K8s 之 Pod 高级用法

-
Label 标签使用技巧
- 在 k8s 之上,每一种资源都可以有一个标签,现实中用到的 pod 数量可能越来越多,我们期望能够分类进行管理,最简单和直接的效果就是把 pod 分成很多不同的小组,无论对于开发还是运维来讲都能显著提高管理效率,更何况控制器, service 资源也需要使用标签来识别它们所管控或关联到的资源,当我们给 pod 或者任何资源设定标签时,都可以使用标签查看,删除等对其执行相应的管理操作
- 简单来说所谓的标签就是附加在所对应的对象之上的键值对,一个资源之上可以存在多个标签,每个标签都是键值对,而且每个标签都可以被标签选择器进行匹配度检查从而完成资源挑选,通常情况下一个资源对象可使用多个标签,反之,一个标签也可以被添加到多个资源对像上;标签既可以在资源对象创建的时候指定,也可以在资源对象创建之后使用命令来进行管理,这个管理既包括添加,也包括删除,还包括修改;
- 实践中我们通常给资源附加不同维度的标签,来进行不同维度的管理,比方说 labels 下面的标签 app: myapp 用来指明当前的应用程序(可能是 nginx,tomcat,http,mysql,redis 等)是什么,也可以分层打标签,如前端 frontend,后端 backend,开发环境 dev 等;也可以对版本打标签。
labels:
app: myapp
tier: frontend
标签:
key: value (key 和 value 最多 63 个字符
key 由字母,数字,下划线组成,只能以字母或数字开头,不能为空值;
value 可以为空,也是只能以字母或数字开头和结尾,中间可使用字母,数字,下划线) - 在查看 pod 或任何类型资源时,也可以直接指定标签选择器来选择能显示哪些标签
- 查看默认名称空间所有 pod 资源对象的标签
kubectl get pods --show-labels
- 查看所有资源对象下拥有 run 这个标签的标签值
kubectl get pod -L run
-L 会列出所有 pod 里的容器,在最后 RUN 栏里显示匹配的容器名
- 查看拥有 run 这个标签的 pod 资源对象
kubectl get pod -l run
-l 只会显示匹配的容器
- 查看拥有 run 这个标签的资源对象,并且把标签显示出来
kubectl get pod -l run --show-labels
- 添加资源的标签
- kubectl label pods nginx-test-544744fc75-kvd77 gf=test
key=value key是标签名
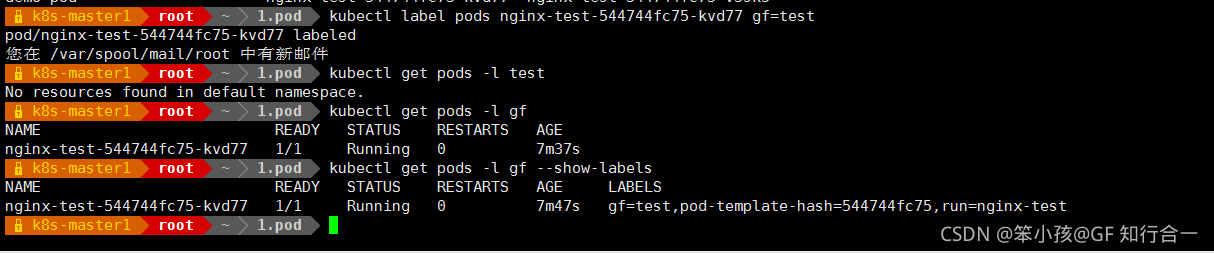
- 修改已经存在的标签
- kubectl label pods nginx-test-544744fc75-kvd77 gf=labels --overwrite

- 查看多个标签使用 , 逗号隔开搜索名称
kubectl get pod -l gf,test --show-labels
-
给 nodes 节点打标签
- 查看 nodes 节点的标签
kubectl get nodes --show-labels
- 给 node 节点打标签
kubectl label nodes k8s-01 GF=IT
这里注意 要加入 k8s 集群的主机名里面不能使用下划线
-
名称空间 namespace
- namespace 是 k8s 集群级别的资源,可以给不同的用户、租户、环境或项目创建对应的名称空间,例如,可以为 development、qa、和 production 应用环境分别创建各自的名称空间。
- k8s 的绝大多数资源都属于名称空间级别,同一名称空间内的同一类资源名必须是唯一的,但跨名称空间时并无此限制。
- k8s 还有一些资源属于集群级别的,如 node、namespace、PersistentVolume等资源,它们不属于任何名称空间,因此资源对象的名称必须全局唯一。
-
查看名称空间及其资源对象
k8s 集群默认提供了几个名称空间用于特定目的,例如,kube-system 主要用于运行系统级资源,而 default 则为那些未指定名称空间的资源操作提供一个默认值。
使用 kubectl get namespace 可以查看 namespace 资源,使用 kubectl describe namespace $NAME 可以查看特定的名称空间的详细信息。 -
管理 namespace 资源
namespace 是 k8s api 的标准资源类型之一,namespace 资源属性较少,通常只需要指定名称即可创建,如“kubectl create namespace qa”。
namespace 资源的名称仅能由字母、数字、下划线、连接线等字符组成。
删除 namespace 资源会级联删除其包含的所有其他资源对象 - 命令格式 功能
- kubectl delete TYPE RESOURCE -n NS 删除指定名称空间内的指定资源
kubectl delete TYPE --all -n NS 删除指定名称空间内的指定类型的所有资源
kubectl delete all -n -NS 删除指定名称空间内的所有资源
kubectl delete all --all 删除所有名称空间中的所有资源
注意:namespace 对象仅用于资源对象名称的隔离,它自身并不能隔绝跨名称空间的 pod 间通信,那是网络策略资源的功能
-
Pod 高级用法:node 节点选择器
- 在创建 pod 资源的时候,pod 会根据 schduler 进行调度,那么默认会调度到随机的一个工作节点,如果我们想要 pod 调度到指定节点或者调度到一些具有相同特点的 node 节点,怎么办呢?
-
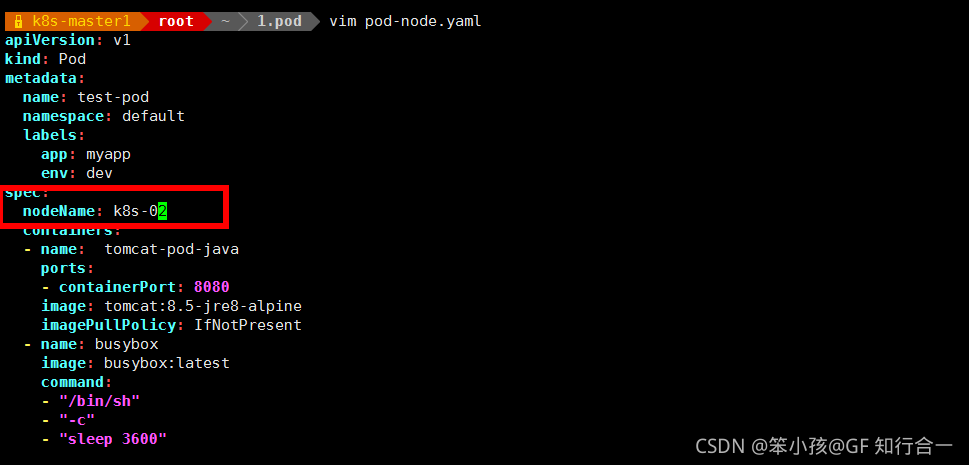
可以使用 pod 中的 nodeName 或者 nodeSelector 字段指定要调度到的 node 节点
-
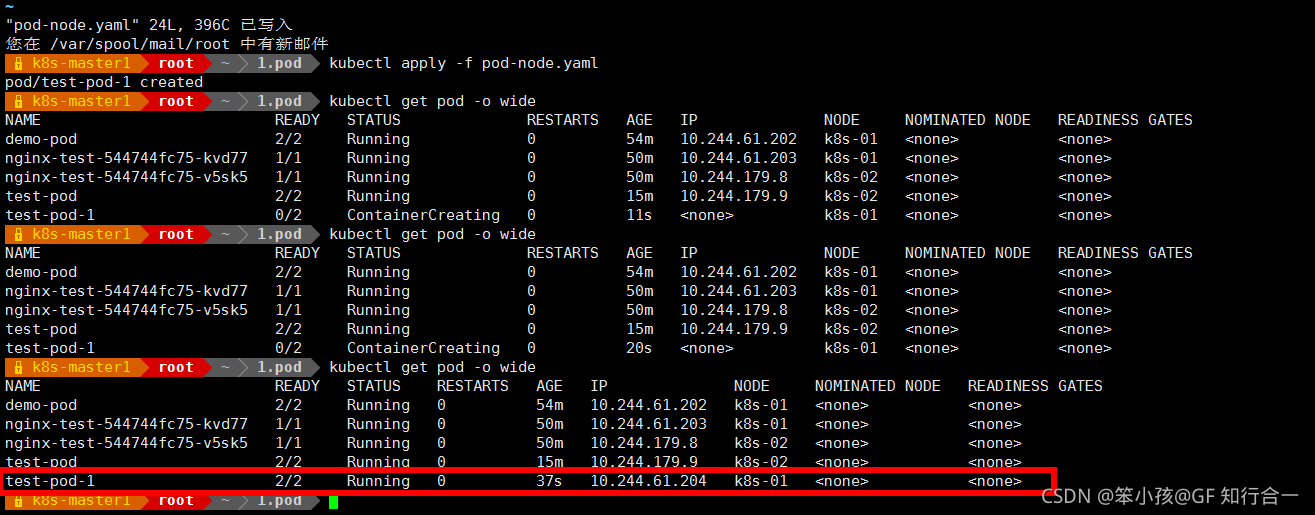
使用 nodeName 指定 pod 节点运行在哪个具体 node 上
- vim pod-node.yaml
- kubectl apply -f pod-node.yaml
kebtctl get pod -o wide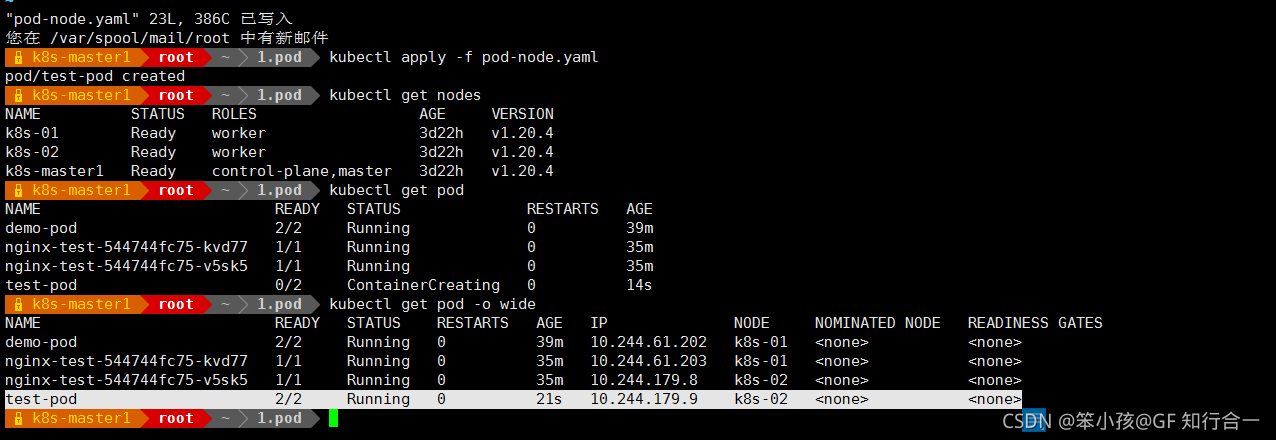
-
使用 nodeSelector 指定 pod 调度到具有哪些标签的 node 节点上
#使用之前打的标签 GF=IT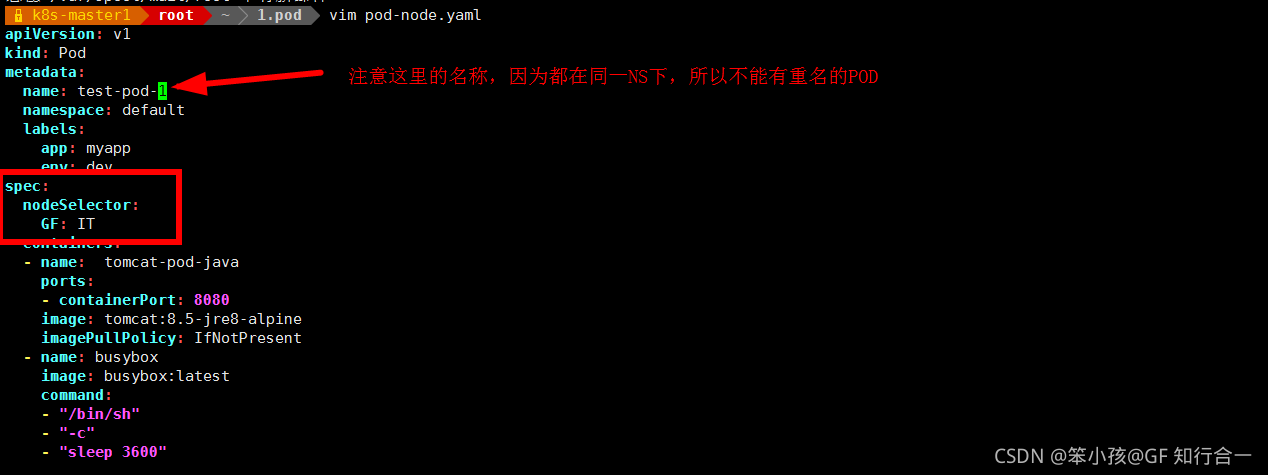
-
Node 节点亲和性
- 节点亲和性调度:nodeAffinity
kubectl explain pods.spec.affinity
KIND: Pod
VERSION: v1
RESOURCE: affinity <Object>
DESCRIPTION:
If specified, the pod's scheduling constraints
Affinity is a group of affinity scheduling rules.
