大数据技能竞赛之Spark搭建(五)
以下操作除特殊说明外都在三个节点上操作。
注意:操作前务必使三台虚拟机可以互相免密通信!
一、安装Scala软件包
使用xftp将软件包上传至三台虚拟机的/usr/package文件夹下
创建工作目录
mkdir -p /usr/scala
解压缩
cd /usr/package tar -zxvf scala-2.12.12.tgz -C /usr/scala
配置环境变量
vi /etc/profile
加入以下内容

保存后退出,使环境变量生效
source /etc/profile
检验是否安装成功
scala -version
出现以下界面则为安装成功

二、安装Spark软件包
使用xftp将软件包上传至三台虚拟机的/usr/package文件夹下
创建工作目录
mkdir -p /usr/spark
解压缩
cd /usr/package tar -zxvf spark-3.0.3-bin-hadoop2.7.tgz -C /usr/spark
配置环境变量
vi /etc/profile
加入以下内容

使环境变量生效
source /etc/profile
三、修改配置文件,指定主节点
进入相应的目录,并修改文件的名字
cd /usr/spark/spark-3.0.3-bin-hadoop2.7/conf mv spark-env.sh.template spark-env.sh
追加以下内容
export SPARK_MASTER_IP=master export SCALA_HOME=/usr/scala/scala-2.12.12 export JAVA_HOME=/usr/java/jdk1.8.0_221 export HADOOP_HOME=/usr/hadoop/hadoop-2.7.2 export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.7.2/etc/hadoop
配置spark的从节点,修改slaves文件
mv slaves.template slaves vi slaves
将原有文件的最后一行的localhost删除,追加以下内容

四、开启集群环境, 查看集群状态(只在master)
开启hadoop集群
cd /usr/hadoop/hadoop-2.7.2/ sbin/start-dfs.sh sbin/start-yarn.sh
开启spark集群
./sbin/start-all.sh
查看master节点,出现Master进程则为成功
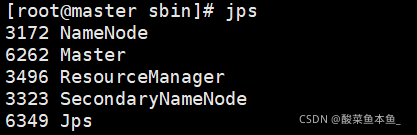
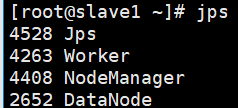
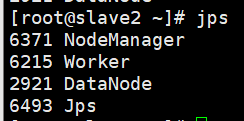
查看slave1和slave2节点,出现Worker进程则为成功
目录 返回
首页