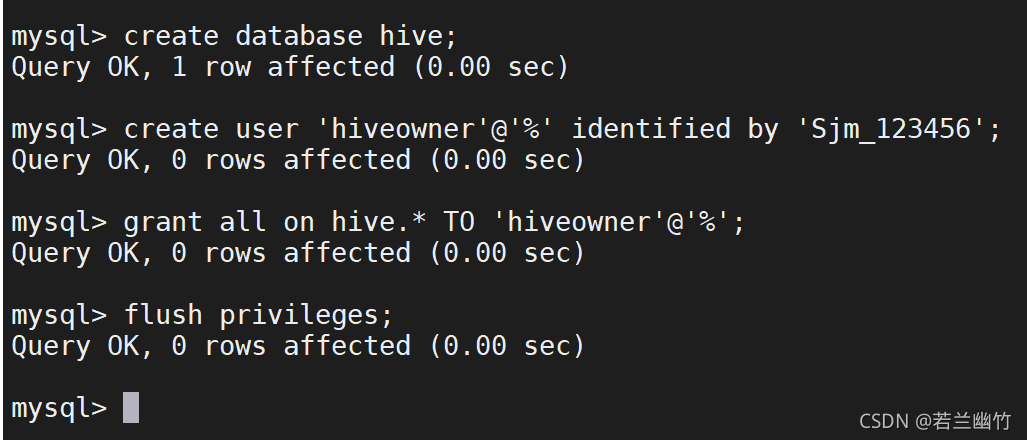
命令行登录到MySQL中,安装如下步骤执行即可:
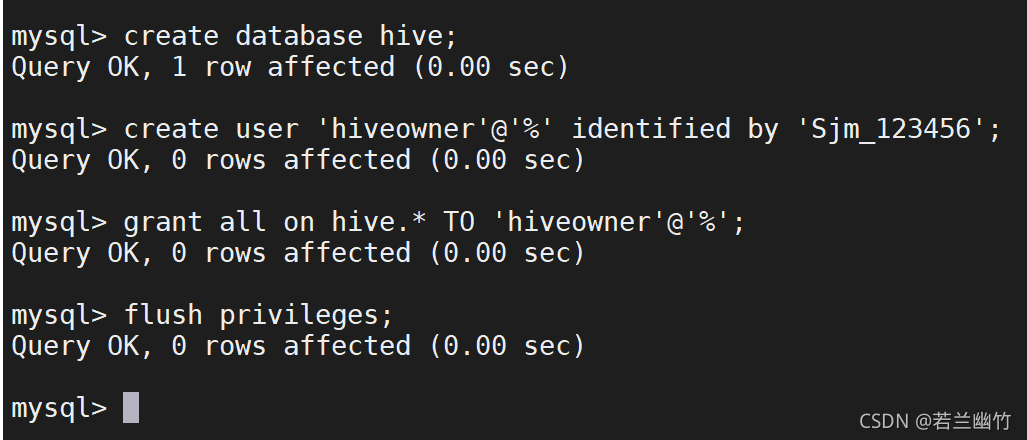
创建一个新的数据库:create database hive;
创建一个新的用户:
create user ‘hiveowner’@’%’ identified by ‘Sjm_123456’;
给该用户授权
grant all on hive.* TO ‘hiveowner’@’%’;
grant all on hive.* TO ‘hiveowner’@‘localhost’ identified by ‘Sjm_123456’;
flush privileges;
在hive安装目录下的conf下创建hive-site.xml文件,并添加如下内容:
<?xml