FIELDS:
nodeAffinity <Object>
podAffinity<Object>
podAntiAffinity <Object> - kubectl explain pods.spec.affinity.nodeAffinity
KIND: Pod
VERSION: v1
RESOURCE: nodeAffinity <Object>
DESCRIPTION:
Describes node affinity scheduling rules for the pod.
Node affinity is a group of node affinity scheduling rules.
FIELDS:
preferredDuringSchedulingIgnoredDuringExecution <[]Object>
requiredDuringSchedulingIgnoredDuringExecution <Object>
prefered 表示有节点尽量满足这个位置定义的亲和性,这不是一个必须的条件,软亲和性
required 表示必须有节点满足这个位置定义的亲和性,这是个硬性条件,硬亲和性 - kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution
KIND: Pod
VERSION: v1
RESOURCE: requiredDuringSchedulingIgnoredDuringExecution <Object>
DESCRIPTION:
FIELDS:
nodeSelectorTerms <[]Object> -required-
Required. A list of node selector terms. The terms are ORed. - kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms
KIND: Pod
VERSION: v1
RESOURCE: nodeSelectorTerms <[]Object>
DESCRIPTION:
Required. A list of node selector terms. The terms are ORed.
A null or empty node selector term matches no objects. The requirements of
them are ANDed. The TopologySelectorTerm type implements a subset of the
NodeSelectorTerm.
FIELDS:
matchExpressions <[]Object>
matchFields <[]Object>
matchExpressions:匹配表达式的
matchFields: 匹配字段的 - kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms.matchFields
KIND: Pod
VERSION: v1
RESOURCE: matchFields <[]Object>
DESCRIPTION:
FIELDS:
key <string> -required-
values <[]string> - kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms.matchExpressions
KIND: Pod
VERSION: v1
RESOURCE: matchExpressions <[]Object>
DESCRIPTION:
FIELDS:
key <string> -required-
operator <string> -required-
values <[]string>
key:检查 label
operator:做等值选则还是不等值选则
values:给定值
-
使用 requiredDuringSchedulingIgnoredDuringExecution 硬亲和性
- vim pod-nodeaffinity-demo.yaml
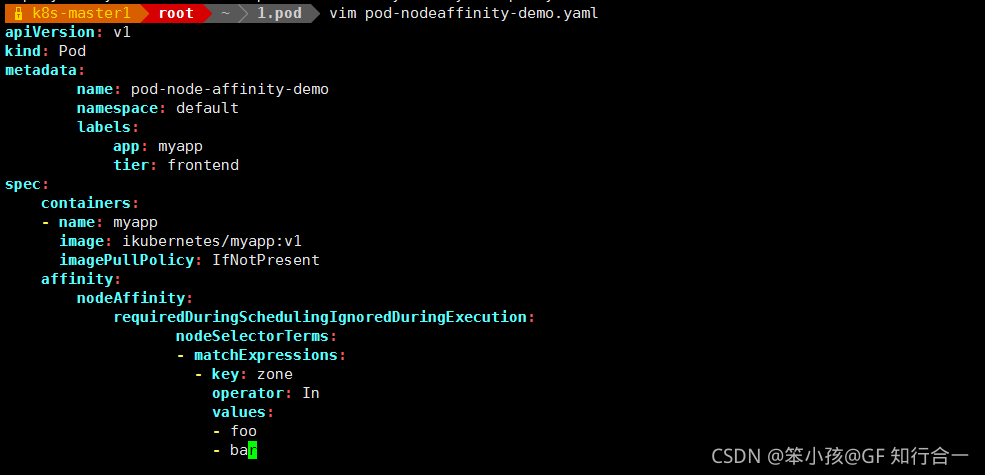
- 检查当前节点中有任意一个节点拥有 zone 标签的值是 foo 或者 bar,就可以把 pod 调度到这个 node 节点的 foo 或者 bar 标签上的节点上
- kebectl apply -f pod-nodeaffinity-demo.yaml
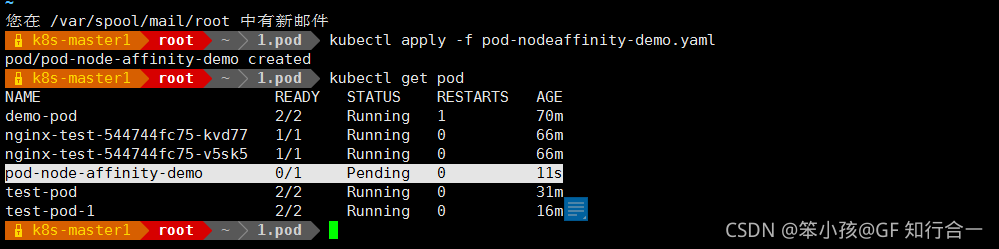
-
status 的状态是 pending,说明没有完成调度,因为没有一个拥有 zone 的标签的值是 foo 或者 bar,而且使用的是硬亲和性,必须满足条件才能完成调度
- 给这个 k8s-02 节点打上标签 zone=foo,在查看
kubectl label nodes k8s-02 zone=foo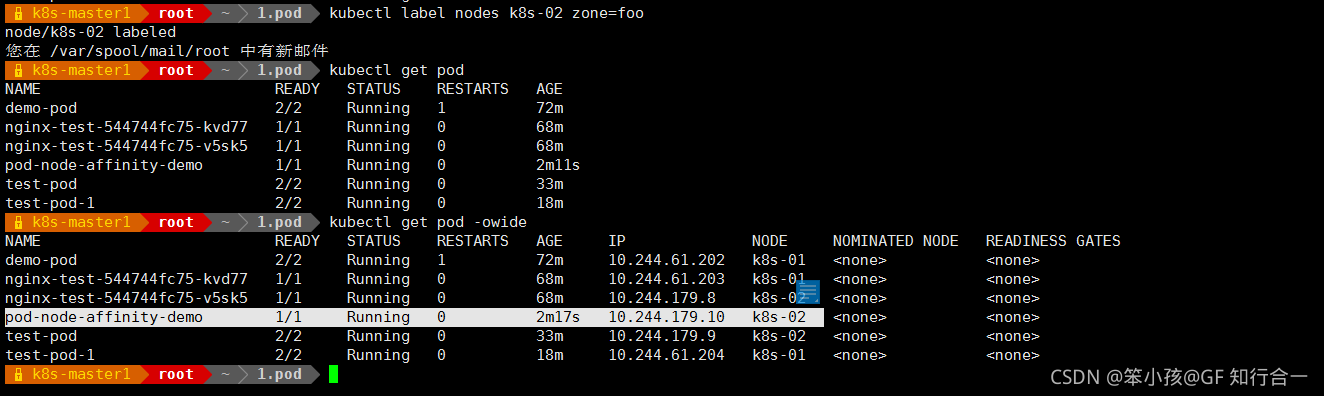
-
使用 preferredDuringSchedulingIgnoredDuringExecution 软亲和性
- vim pod-nodeaffinity-demo-2.yaml
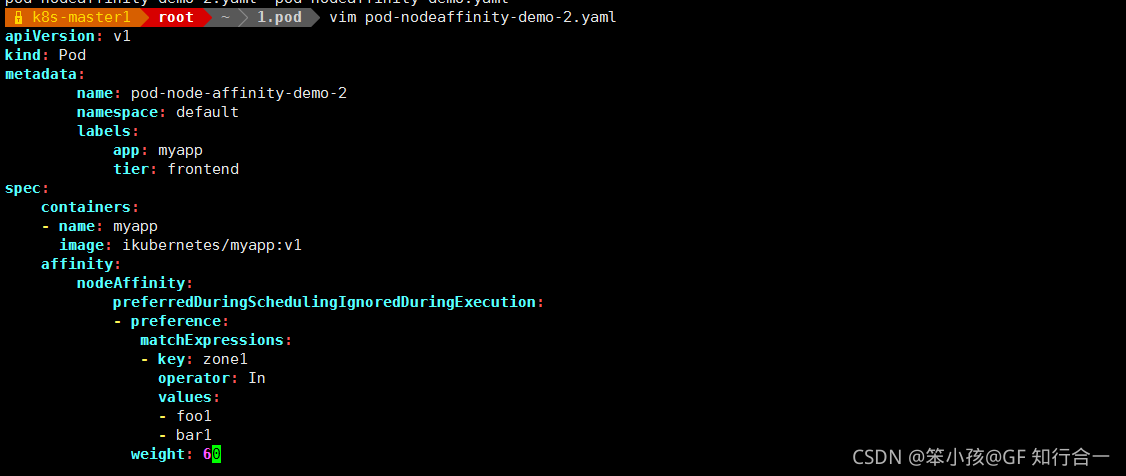
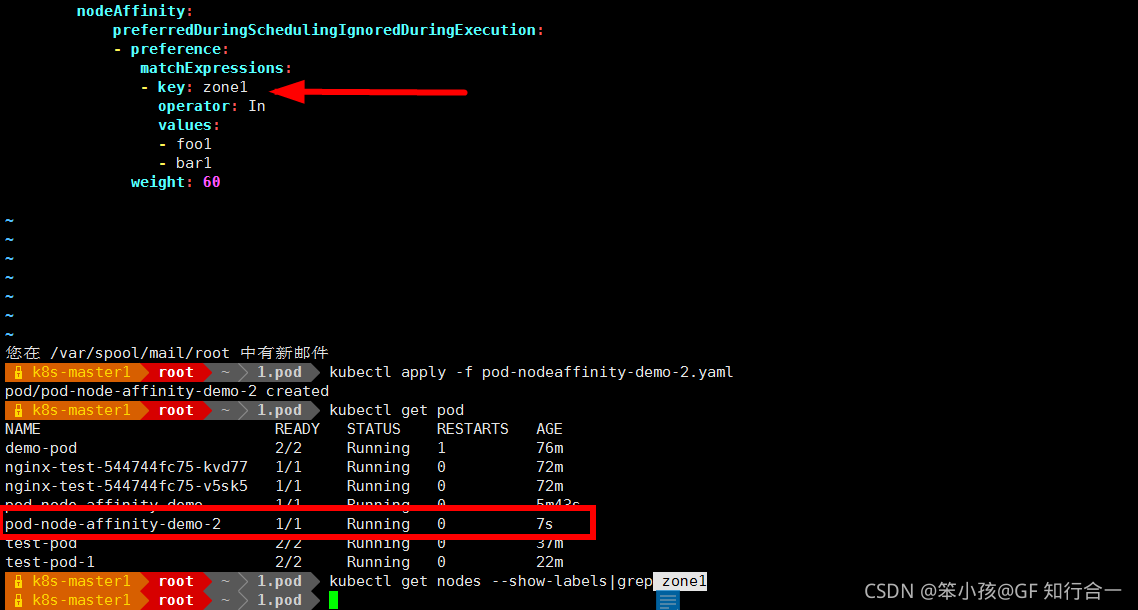
-
发现软亲和性是可以运行这个 pod 的,尽管没有运行这个 pod 的节点定义的 zone1 标签
-
Pod 节点亲和性
-
pod 自身的亲和性调度有两种表示形式
-
podaffinity:pod 和 pod 更倾向腻在一起,把相近的 pod 结合到相近的位置,如同一区域,同一机架,这样的话 pod 和 pod 之间更好通信,比方说有两个机房,这两个机房部署的集群有 1000 台主机,那么我们希望把 nginx 和 tomcat 都部署同一个地方的 node 节点上,可以提高通信效率;
-
podunaffinity:pod 和 pod 更倾向不腻在一起,如果部署两套程序,那么这两套程序更倾向于反亲和性,这样相互之间不会有影响。
-
第一个 pod 随机选则一个节点,做为评判后续的 pod 能否到达这个 pod 所在的节点上的运行方式,这就称为 pod 亲和性;
-
怎么判定哪些节点是相同位置的,哪些节点是不同位置的;
-
在定义pod 亲和性时需要有一个前提,哪些 pod 在同一个位置,哪些 pod 不在同一个位置,这个位置是怎么定义的,标准是什么?以节点名称为标准,这个节点名称相同的表示是同一个位置,节点名称不相同的表示不是一个位置。
-
kubectl explain pods.spec.affinity.podAffinity
KIND: Pod
VERSION: v1
RESOURCE: podAffinity <Object>
DESCRIPTION:
Describes pod affinity scheduling rules (e.g. co-locate this pod in the
same node, zone, etc. as some other pod(s)).
