ElasticSearch——倒排索引和正向索引
ElasticSearch——倒排索引和正向索引
1、正向索引
正向索引 (forward index) 以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档
这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护:
若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。
若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除
缺点:
检索效率太低,只能在一起简单的场景下使用
假设有文档一(id为doc_1)和文档二(id为doc_2),
文档一:my name is zhangsan
文档二:my car is BMW
文档一和文档二的正向索引为:
| 文档id | 关键词 |
|---|---|
| doc_1 | my ,name, is, zhangsan |
| doc_2 | my ,car ,is ,BMW |
假设使用正向索引,那么当你搜索 ‘name’ 的时候,搜索引擎必须检索文档中的每一个关键词,假设一个文档中包含成千上百个关键词,可想而知,会造成大量的资源浪费。于是倒排索引应运而生。
2、倒排索引
倒排索引 ,一般也被称为反向索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
倒排索引以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档。
一个表项就是一个字段,它记录该文档的ID和字符在该文档中出现的位置情况。
优缺点:
查询的时候由于可以一次得到查询关键字所对应的所有文档,所以查询效率高于正排索引。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂
假设有文档一(id为doc_1)和文档二(id为doc_2),
文档一:my name is zhangsan
文档二:my car is BMW
文档一和文档二的倒排索引为:
| 关键词 | 文档id |
|---|---|
| my | doc_1,doc_2 |
| name | doc_1 |
| is | doc_1,doc_2 |
| zhangsan | doc_1 |
| car | doc_2 |
| BMW | doc_1 |
倒排索引是相对正向索引而言的,你也可以将其理解为逆向索引。它是一种关键词与文档一一对应的数据结构。
3、倒排索引的组成
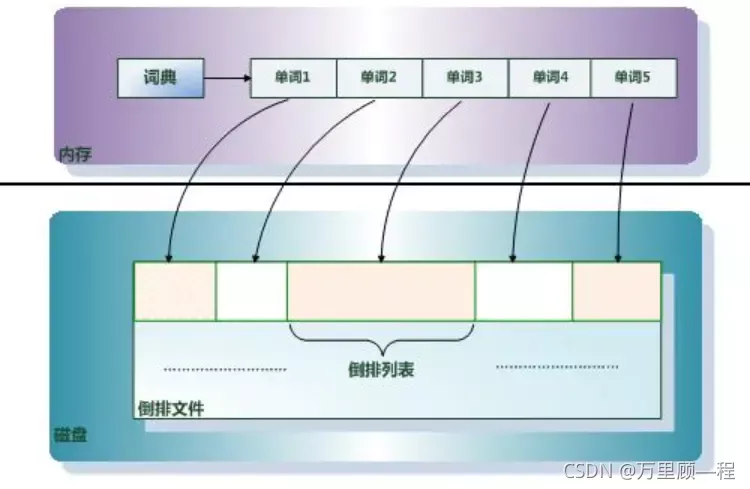
ES 倒排索引包含两个部分:单词词典和倒排列表
单词词典(Term Dictionary)
单词词典是倒排索引中非常重要的组成部分,它用来维护文档集合中出现过的所有单词的相关信息,同时用来记载某个单词对应的倒排列表在倒排文件中的位置信息。在支持搜索时,根据用户的查询词,去单词词典里查询,就能够获得相应的倒排列表,并以此作为后续排序的基础。
对于一个规模很大的文档集合来说,可能包含几十万甚至上百万的不同单词,能否快速定位某个单词,这直接影响搜索时的响应速度,所以需要高效的数据结构来对单词词典进行构建和查找,常用的数据结构包括哈希加链表结构和树形词典结构。
单词词典的特性:
是文档集合中所有单词的集合
它是保存索引的最小单位
其中记录着指向倒排列表的指针
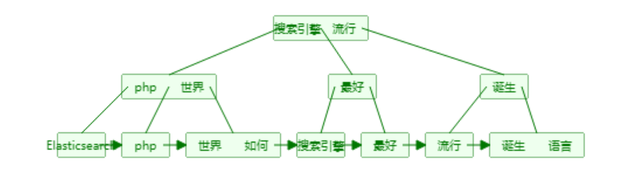
用B+Tree 实现单词词典,存储在内存:
倒排列表
倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息及频率(作关联性算分),每条记录称为一个倒排项(Posting)。
根据倒排列表,即可获知哪些文档包含某个单词。
倒排项(Posting)主要包含如下信息:
文档id用于获取原始信息
单词频率(TF,Term Frequency),记录该单词在该文档中出现的次数,用于后续相关性算分
位置(Position),记录单词在文档中的分词位置(多个),用于做词语搜索(Phrase Query)
偏移(Offset),记录单词在文档的开始和结束位置,用于高亮显示
单词词典和倒排列表整合到一起的结构如下:
4、倒排索引的更新策略
搜索引擎需要处理的文档集合往往都是动态集合,即在建好初始的索引后,不断有新文档进入系统,同时原先的文档集合内有些文档可能被删除或更改。
动态索引通过在内存中维护临时索引,可以实现对动态文档和实时搜索的支持。
服务器内存总是有限的,随着新加入系统的文档越来越多,临时索引消耗的内存也会随之增加。
当最初分配的内存将被使用完时,要考虑将临时索引的内容更新到磁盘索引中,以释放内存空间来容纳后续的新进文档。
索引基本更新思想:
倒排索引就是对初始文档集合建立的索引结构,一般单词词典都存储在内存,对应的倒排列表存储在磁盘文件中
临时索引是在内存中实时建立的倒排索引,其结构和前述的倒排索引是一样的,区别在于词典和倒排列表都在内存中存储。
新文档进入系统时,实时解析文件并将其加入到临时索引结构中。
删除文档列表则用来存储已被删除的文档的相应的文档ID,形成一个文档ID列表。
修改文档可以认为是旧文档先被删除,然后系统在增加一篇新的文档,通过这种间接方式实现对内容更改的支持。
5、倒排索引四种更新策略
常用的索引更新策略主要有四种:完全重建策略、再合并策略、原地更新策略及混合策略。
**完全重建策略:**当新增文档到达一定数量,将新增文档和原先的老文档整合,然后利用静态索引创建方法对所有文档重建索引,新索引建立完成后老索引会被遗弃。此法代价高,但是主流商业搜索引擎一般是采用此方式来维护索引的更新(这句话是书中原话)
再合并策略:当新增文档进入系统,解析文档,之后更新内存中维护的临时索引,文档中出现的每个单词,在其倒排表列表末尾追加倒排表列表项;一旦临时索引将指定内存消耗光,即进行一次索引合并,这里需要倒排文件里的倒排列表存放顺序已经按照索引单词字典顺序由低到高排序,这样直接顺序扫描合并即可。其缺点是:因为要生成新的倒排索引文件,所以对老索引中的很多单词,尽管其在倒排列表并未发生任何变化,也需要将其从老索引中取出来并写入新索引中,这样对磁盘消耗是没必要的。
**原地更新策略:**试图改进再合并策略,在原地合并倒排表,这需要提前分配一定的空间给未来插入,如果提前分配的空间不够了需要迁移。实际显示,其索引更新的效率比再合并策略要低。
**混合策略:**出发点是能够结合不同索引更新策略的长处,将不同索引更新策略混合,以形成更高效的方法。
目录 返回
首页