version="1.0" encoding="UTF-8" standalone="no"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?useSSL=false</value></property><property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value></property><property> <name>javax.jdo.option.ConnectionUserName</name> <value>hiveowner</value></property><property> <name>javax.jdo.option.ConnectionPassword</name> <value>Sjm_123456</value></property></configuration>
上传mysql驱动包到/training/apache-hive-2.3.0-bin/lib目录下,
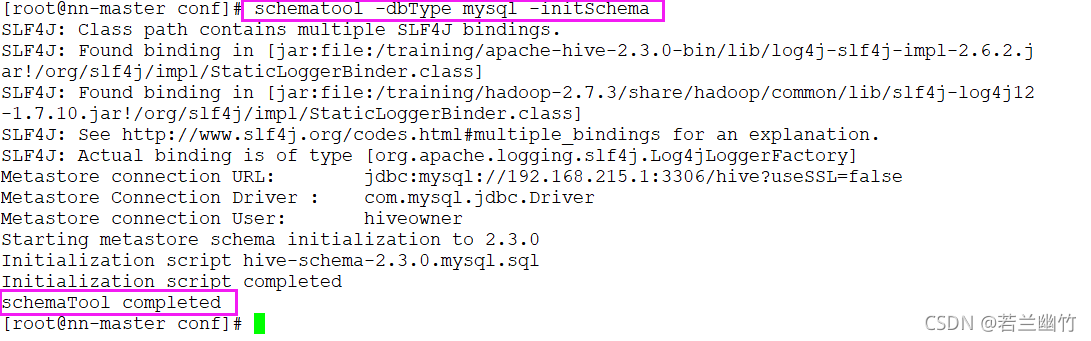
