安装Hadoop
实验概述:
1. 配置Hadoop主从服务
2. 配置服务器ssh免登录
3. 验证Hadoop安装成功
实验目的:
通过该实验后,可以独立安装配置Hadoop集群环境
实验背景:
本实验中会分配到三台装有Centos 7的服务器,请将其中的一台选定为主服务器(namenode),另外两台为从服务器(datanode) 。本实验以server-1为主服务器,server-2,server-3 为从服务器,实际试验中读者分配到的服务器名称不一定是叫server-1,server-2,server-3。
Hadoop安装包已下载并解压好,目录为:/usr/local/zhitu/hadoop-2.7.3。
请你配置hadoop集群环境,并确认hadoop启动成功。
实验步骤:
1.配置Hadoop主从服务
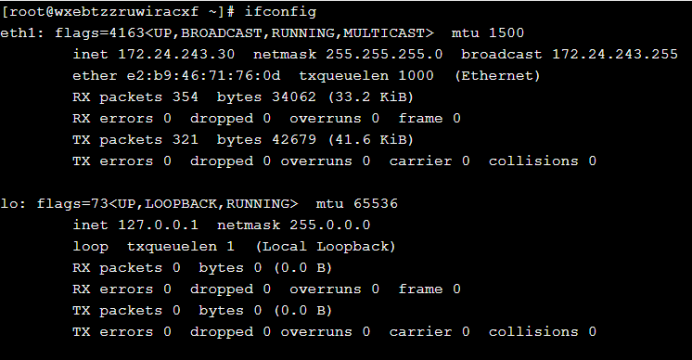
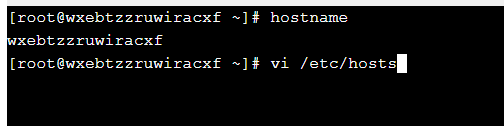
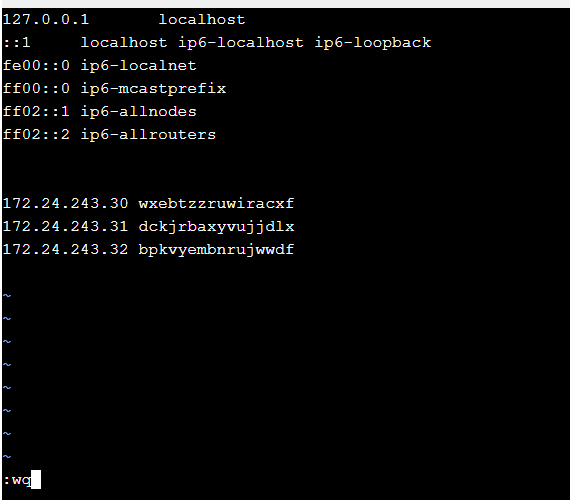
(1)将各服务器的ip和名称配置到/etc/hosts文件中,使用ifconfig命令可以查看本机ip,使用hostname命令可以查看本服务器名称;使用vi命令编辑/etc/hosts文件,将三台服务器的ip和名称写入文件,三台服务器上均需要配置。
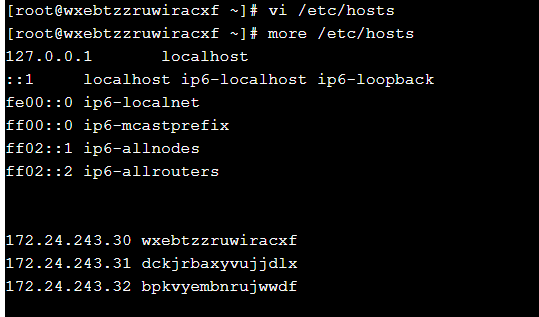
通过命令more查看
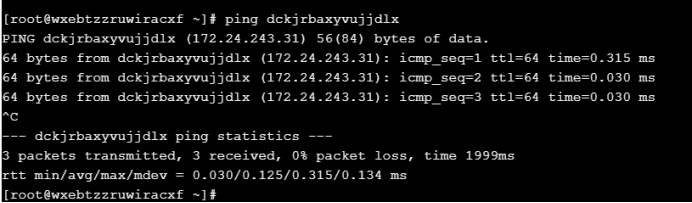
(2)通过主服务器ping一下其他俩个从服务器
(3)配置Hadoop(配置hadoop集群是需要在每一台服务器上都配置,这里我们只在主服务器上完成配置,配置完成之后我们将配置好的hadoop复制到其他服务器即可。)
此步骤的以下操作均在主服务器上操作:
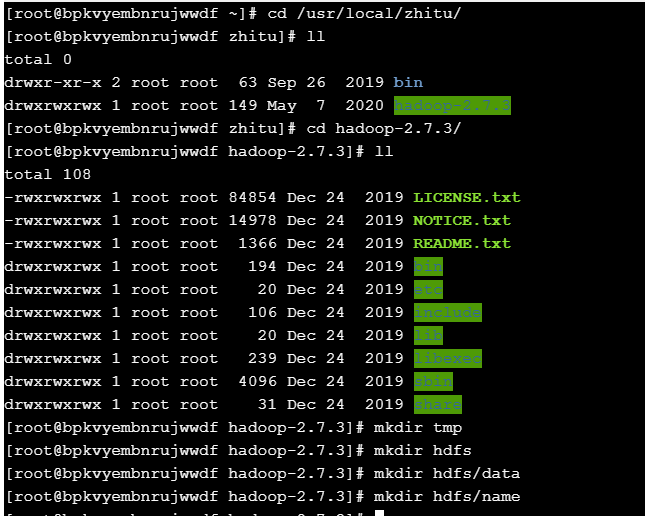
在hadoop-2.7.3目录下使用mkdir命令创建四个目录:tmp、hdfs、hdfs/data、 hdfs/name
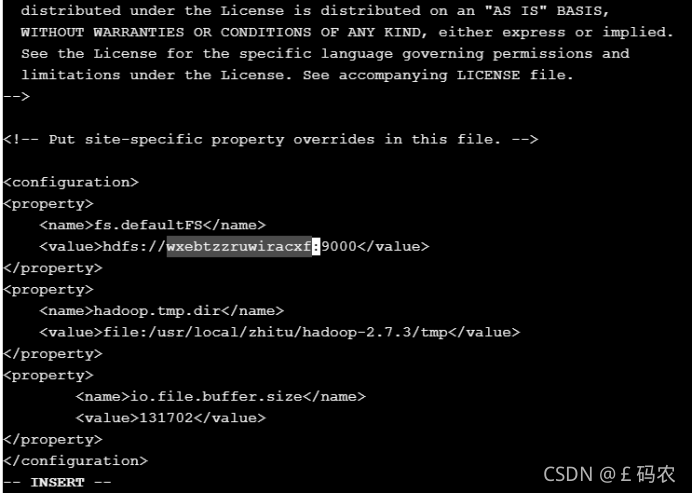
进入hadoop-2.7.3目录下的etc/hadoop目录下,配置core-site.xml文件