Pod affinity is a group of inter pod affinity scheduling rules.
FIELDS:
preferredDuringSchedulingIgnoredDuringExecution <[]Object>
requiredDuringSchedulingIgnoredDuringExecution <[]Object>
requiredDuringSchedulingIgnoredDuringExecution: 硬亲和性
preferredDuringSchedulingIgnoredDuringExecution:软亲和性
kubectl explain pods.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution
KIND: Pod
VERSION: v1
RESOURCE: requiredDuringSchedulingIgnoredDuringExecution <[]Object>
DESCRIPTION:
FIELDS:
labelSelector <Object>
namespaces <[]string>
topologyKey <string> -requiredtopologyKey:位置拓扑的键,这个是必须字段
怎么判断是不是同一个位置:
rack=rack1
row=row1
使用 rack 的键是同一个位置
使用 row 的键是同一个位置
labelSelector:判断 pod 跟别的 pod 亲和,跟哪个 pod 亲和,需要靠 labelSelector,通过 labelSelector选则一组能作为亲和对象的 pod 资源
namespace:
labelSelector 需要选则一组资源,那么这组资源是在哪个名称空间中呢,通过 namespace 指定,如果不指定 namespaces,那么就是当前创建 pod 的名称空间
kubectl explain pods.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution.labelSelector
KIND: Pod
VERSION: v1
RESOURCE: labelSelector <Object>
DESCRIPTION:
A label query over a set of resources, in this case pods.
A label selector is a label query over a set of resources. The result of
matchLabels and matchExpressions are ANDed. An empty label selector matches
all objects. A null label selector matches no objects.
FIELDS:
matchExpressions <[]Object>
matchLabels <map[string]string> -
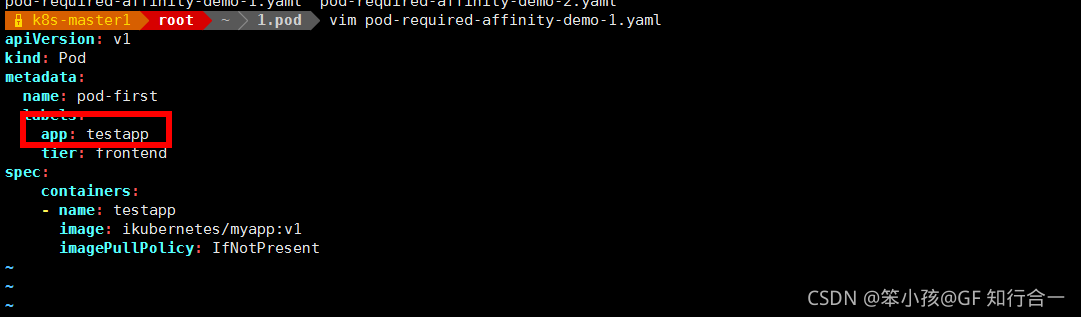
定义两个 pod,第一个 pod 做为基准,第二个 pod 跟着它走
vim pod-required-affinity-demo-1.yaml
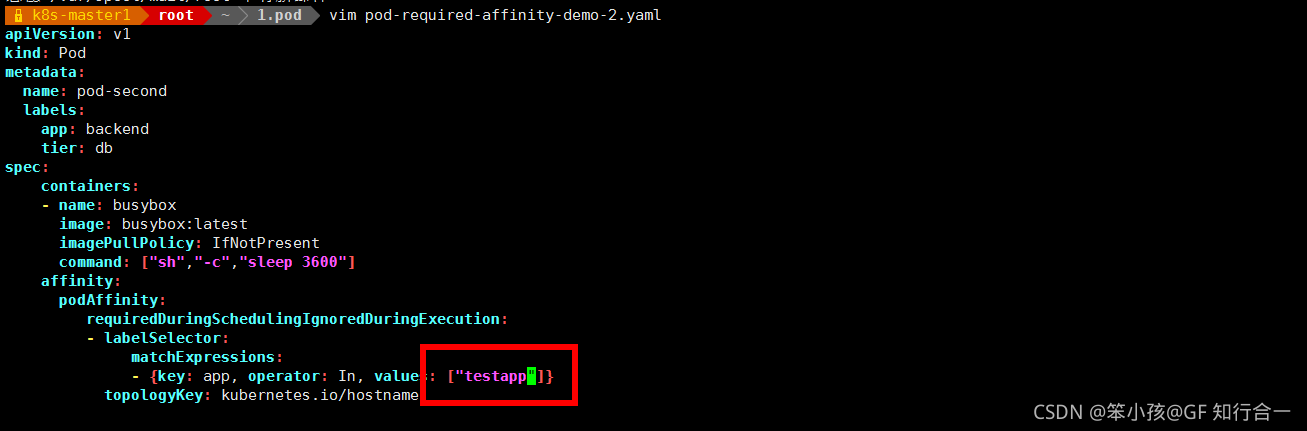
vim pod-required-affinity-demo-2.yaml