注意一定要使用高版本的MySQL驱动(5.1.43以上的版本)初始化Hive
schematool -dbType mysql -initSchema
执行成功后的日志如下:
验证Hive是否安装成功,
在虚拟机命令行中,执行:hive,回车即可,看到如下类似信息说明安装配置ok了:
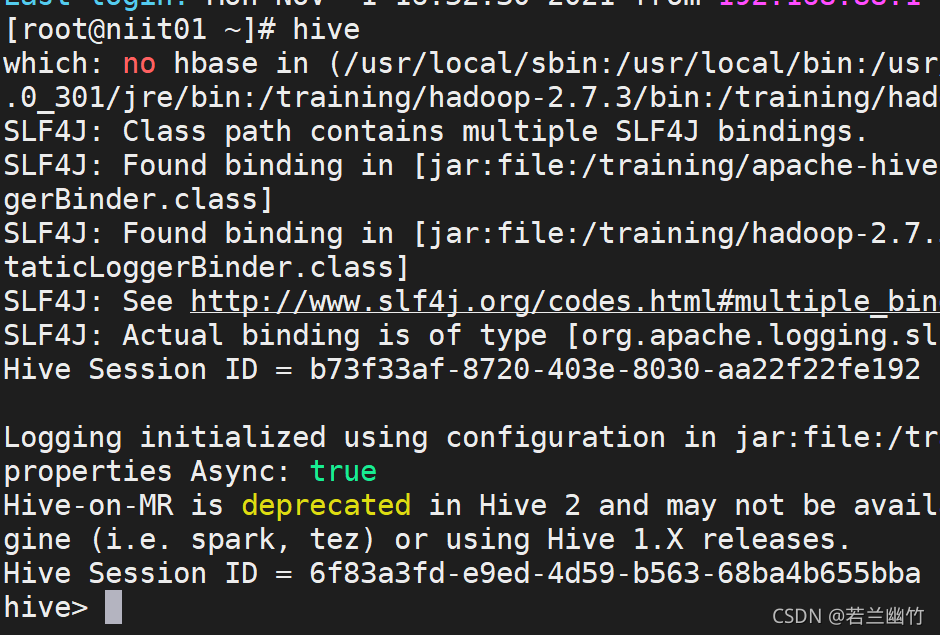
2. 远程模式
特点:
元数据信息存储在远程的MySQL数据库中
注意使用高版本的MySQL驱动(5.1.43以上的版本)
安装:
如果你windows上已经安装了mysql,只需如下操作:
创建一个新的数据库:create database hive;
创建一个新的用户:
create user ‘hiveowner’@’%’ identified by ‘Sjm_123456’; —这里是你MySQL root用户密码
给该用户授权
grant all on hive.* TO ‘hiveowner’@’%’;
flush privileges;