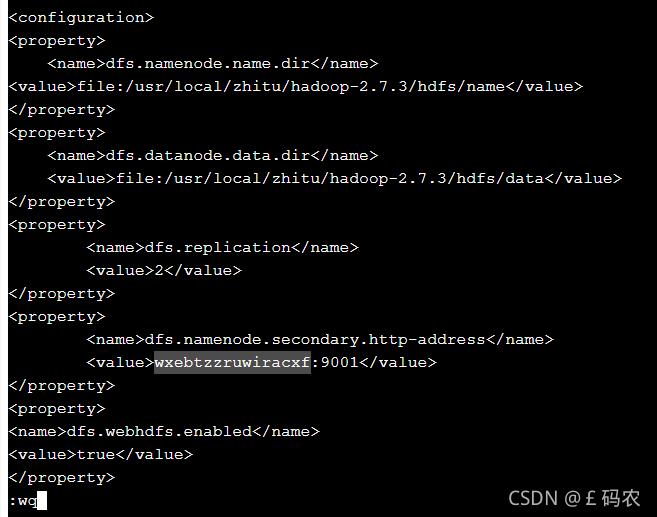
进入hadoop-2.7.3目录下的etc/hadoop目录下,配置hdfs-site.xml文件,该 文件主要是hdfs系统的相关配置

进入hadoop-2.7.3目录下的etc/hadoop目录下,将文件 mapred-site.xml.template使用mv命令重命名为mapred-site.xml,mappred-site.xml 文件中主要配置mapreduce相关的配置