-
表示创建的 pod 必须与拥有 app=testapp 标签的 pod 在一个节点上
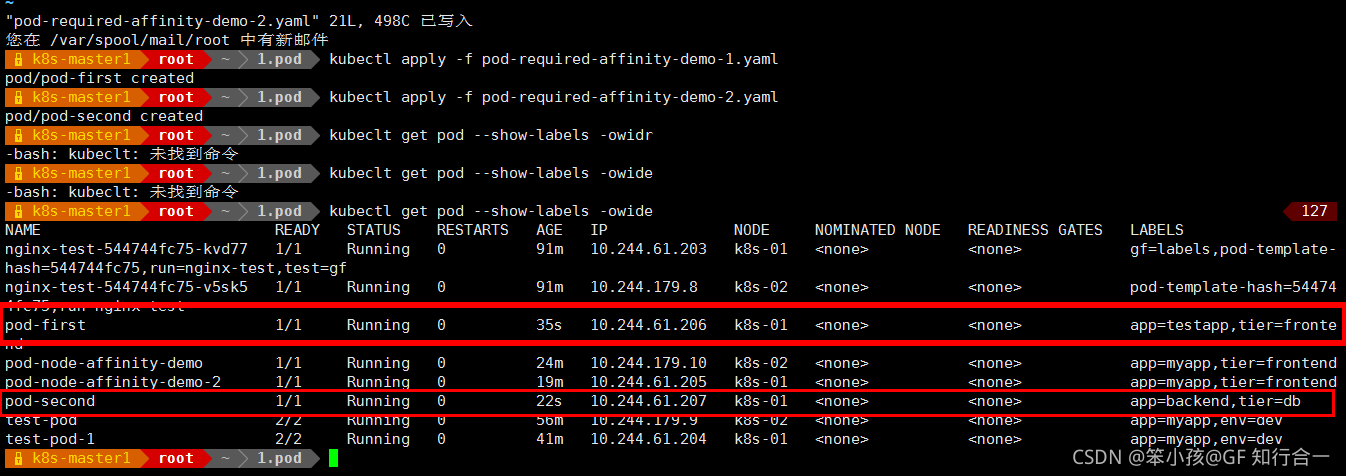
-
说明第一个 pod 调度到哪,第二个 pod 也调度到哪,这就是 pod 节点亲和性
-
pod 节点反亲和性
-
定义两个 pod,第一个 pod 做为基准,第二个 pod 跟它调度节点相反
- vim pod-required-anti-affinity-demo-1.yaml
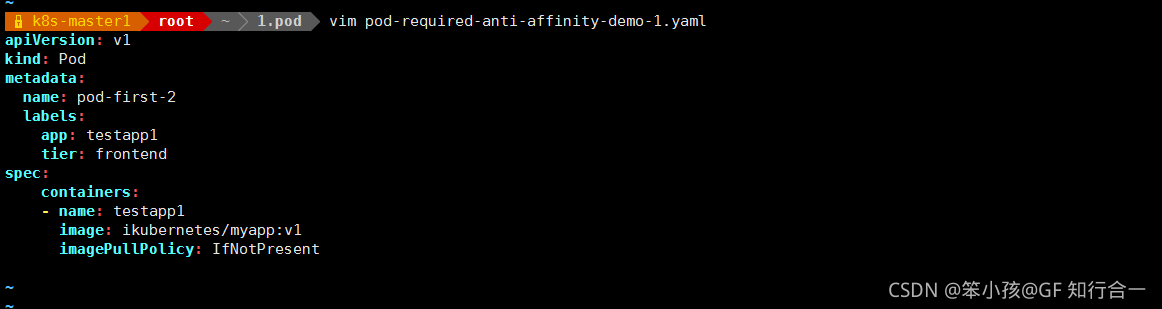 vim pod-required-anti-affinity-demo-2.yaml
vim pod-required-anti-affinity-demo-2.yaml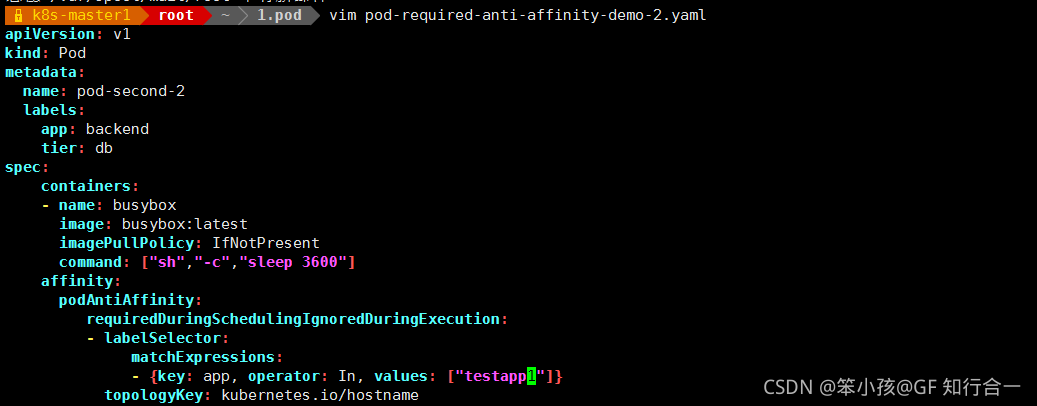
-
显示两个 pod 不在一个 node 节点上,这就是 pod 节点反亲和性,判断条件是 topologyKey: kubernetes.io/hostname
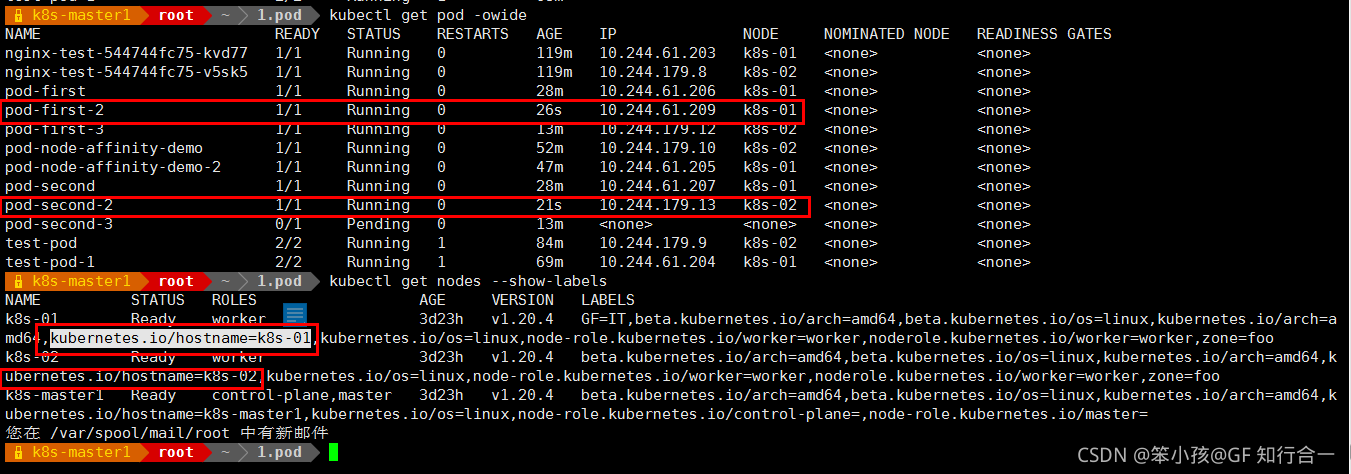
-
使用 topologykey
- 给2个 nodes 都打上标签 zone=foo
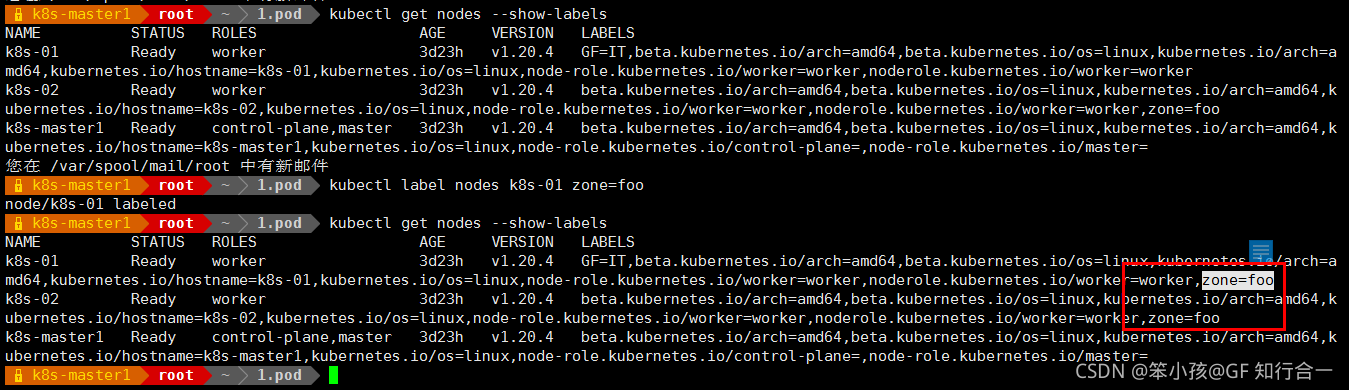
- vim pod-required-anti-affinity-demo-3.yaml
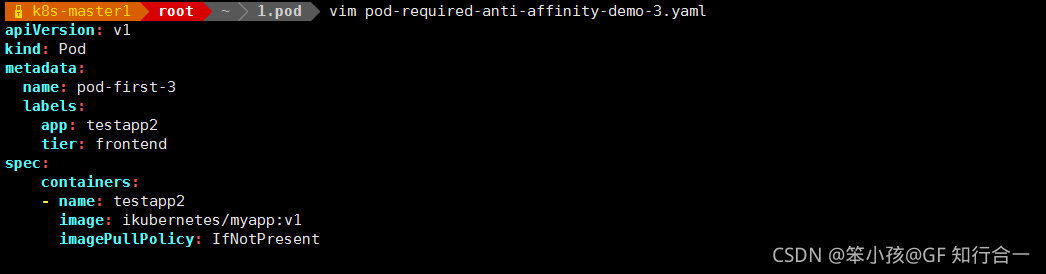 vim pod-required-anti-affinity-demo-4.yaml
vim pod-required-anti-affinity-demo-4.yaml 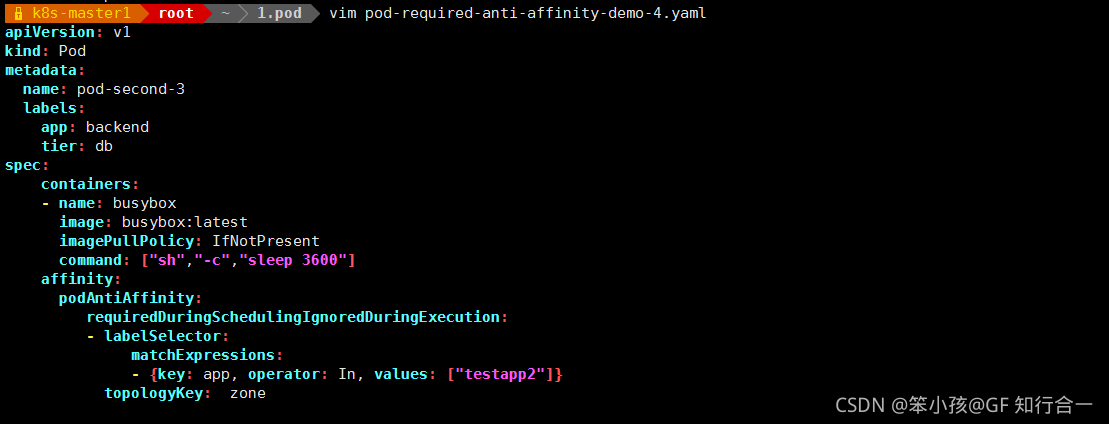
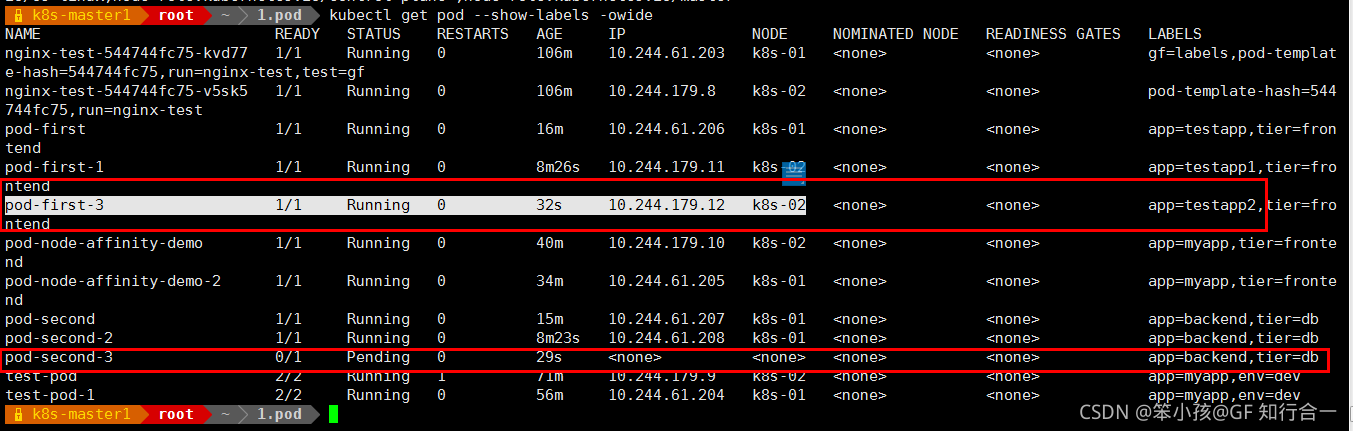
- 发现第二个节点是 pending 状态,即使2个节点都有 zone=foo 的标签,但是因为要求反亲和性 podAntiAffinity,所以就会处于 pending 状态,如果在反亲和性这个位置把 required 改成 preferred,那么也会运行。
podaffinity:pod 节点亲和性,pod 倾向于哪个 pod
nodeaffinity:node 节点亲和性,pod 倾向于哪个 node -
Pod 高级用法:污点和容忍度
-
给了节点选则的主动权,给节点打一个污点,不容忍的 pod 就运行不上来,污点就是定义在节点上的键值属性数据,可以定决定拒绝那些 pod;
taints 是键值数据,用在 node 节点上,定义污点;
tolerations 是键值数据,用在 pod 上,定义容忍度,能容忍哪些污点节点亲和性是 pod 属性,pod 亲和性也是 pod 属性;
污点是 node 节点的属性,污点定义在nodeSelector 上 -
kubectl explain node.spec.taints
KIND: Node
VERSION: v1
RESOURCE: taints <[]Object>
DESCRIPTION:
If specified, the node's taints.
The node this Taint is attached to has the "effect" on any pod that does
not tolerate the Taint.