只需在hive-site.xml中更改下url等相关信息即可
四、创建Hive表
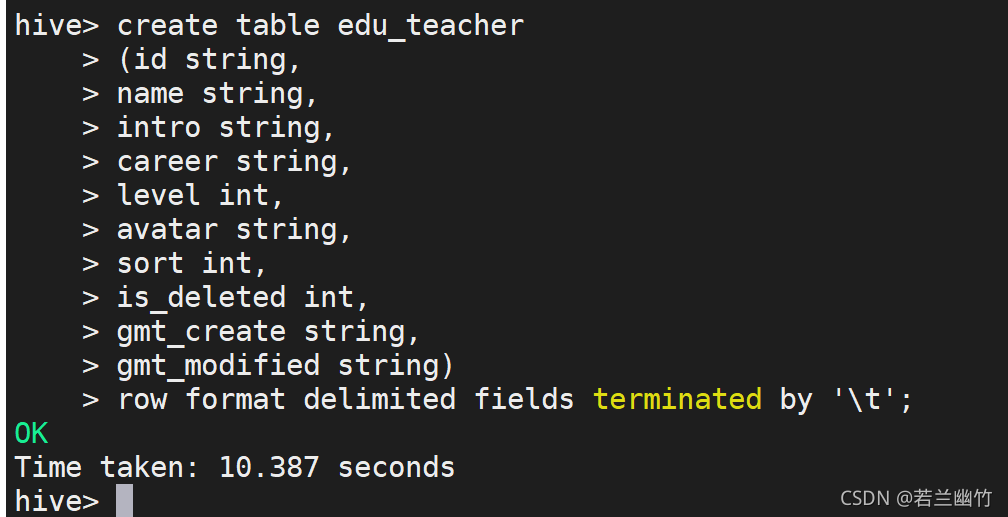
创建Hive的内部表edu_teacher,建表语句如下:
create table edu_teacher(id string,name string,intro string,career string,level int,avatar string,sort int,is_deleted int,gmt_create string,gmt_modified string)row format delimited fields terminated by '\t';
创建表如下图所示:
在hive的命令行中导入edu_teacher.csv数据到edu_teacher表中,执行如下命令:
load data local inpath '/root/edu_teacher.csv' into table edu_teacher;
注意:这里是将本地的文件导入hive表中