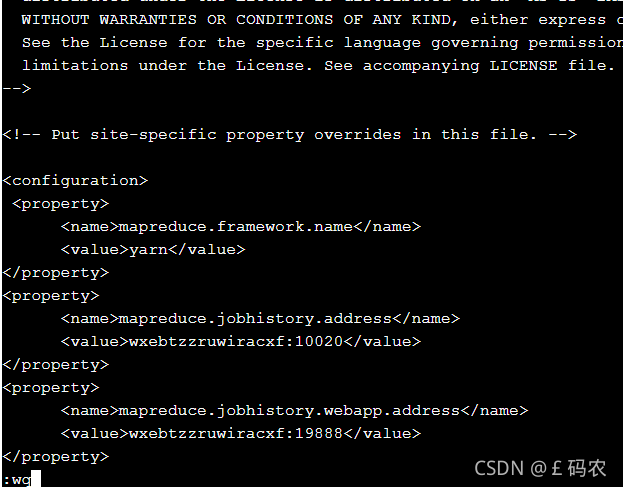
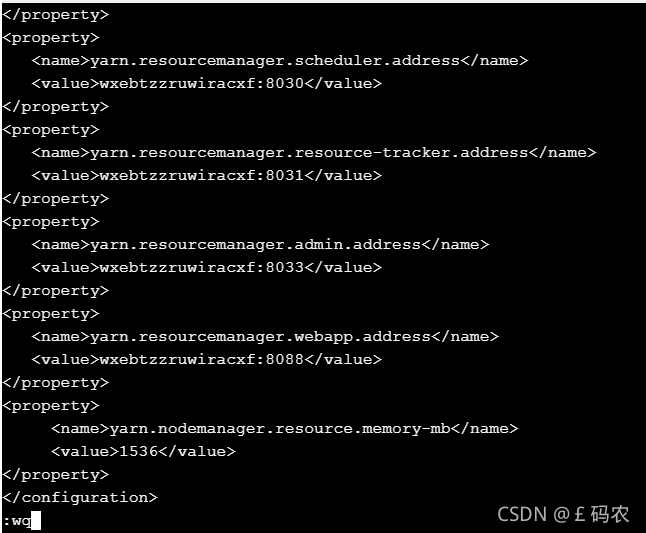
进入hadoop-2.7.3目录下的etc/hadoop目录下,配置yarn-site.xml文 件,yarn-site.xml文件中主要配置yarn框架相关的配置

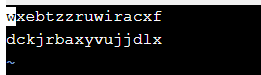
进入hadoop-2.7.3目录下的etc/hadoop目录下,修改slaves文件,将其中的 localhost去掉,并所有的从服务器名称添加进去,每台服务器名称占一行

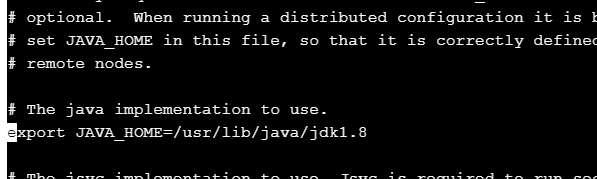
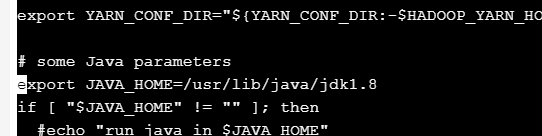
进入hadoop-2.7.3目录下的etc/hadoop目录下,修改hadoop-env.sh、 yarn-env.sh 两个文件,增加JAVA_HOME的环境变量配置。查看jdk目录可使用命 令echo $JAVA_HOME在hadoop-env.sh、yarn-env.sh两个文件中分别增加如下一段代码(jdk目录请根据自 己实际情况设置):export JAVA_HOME=/usr/lib/java/jdk1.8