FIELDS:
effect <string> -required- #定义排斥等级
key <string> -required-
timeAdded <string>
value <string>
taints 的 effect 用来定义对 pod 对象的排斥等级(效果):
NoSchedule:仅影响调度过程,当 pod 能容忍这个节点污点,就可以调度到当前节点,后来这个节点的污点改了,加了一个新的污点,使得之前调度的 pod 不能容忍了,那这个 pod 会怎么处理,对现存的pod 对象不产生影响
NoExecute:既影响调度过程,又影响现存的 pod 对象,如果现存的 pod 不能容忍节点后来加的污点,这个pod 就会被驱逐
PreferNoSchedule:最好不,也可以,是 NoSchedule 的柔性版本 -
在 pod 对象定义容忍度的时候支持两种操作:
1.等值密钥:key 和 value 完全匹配
2.存在性判断:key 和 effect 必须同时匹配,value 可以是空 -
在 pod 上定义的容忍度可能不止一个,在节点上定义的污点可能多个,需要琢个检查容忍度和污点能否匹配,每一个污点都能被容忍,才能完成调度,如果不能容忍怎么办,那就需要看 pod 的容忍度了
-
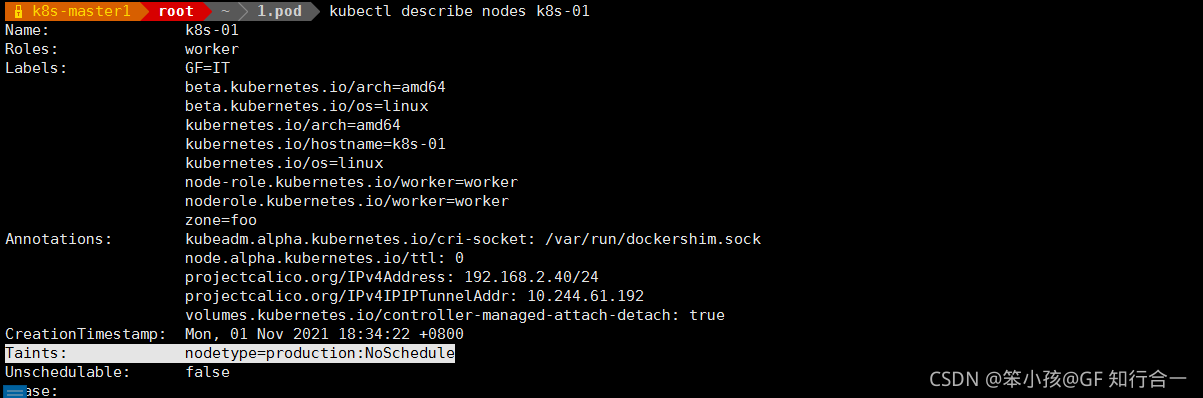
查看 master 这个节点是否有污点
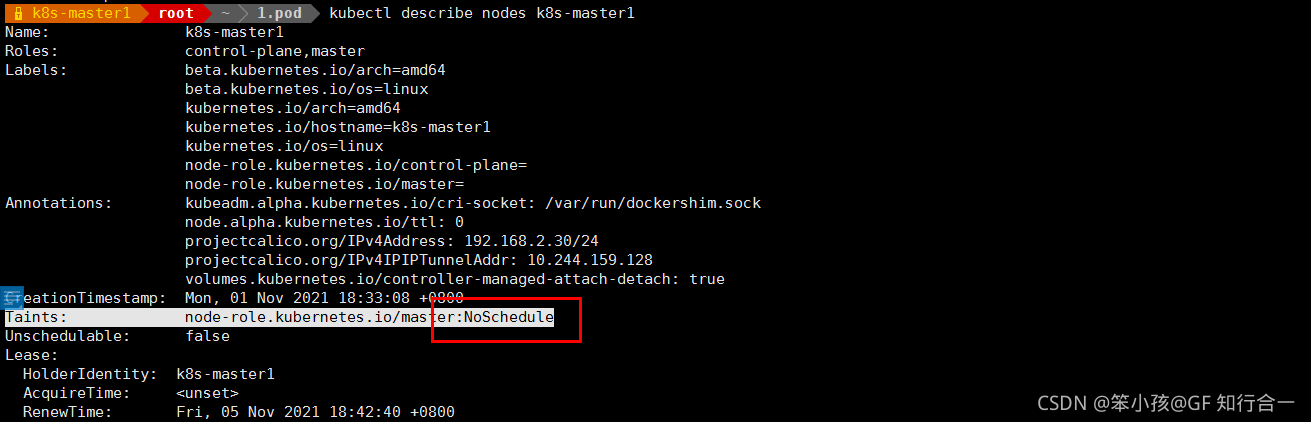
-
可以看到 master 这个节点的污点是 Noschedule
-
所以创建的 pod 都不会调度到 master 上,因为之前创建的 pod 没有设置容忍度
- kubectl describe pods kube-apiserver-k8s-master1 -n kube-system
可以看到这个 pod 的容忍度是 NoExecute 所以可以调度到 master1

-
管理节点污点
- kubectl taints --help
把 k8s-01 当成是生产环境专用的,其他 node 是测试环境
给 k8s-01 打污点,pod 如果不能容忍就不会调度过来
kubectl taint node k8s-01 node-type=production:NoSchedule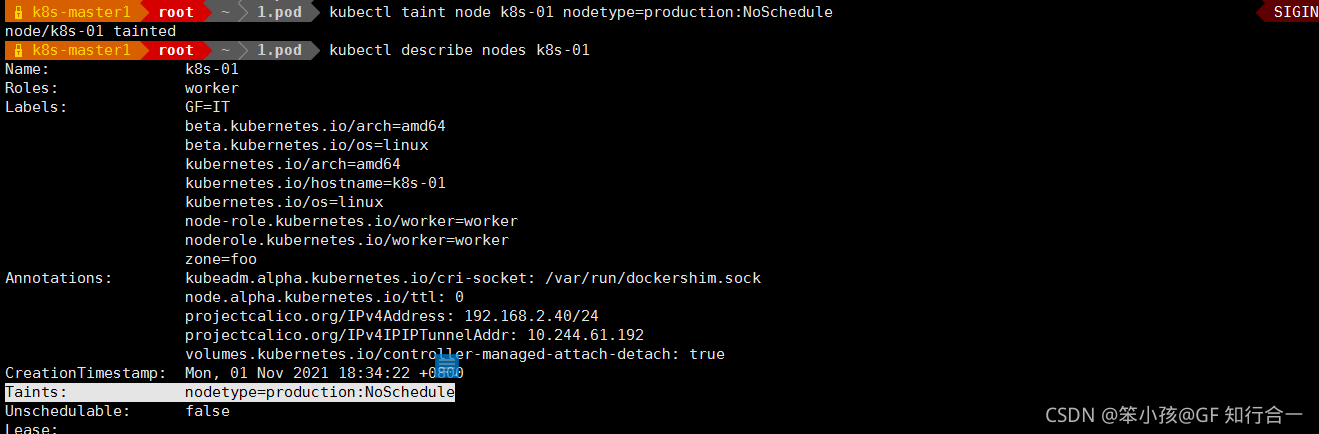
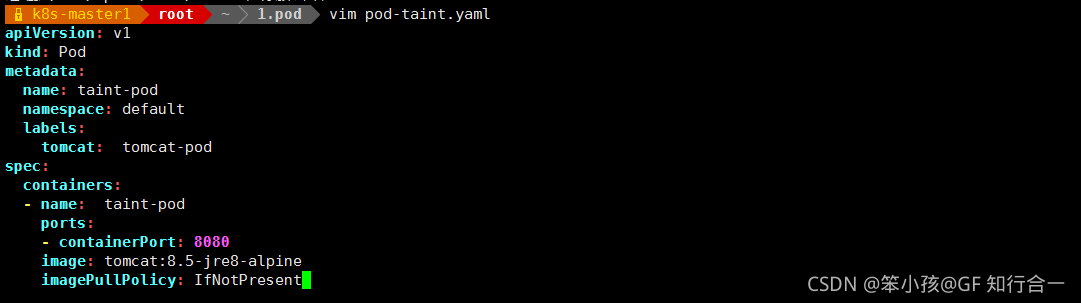
- vim pod-taint.yaml
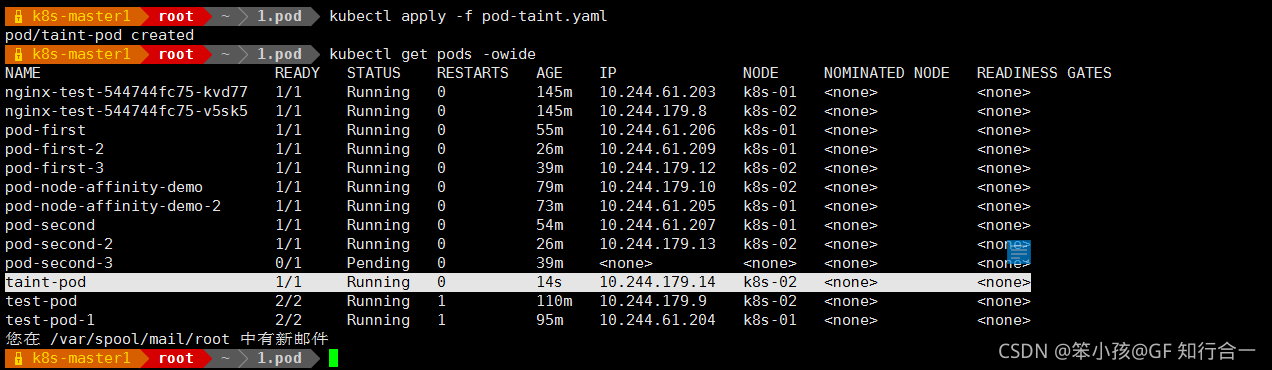
- 发现调度到了 k8s-02 上
- 给 k8s-02 也打上污点
kubectl taint node k8s-02 node-type=dev:NoExecute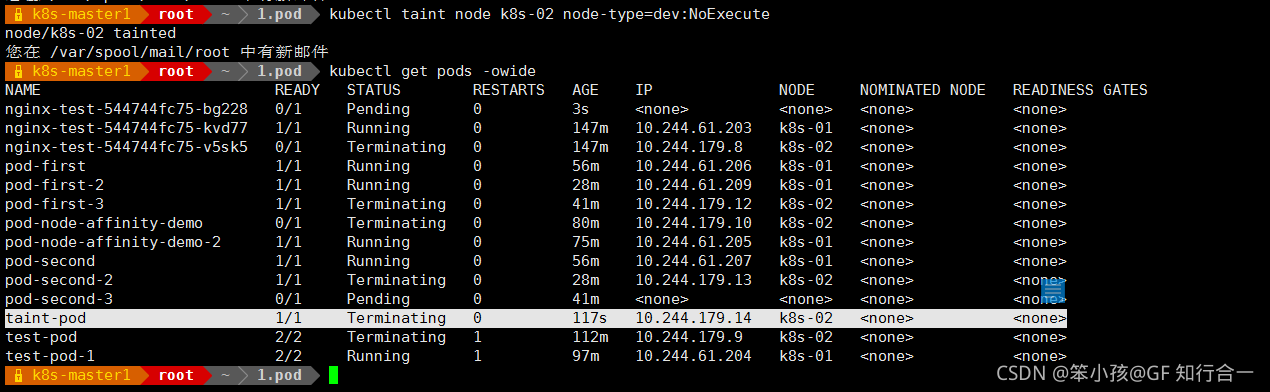
-
可以看到已经存在的 pod 节点都被撵走了
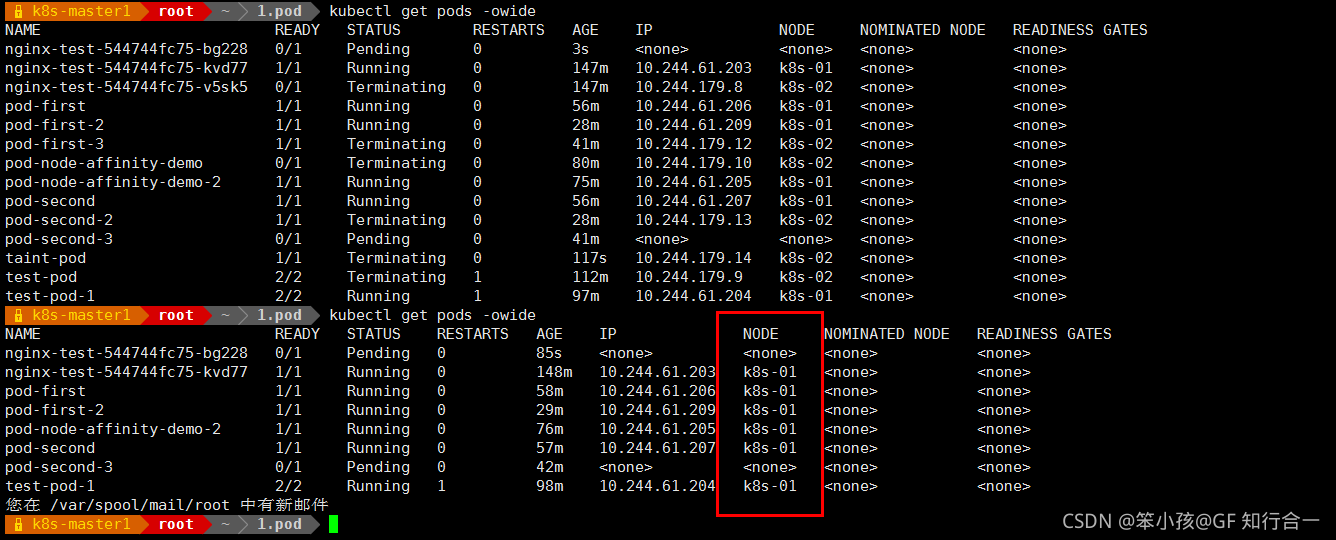
-
删除节点污点
- kubectl taint node k8s-02 node-type-
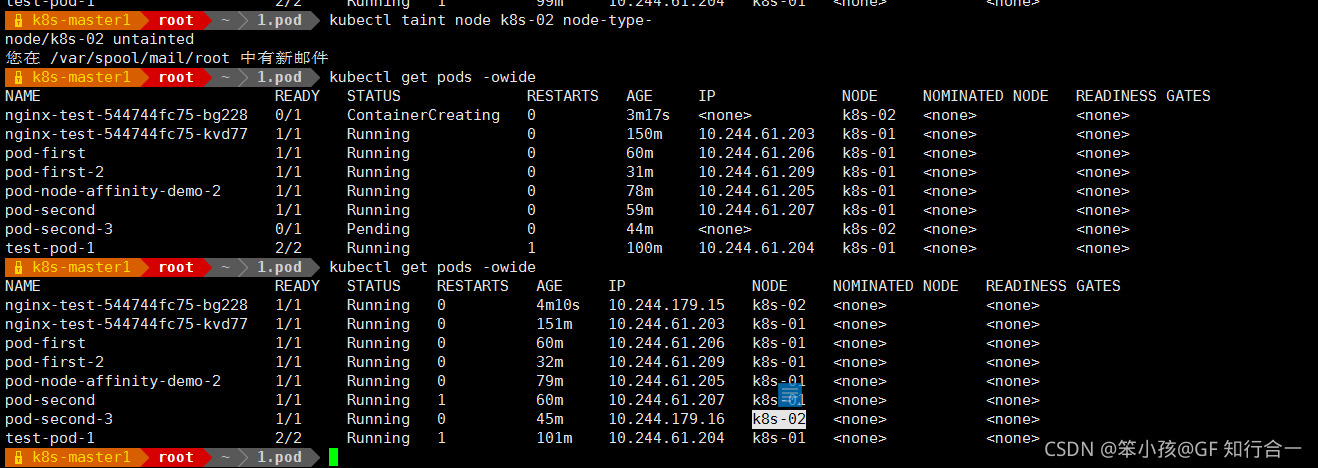
- 重新打上污点
kubectl taint node k8s-02 node-type=production:NoExecute
vim pod-demo-1.yaml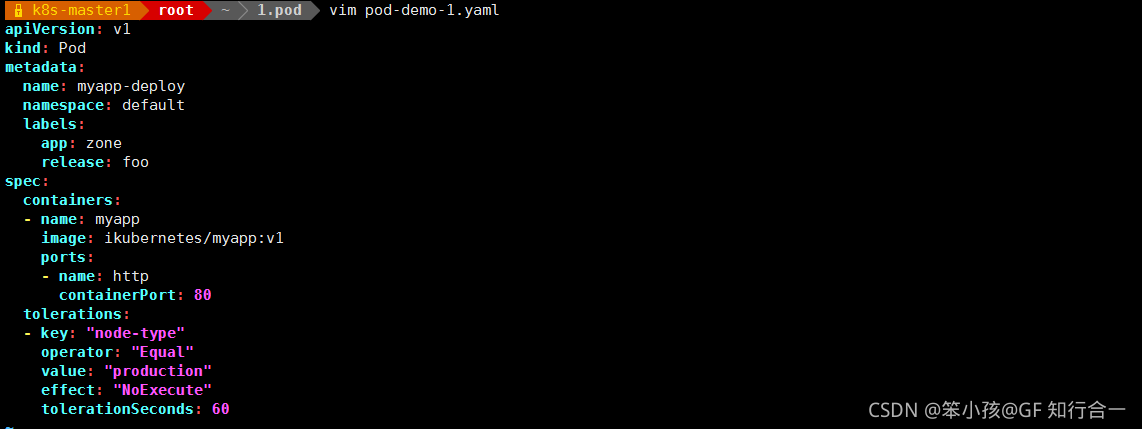
- # tolerationSeconds: 60 表示可以多存活 60 秒。Pod 才被驱逐

- 等待 60秒
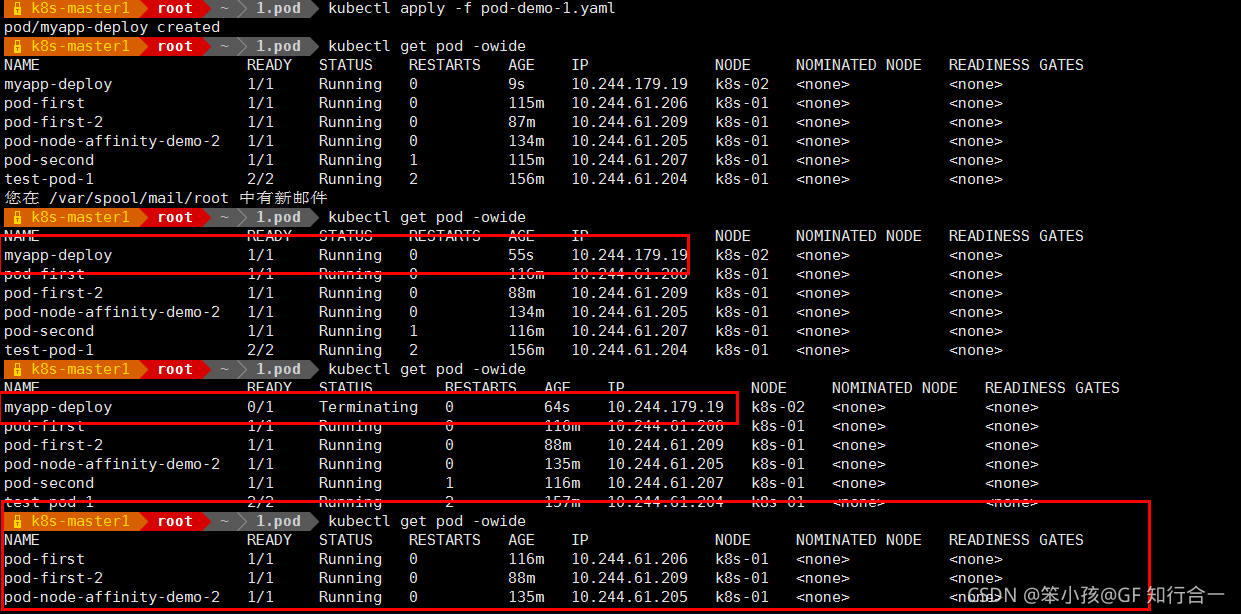
- 再次编辑
vim pod-demo-1.yaml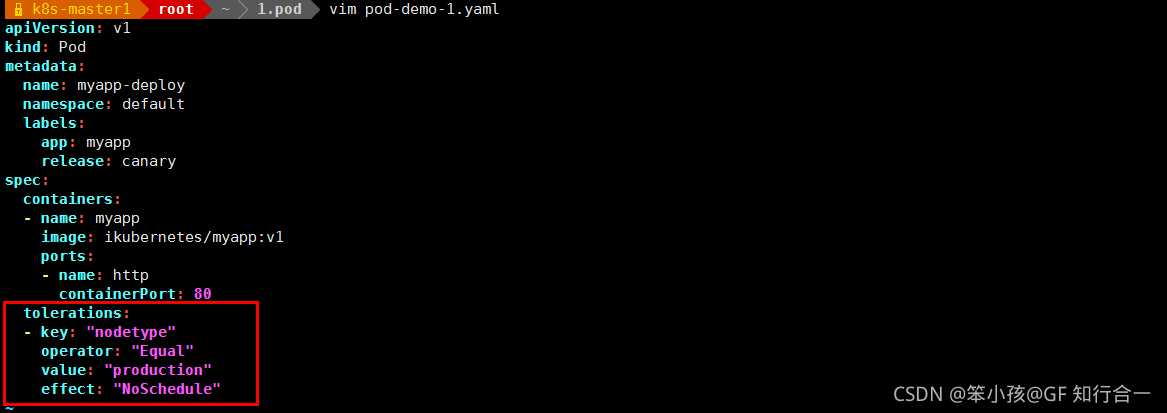
-
使用的是 equal(等值匹配),当 key 和 value,effect 必须和node 节点定义的污点完全匹配才可以
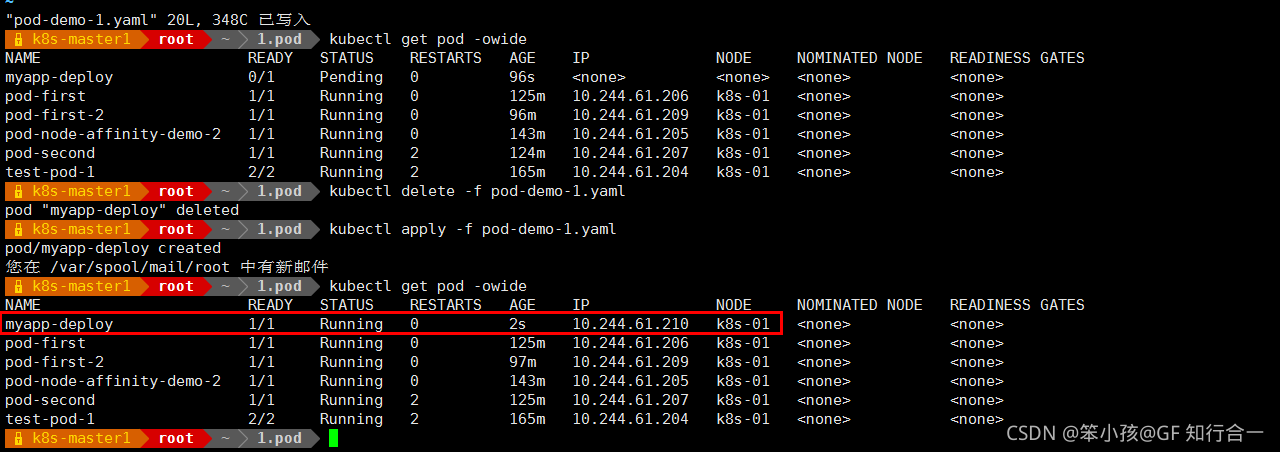
-
再次修改
vim pod-demo-1.yaml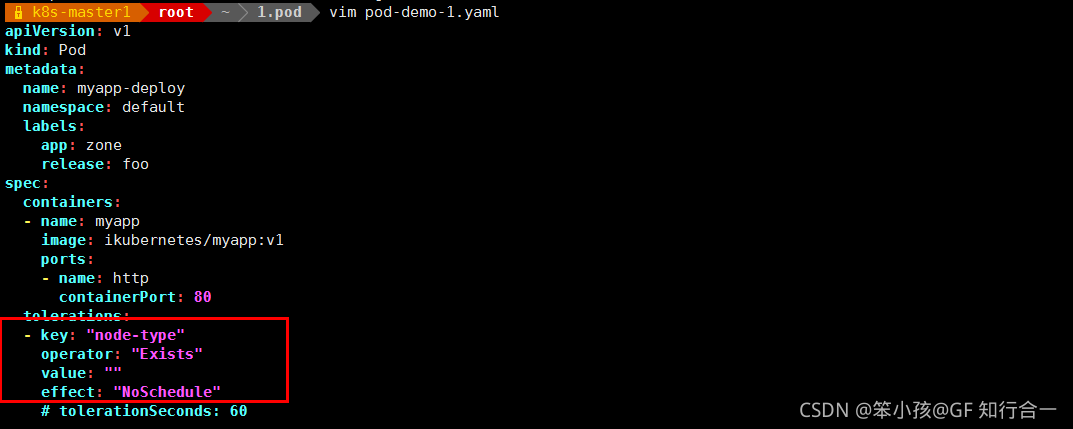