如下所示:

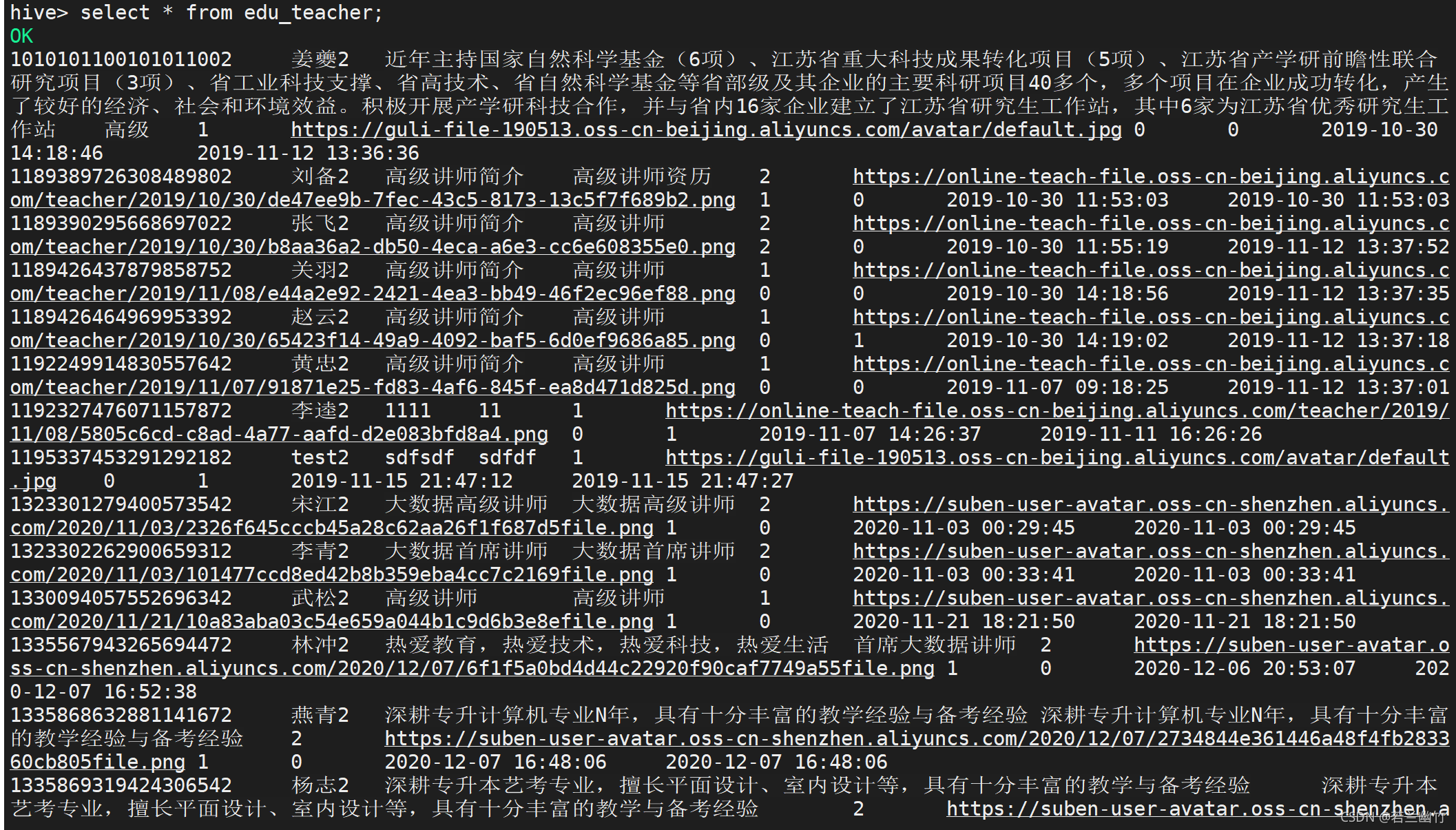
验证下hive表中是否已经存在数据了,在hive的命令行中执行如下命令:
select * from edu_teacher;
结果如下:
五、SparkSQL集成Hive
把Hive和Hadoop如下配置文件复制到$SPARK_HOME/conf目录下:
hive-site.xml
core-site.xml
hdfs-site.xml
注意:如果spark是全分布,则需要将上述三个文件同时复制到spark的所有节点启动Spark Shell的时候 加入MySQL的驱动
bin/spark-shell --master spark://niit01:7077 --jars /training/spark-2.4.8-bin-hadoop2.7/jars/mysql-connector-java-5.1.6.jar
注意:由于我的MySQL驱动也复制到spark的jars目录下
启动成功后如下图所示:
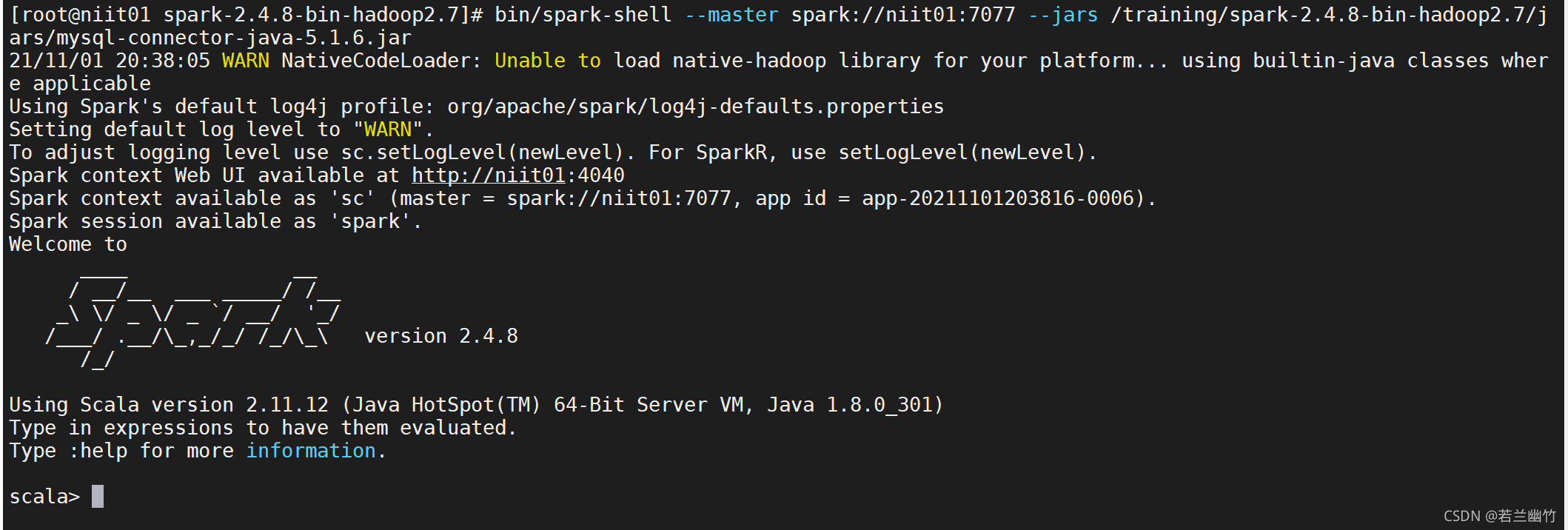
使用Spark shell 操作Hive
创建emp表
spark.sql("create table emp(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int,deptno int)row format delimited fields terminated by ','")创建成功后如下图所示:

在hive中查看会看到如下图所示:
在HDFS上会创建一个emp目录,如下图所示:

导入本地上的emp.csv数据到hive中的emp表
spark.sql("load data local inpath '/root/emp.csv' into table emp")注意:这里因版本的问题,可能会报错,可以先忽略,因数据已经导入到表中,后续可以查找MySQL驱动、spark和hive的版本的对应关系即可解决
导入成功后会在hdfs上看到有数据文件被导入到emp这个目录下,如图所示:

在hive命令行中查看,也会查询出数据:
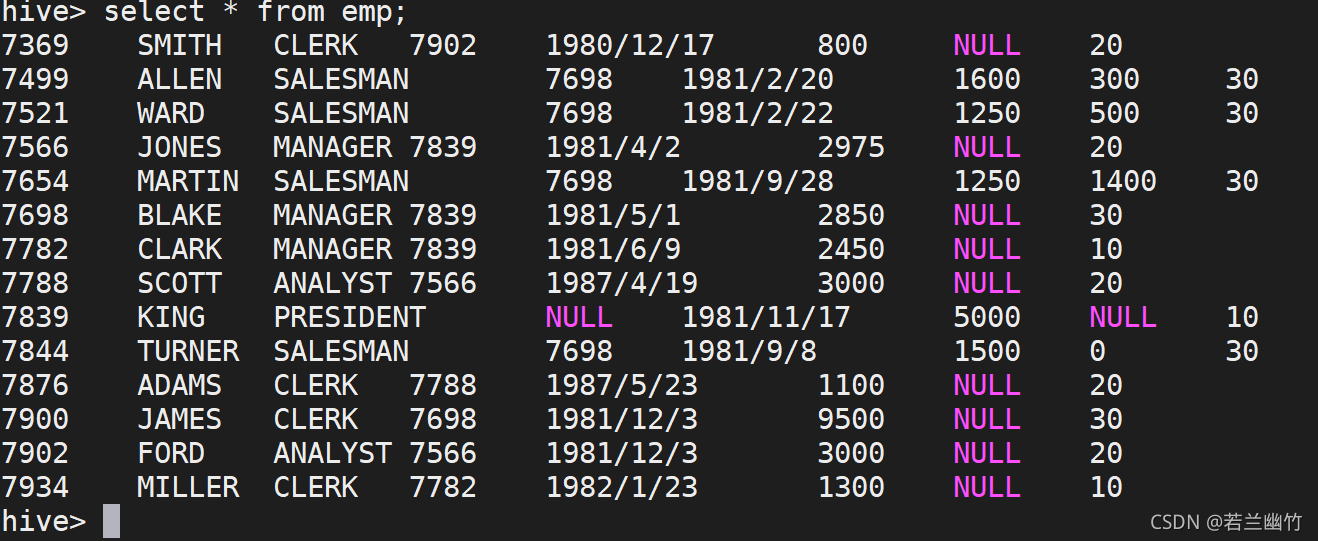
使用Spark-sql操作Hive
启动spark-sql:
bin/spark-sql --master spark://niit01:7077 --jars /training/spark-2.4.8-bin-hadoop2.7/jars/mysql-connector-java-5.1.6.jar
查看hive所有的表:
show tables
结果如图:
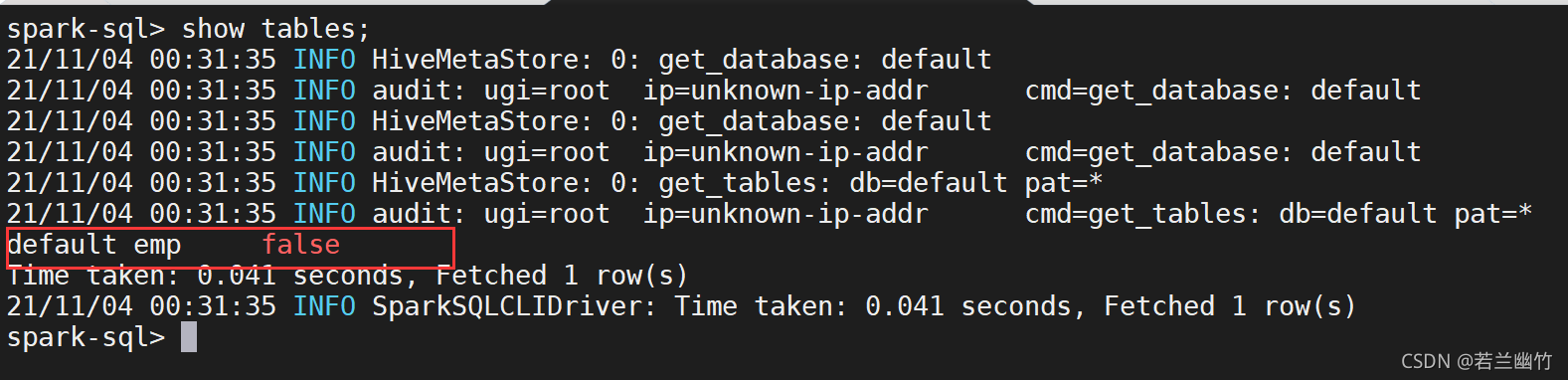
目前只有一张emp表(之前在hive中创建的edu_teacher被我删除掉了)查看emp表
select * from emp
结果如图:
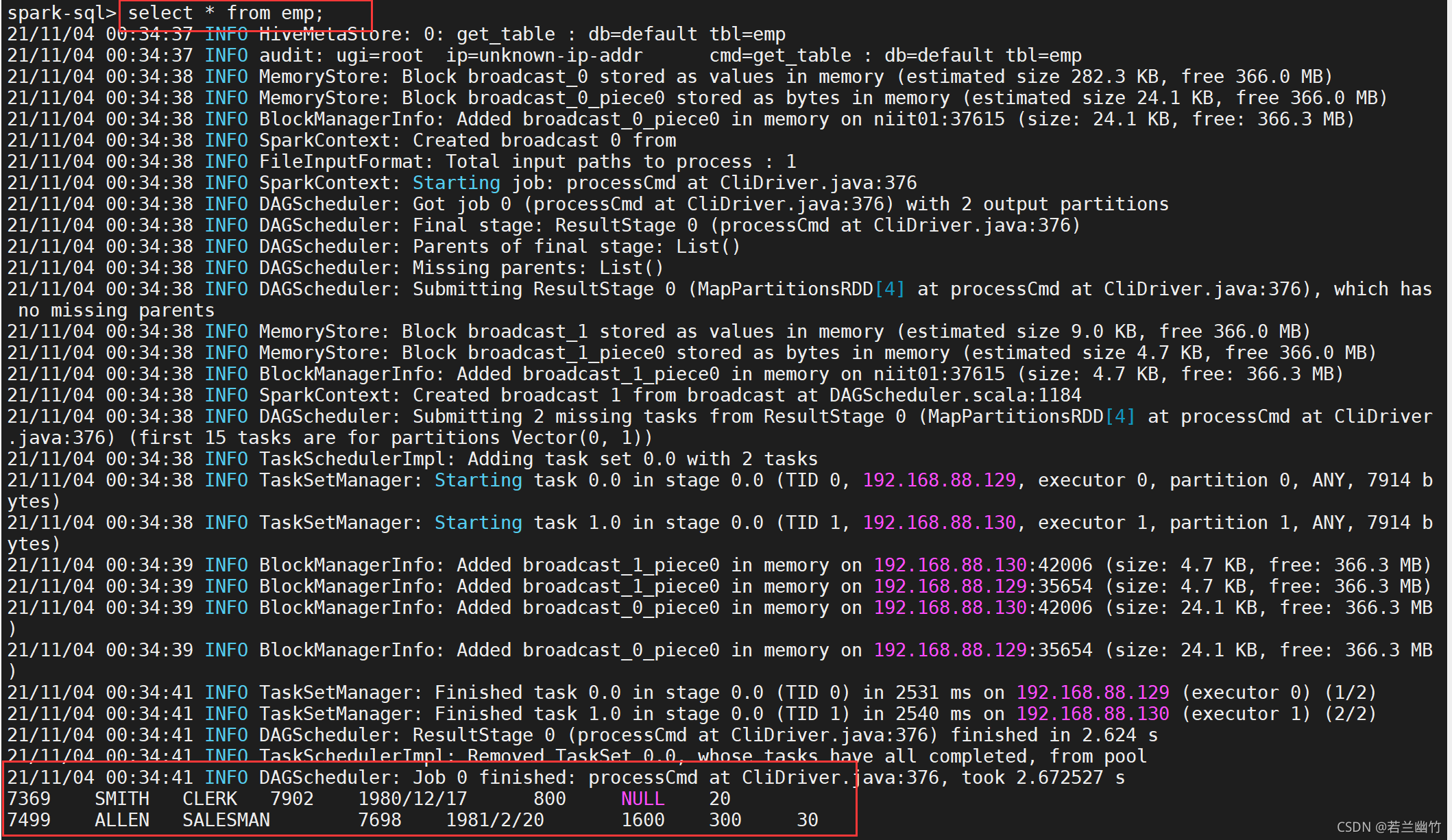
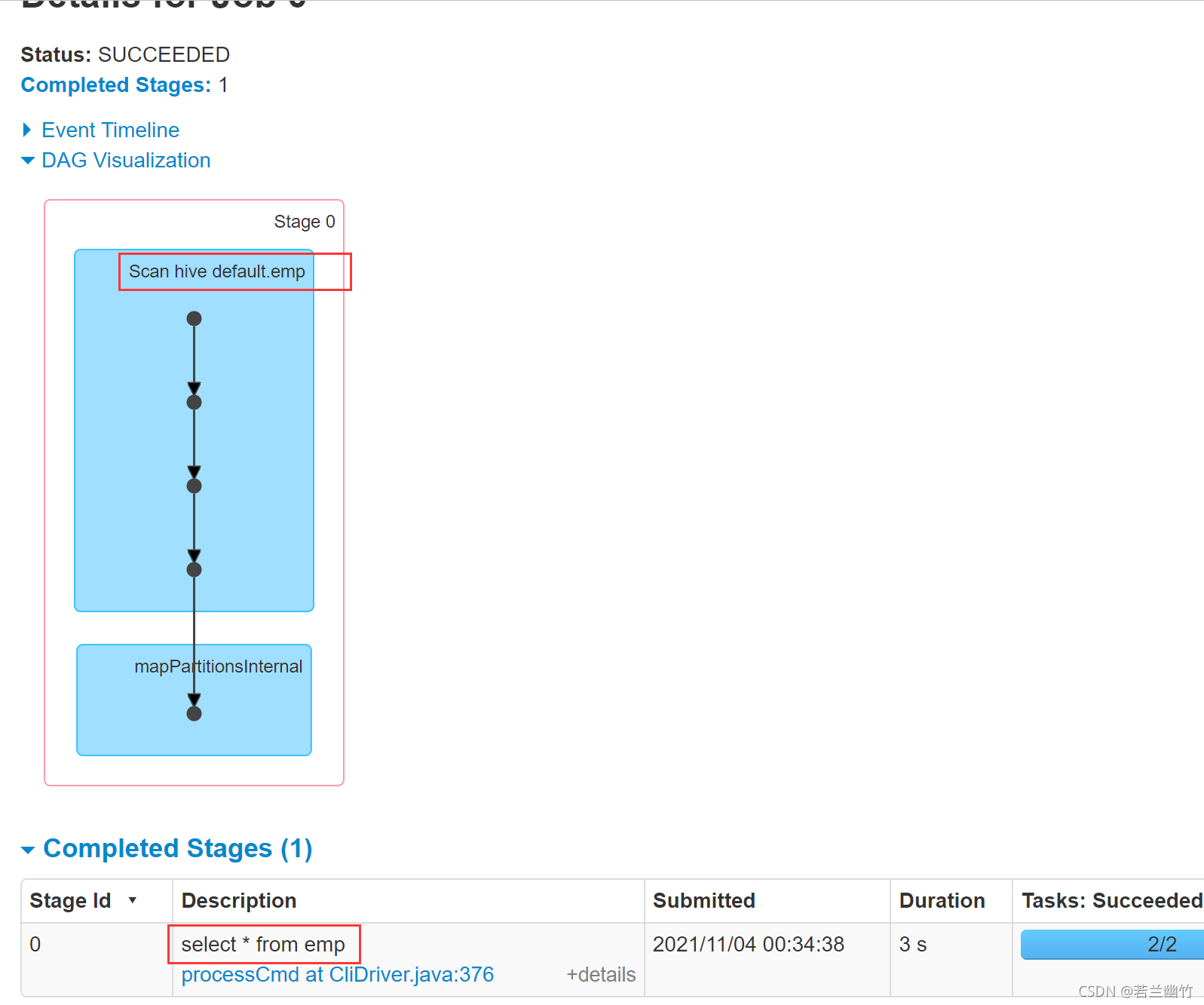
注意:上述select语句会产生一个job,如图所示:
可以重新创建其他表,如下所示:
CREATE TABLE check_standard (id int,dict_id int,standard_name string,standard_type int,create_time string,create_by string,update_time string,update_by string) row format delimited fields terminated by '\t'

注意:创建表不会产生Job将测试数据check_standard.csv导入到check_standard表中
load data local inpath '/root/check_standard.csv' into table check_standard;
再次查看下:
select * from check_standard;
结果如下:
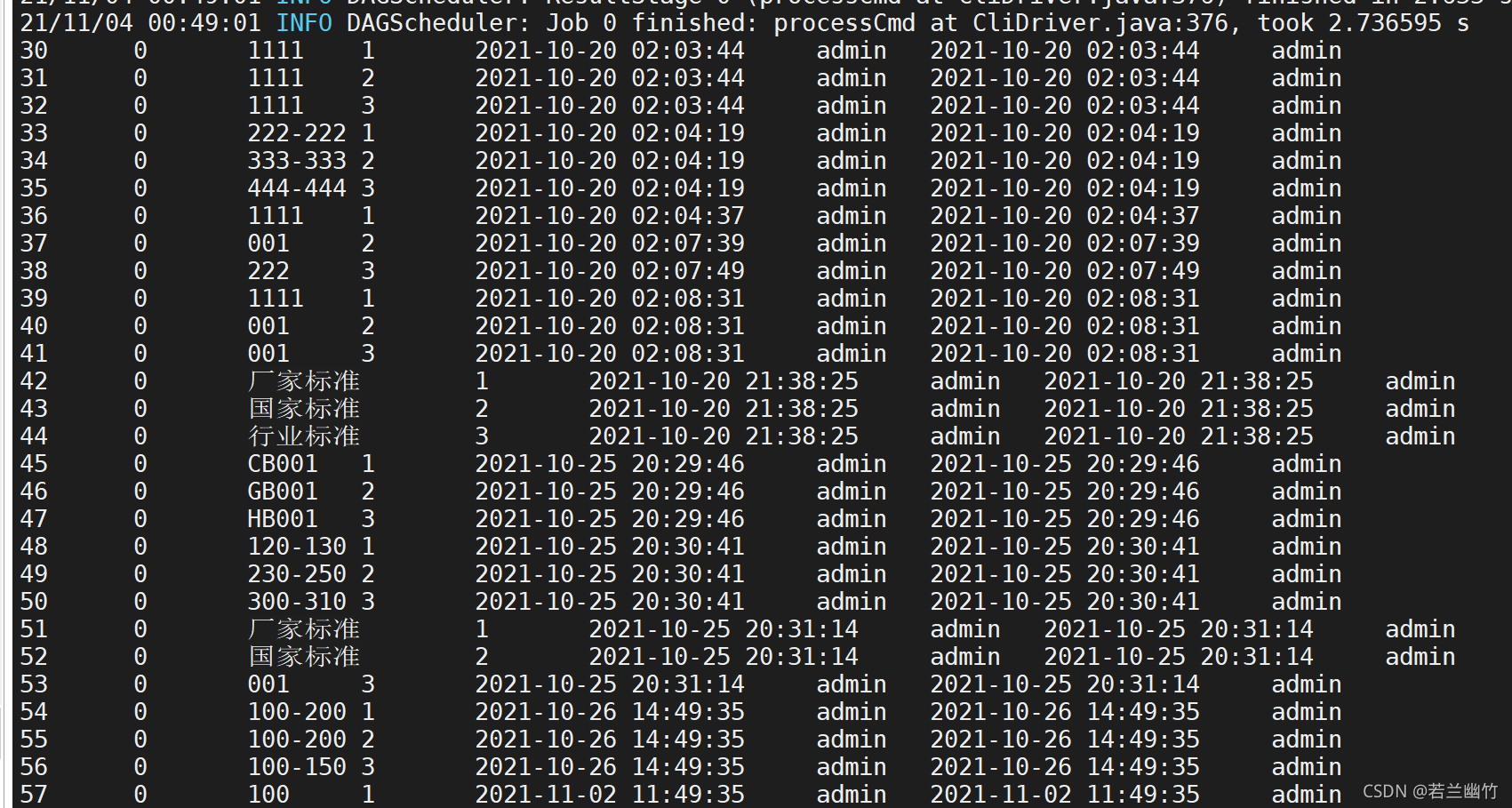
目录 返回
首页