2.配置服务器ssh免登录
(1) 为每个节点分别产生公、私密钥配置
使用如下命令可以为本服务器生成公钥(id_dsa.pub)和私钥(Id_dsa),要求输入 passphrased的时候直接敲回车:
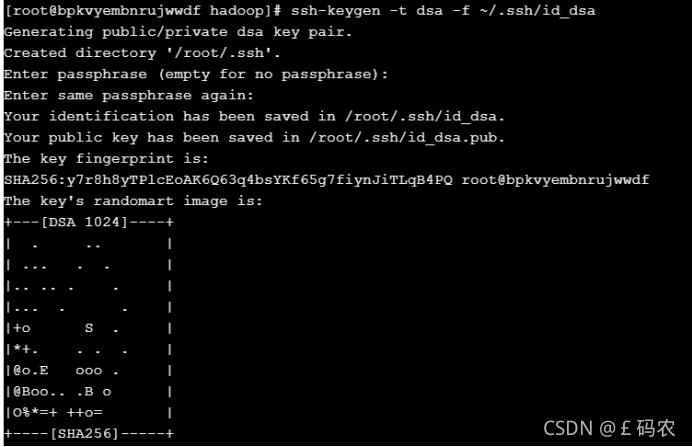
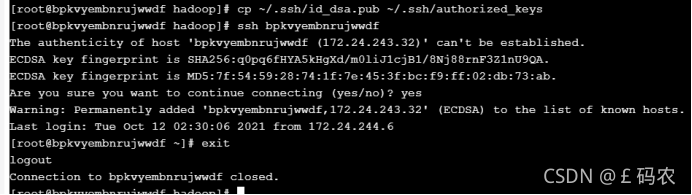
再使用如下命令,将公钥文件复制成authorized_keys文件;测试本机ssh免 登陆
(2)让主结点能通过SSH免密码登录两个子结点
使用scp命令,将主服务器的公钥文件id_dsa.pub复制到从服务器上,并命 令为server-1.pub(此文件名可以自己随意起)
再将上一步生成的server-1.pub文件内容追加到server-2的authorized_keys 文件中,这里我们使用ssh命令,在server-1上远程操作,如图
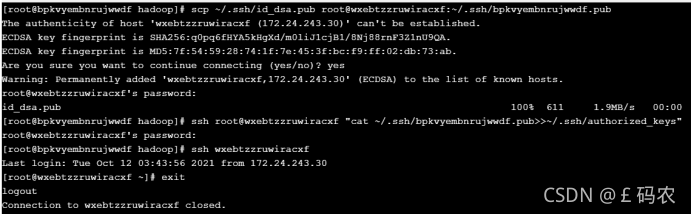
输入此命令后,会要求输入server-2服务器的root账号密码,输入密码即可
接着我们再登录第二台从服务器,发现需要密码,然后进行上述两 步操作

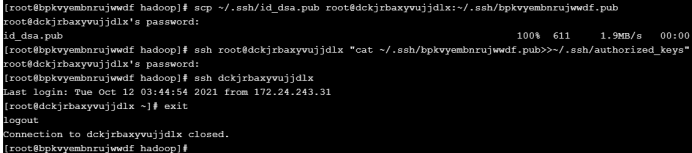
(3)将Hadoop复制到各从服务器
在主服务器上执行以下两条命令,(其中root为登录从服务器的用户名, server-2,server-3 为从服务器的名称,请根据自己实际情况修改)
scp -r /usr/local/zhitu/hadoop-2.7.3 root@server-2:/usr/local/zhitu/
scp -r /usr/local/zhitu/hadoop-2.7.3 root@server-3:/usr/local/zhitu/


(4)格式化namenode
在主服务器上,进入hadoop-2.7.3目录下,执行bin/hdfs namenode -format即可

(5)启动hadoop
在主服务器上,进入hadoop-2.7.3目录下,执行sbin/./start-all.sh即可
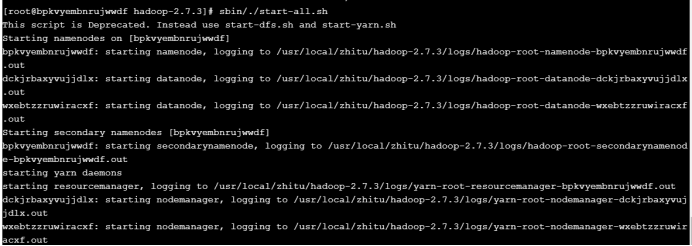
3.验证Hadoop安装成功
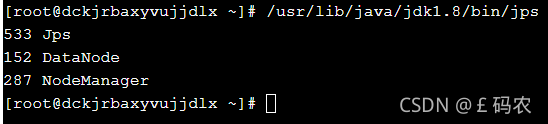
使用jps命令查看服务
主服务器上查看

第一台从服务器查看
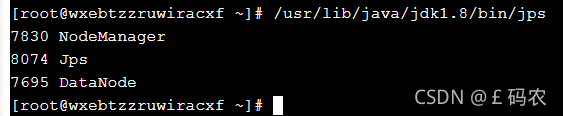
第二台从服务器查看
目录 返回
首页