只要对应的键 node-type 是存在的,exists,其值被自动定义成通配符
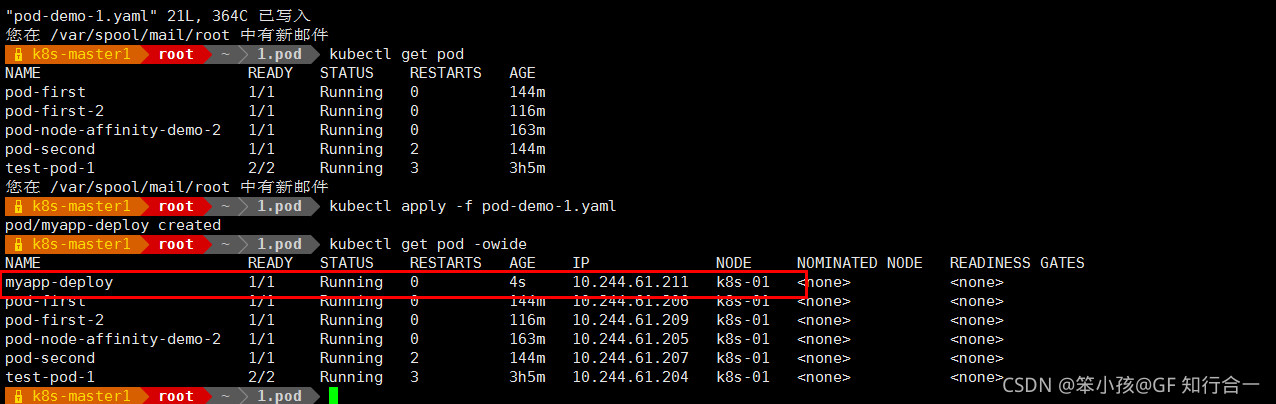
发现还是被调度到了 k8s-01 上,为了能调度到 k8s-02 上再次修改:
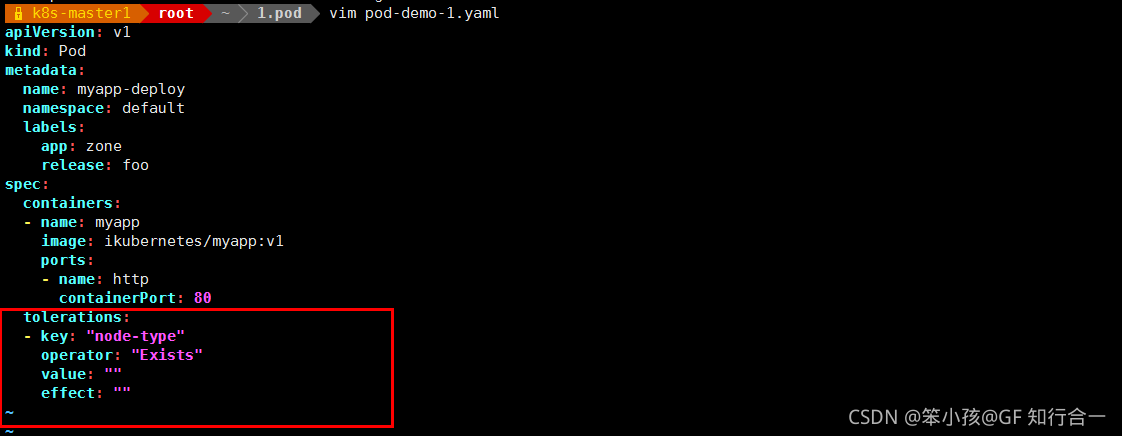
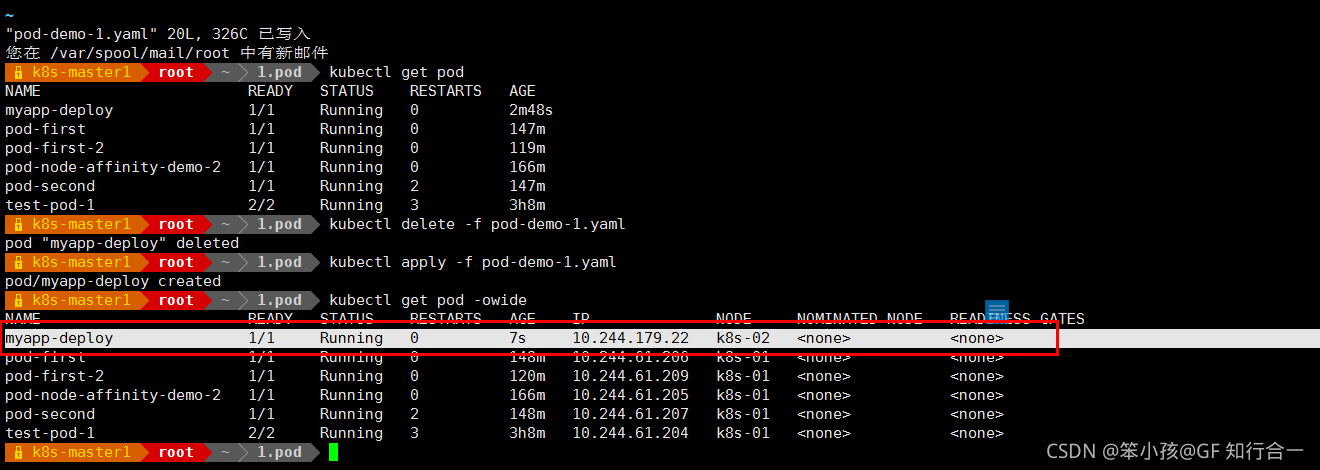
有一个 node-type 的键,不管值是什么,不管是什么效果,都能容忍,可以看到 2个 节点上都有可能有 pod 被调度
operator <string>
Operator represents a key's relationship to the value. Valid operators are
Exists and Equal. Defaults to Equal. Exists is equivalent to wildcard for
value(exists相当于值的通配符,等于没有指定), so that a pod can tolerate all taints of a particular category.
- 清空 所有 pod
kubectl delete pods --all
-
Pod 高级用法:Pod 状态和重启策略
- 常见的 pod 状态
- Pod 的 status 定义在 PodStatus 对象中,其中有一个 phase 字段。它简单描述了 Pod 在其生命周期的阶段。
- 熟悉 Pod 的各种状态对我们理解如何设置 Pod 的调度策略、重启策略是很有必要的。
- 下面是 phase 可能的值,也就是 pod 常见的状态:
挂起(Pending):我们在请求创建 pod 时,条件不满足,调度没有完成,没有任何一个节点能满足调度条件,已经创建了 pod 但是没有适合它运行的节点叫做挂起,调度没有完成,处于pending 的状态会持续一段时间:包括调度 Pod 的时间和通过网络下载镜像的时间。
运行中(Running):Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
成功(Succeeded):Pod 中的所有容器都被成功终止,并且不会再重启。
失败(Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非 0 状态退出或者被系统终止。
未知(Unknown):未知状态,所谓 pod 是什么状态是 apiserver 和运行在 pod 节点的kubelet 进行通信获取状态信息的,如果节点之上的 kubelet 本身出故障,那么 apiserver 就连不上 kubelet,得不到信息了,就会看 Unknown
扩展:还有其他状态,如下:
Evicted 状态:出现这种情况,多见于系统内存或硬盘资源不足,可 df-h 查看 docker 存储所在目录的资源使用情况,如果百分比大于 85%,就要及时清理下资源,尤其是一些大文件、docker镜像。
CrashLoopBackOff:容器曾经启动了,但可能又异常退出了
Error 状态:Pod 启动过程中发生了错误 -
pod 重启策略
- Pod 的重启策略(RestartPolicy)应用于 Pod 内的所有容器,并且仅在 Pod 所处的 Node 上由kubelet 进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet 将根据RestartPolicy 的设置来进行相应的操作。
-
Pod 的重启策略包括 Always、OnFailure 和 Never,默认值为 Always。
Always:当容器失败时,由 kubelet 自动重启该容器。
OnFailure:当容器终止运行且退出码不为 0 时,由 kubelet 自动重启该容器。
Never:不论容器运行状态如何,kubelet 都不会重启该容器。 - apiVersion: v1
kind: Pod
metadata:
name: demo-pod
namespace: default
labels:
app: myapp
spec:
restartPolicy: Always #默认即为 Always
containers:
- name: tomcat-pod-java
ports:
- containerPort: 8080
image: tomcat:8.5-jre8-alpine
imagePullPolicy: IfNotPresent
-
Pod 高级用法:Pod 生命周期
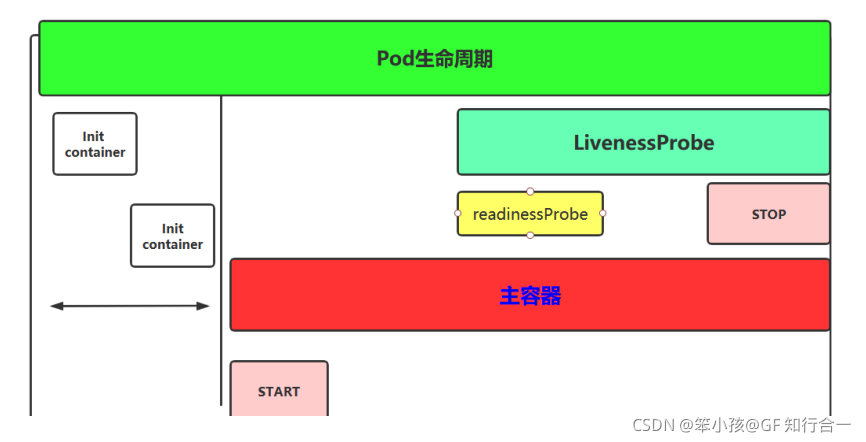
-
init 容器
- Pod 里面可以有一个或者多个容器,部署应用的容器可以称为主容器,在创建 Pod 时候,Pod 中可以有一个或多个先于主容器启动的 Init 容器,这个 init 容器就可以称为初始化容器,初始化容器一旦执行完,它从启动开始到初始化代码执行完就退出了,它不会一直存在,所以在主容器启动之前执行初始化,初始化容器可以有多个,多个初始化容器是要串行执行的,先执行初始化容器1,在执行初始化容器 2 等,等初始化容器执行完初始化就退出了,然后再执行主容器,主容器一退出,pod 就结束了,主容器退出的时间点就是 pod 的结束点,它俩时间轴是一致的;
- Init 容器就是做初始化工作的容器。可以有一个或多个,如果多个按照定义的顺序依次执行,只有所有的初始化容器执行完后,主容器才启动。由于一个 Pod 里的存储卷是共享的,所以 Init Container 里产生的数据可以被主容器使用到,Init Container 可以在多种 K8S 资源里被使用到,如 Deployment、DaemonSet, StatefulSet、Job 等,但都是在 Pod 启动时,在主容器启动前执行,做初始化工作。
- Init 容器与普通的容器区别是:
1、Init 容器不支持 Readiness,因为它们必须在 Pod 就绪之前运行完成
2、每个 Init 容器必须运行成功,下一个才能够运行
3、如果 Pod 的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止,
然而,如果 Pod 对应的 restartPolicy 值为 Never,它不会重新启动。 - 定义一个初始化容器,用来修改主容器的 pod 主机的内核参数
- 查看 initContainers 怎么定义
kubectl explain pods.spec.initContainers
initContainers:
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
-
主容器
- 容器钩子
- 初始化容器启动之后,开始启动主容器,在主容器启动之前有一个 post start hook(容器启动后钩子)和 pre stop hook(容器结束前钩子),无论启动后还是结束前所做的事我们可以把它放两个钩子,这个钩子就表示用户可以用它来钩住一些命令,来执行它,做开场前的预设,结束前的清理,如 awk 有 begin,end,和这个效果类似;
- postStart:该钩子在容器被创建后立刻触发,通知容器它已经被创建。如果该钩子对应的 hook (钩子)handler(检测)执行失败,则该容器会被杀死,并根据该容器的重启策略决定是否要重启该容器,这个钩子不需要传递任何参数。
preStop:该钩子在容器被删除前触发,其所对应的 hook handler 必须在删除该容器的请求发送给 Docker daemon 之前完成。在该钩子对应的 hook handler 完成后不论执行的结果如何,Docker daemon 会发送一个 SGTERN 信号量给 Docker daemon 来删除该容器,这个钩子不需要传递任何参数。 - 在 k8s 中支持两类对 pod 的检测,第一类叫做 livenessprobe(pod 存活性探测):存活探针主要作用是,用指定的方式检测 pod 中的容器应用是否正常运行,如果检测失败,则认为容器不健康,那么 Kubelet 将根据 Pod 中设置的 restartPolicy 来判断 Pod 是否要进行重启操作,如果容器配置中没有配置 livenessProbe,Kubelet 将认为存活探针探测一直为成功状态。
第二类是状态检 readinessprobe(pod 就绪性探测):用于判断容器中应用(服务)是否启动完成,当探测成功后才使 Pod 对外提供网络访问,设置容器 Ready 状态为 true,如果探测失败,则设置容器的 Ready 状态为 false。
-
创建 pod 需要经过哪些阶段?
当用户创建 pod 时,首先请求给 apiserver,apiserver 把创建请求的状态保存在 etcd 中;
接下来 apiserver 会请求 调度器 scheduler 来完成调度,如果调度成功,会把调度的结果(如调度到哪个节点上了,运行在哪个节点上了,把它更新到 etcd 的 pod 资源状态中)保存在 etcd 中;
一旦存到 etcd 中并且完成更新以后,如调度到 A机器上,那么 A 节点上的 kubelet 通过 apiserver 当中的状态变化知道有一些任务被执行了,所以此时此 kubelet 会拿到用户创建时所提交的清单,这个清单会在当前节点上运行或者启动这个 pod;
如果创建成功或者失败会有一个当前状态,当前这个状态会发给 apiserver,apiserver 在存到 etcd 中;
在这个过程中,etcd和 apiserver 一直在打交道,不停的交互,scheduler 也参与其中,负责调度 pod 到合适的node 节点上,这个就是 pod 的创建过程 - pod 在整个生命周期中有非常多的用户行为:
1、初始化容器完成初始化
2、主容器启动后可以做启动后钩子
3、主容器结束前可以做结束前钩子
4、在主容器运行中可以做一些健康检测,如 livenessprobe,readnessprobe
-
Pod 高级用法:Pod 容器探测深度讲解
- 容器钩子:postStart 和 preStop
postStart:容器创建成功后,运行前的任务,用于资源部署、环境准备等。
preStop:在容器被终止前的任务,用于优雅关闭应用程序、通知其他系统等。 - 演示 postStart 和 preStop 用法
......
containers:
- image: sample:v2
name: war
lifecycle:
postStart:
exec:
command:
- “cp”
- “/sample.war”
- “/app”
prestop:
httpGet:
host: monitor.com
path: /waring
port: 8080
scheme: HTTP
......
以上示例中,定义了一个 Pod,包含一个 JAVA 的 web 应用容器,其中设置了 PostStart 和 PreStop 回调函数。即在容器创建成功后,复制/sample.war 到/app 文件夹中。而在容器终止之前,发送 HTTP 请求到 http://monitor.com:8080/waring,即向监控系统发送警告。 -
优雅的删除资源对象
- 当用户请求删除含有 pod 的资源对象时(如 RC、deployment 等),K8S 为了让应用程序优雅关闭(即让应用程序完成正在处理的请求后,再关闭软件),K8S 提供两种信息通知:
1)、默认:K8S 通知 node 执行 docker stop 命令,docker 会先向容器中 PID 为 1 的进程发送系统信号 SIGTERM,然后等待容器中的应用程序终止执行,如果等待时间达到设定的超时时间,或者默认超时时间(30s),会继续发送 SIGKILL 的系统信号强行 kill 掉进程。
2)、使用 pod 生命周期(利用 PreStop 回调函数),它执行在发送终止信号之前。默认情况下,所有的删除操作的优雅退出时间都在 30 秒以内。kubectl delete 命令支持--grace-period=的选项,以运行用户来修改默认值。0 表示删除立即执行,并且立即从 API 中删除 pod。在节点上,被设置了立即结束的的 pod,仍然会给一个很短的优雅退出时间段,才会开始被强制杀死。如下:
spec:
containers:
- name: nginx-demo
image: centos:nginx
lifecycle:
preStop:
exec:
# nginx -s quit gracefully terminate while SIGTERM triggers a quick exit
command: ["/usr/local/nginx/sbin/nginx","-s","quit"]
ports:
- name: http
containerPort: 80 - 探测:livenessProbe 和 readinessProbe
- livenessProbe:存活性探测
许多应用程序经过长时间运行,最终过渡到无法运行的状态,除了重启,无法恢复。通常情况下,K8S 会发现应用程序已经终止,然后重启应用程序 pod。有时应用程序可能因为某些原因(后端服务故障等)导致暂时无法对外提供服务,但应用软件没有终止,导致 K8S 无法隔离有故障的pod,调用者可能会访问到有故障的 pod,导致业务不稳定。K8S 提供 livenessProbe 来检测应用程序是否正常运行,并且对相应状况进行相应的补救措施。
readinessProbe:就绪性探测
在没有配置 readinessProbe 的资源对象中,pod 中的容器启动完成后,就认为 pod 中的应用程序可以对外提供服务,该 pod 就会加入相对应的 service,对外提供服务。但有时一些应用程序启动后,需要较长时间的加载才能对外服务,如果这时对外提供服务,执行结果必然无法达到预期效果,影响用户体验。比如使用 tomcat 的应用程序来说,并不是简单地说 tomcat 启动成功就可以对外提供服务的,还需要等待 spring 容器初始化,数据库连接上等等。 - 目前 LivenessProbe 和 ReadinessProbe 两种探针都支持下面三种探测方法:
1、ExecAction:在容器中执行指定的命令,如果执行成功,退出码为 0 则探测成功。
2、TCPSocketAction:通过容器的 IP 地址和端口号执行 TCP 检 查,如果能够建立 TCP 连接,则表明容器健康。
3、HTTPGetAction:通过容器的 IP 地址、端口号及路径调用 HTTP Get 方法,如果响应的状态码大于等于 200 且小于 400,则认为容器健康
探针探测结果有以下值:
1、Success:表示通过检测。
2、Failure:表示未通过检测。
3、Unknown:表示检测没有正常进行。 - Pod 探针相关的属性:
- 探针(Probe)有许多可选字段,可以用来更加精确的控制 Liveness 和 Readiness 两种探针的行为
initialDelaySeconds: Pod 启动后首次进行检查的等待时间,单位“秒”。
periodSeconds: 检查的间隔时间,默认为 10s,单位“秒”。
timeoutSeconds: 探针执行检测请求后,等待响应的超时时间,默认为 1s,单位“秒”。
successThreshold: 表示探针的成功的阈值,在达到该次数时,表示成功。默认值为 1,表示只要成功一次,就算成功了。
failureThreshold: 探测失败的重试次数,重试一定次数后将认为失败,在 readiness 探针中,Pod 会被标记为未就绪,默认为 3,最小值为 1。
两种探针区别:
ReadinessProbe 和 livenessProbe 可以使用相同探测方式,只是对 Pod 的处置方式不同:
readinessProbe 当检测失败后,将 Pod 的 IP:Port 从对应的 EndPoint 列表中删除。
livenessProbe 当检测失败后,将杀死容器并根据 Pod 的重启策略来决定作出对应的措施。
-
Pod 探针使用
- LivenessProbe 探针使用示例
(1)、通过 exec 方式做健康探测
vim liveness-exec.yaml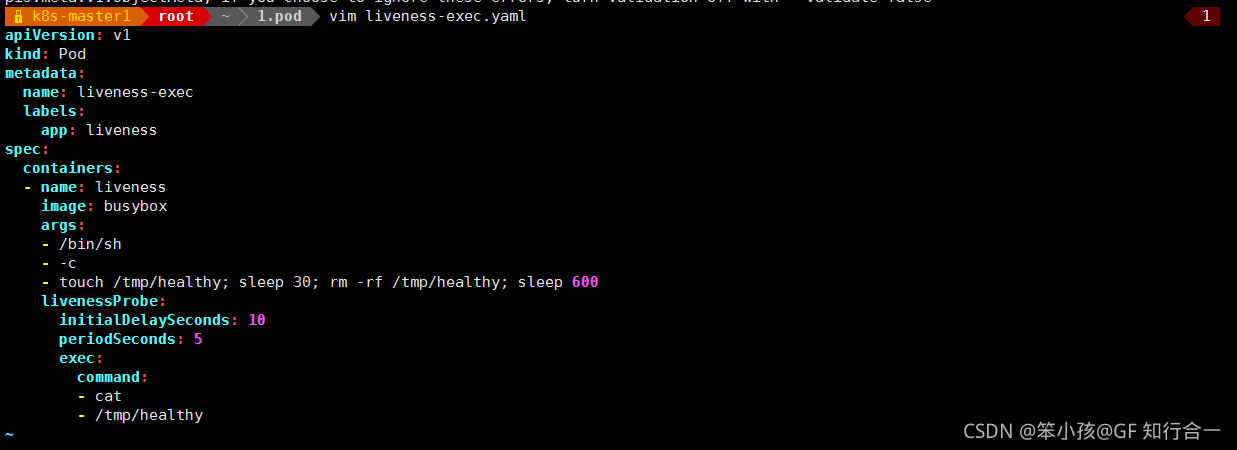 容器启动设置执行的命令:
容器启动设置执行的命令:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
容器在初始化后,首先创建一个 /tmp/healthy 文件,然后执行睡眠命令,睡眠 30 秒,到时间后执行删除 /tmp/healthy 文件命令。而设置的存活探针检检测方式为执行 shell 命令,用cat 命令输出 healthy 文件的内容,如果能成功执行这条命令,存活探针就认为探测成功,否则探测失败。在前 30 秒内,由于文件存在,所以存活探针探测时执行 cat /tmp/healthy 命令成功执行。30 秒后 healthy 文件被删除,所以执行命令失败,Kubernetes 会根据 Pod 设置的重启策略来判断,是否重启 Pod。
- (2)、通过 HTTP 方式做健康探测
vim liveness-http.yaml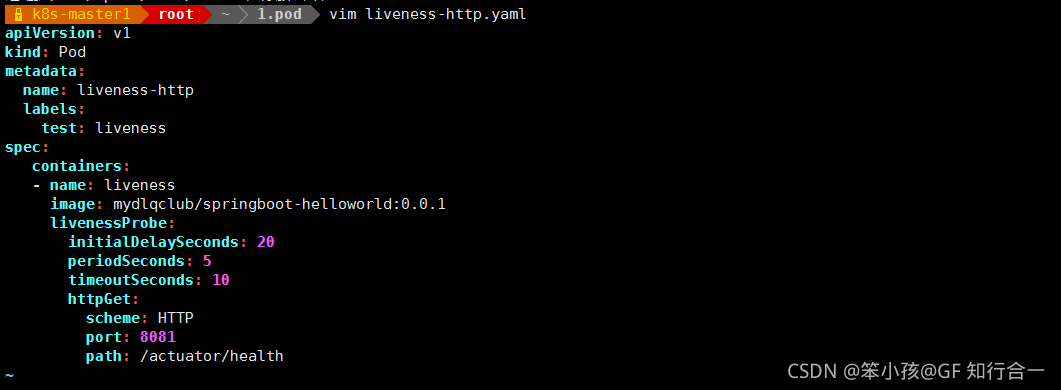
上面 Pod 中启动的容器是一个 SpringBoot 应用,其中引用了 Actuator 组件,提供了/actuator/health 健康检查地址,存活探针可以使用 HTTPGet 方式向服务发起请求,请求8081 端口的 /actuator/health 路径来进行存活判断:
任何大于或等于 200 且小于 400 的代码表示探测成功。
任何其他代码表示失败。
如果探测失败,则会杀死 Pod 进行重启操作。
httpGet 探测方式有如下可选的控制字段:
scheme: 用于连接 host 的协议,默认为 HTTP。
host:要连接的主机名,默认为 Pod IP,可以在 http request head 中设置 host 头部。
port:容器上要访问端口号或名称。
path:http 服务器上的访问 URI。
httpHeaders:自定义 HTTP 请求 headers,HTTP 允许重复 headers。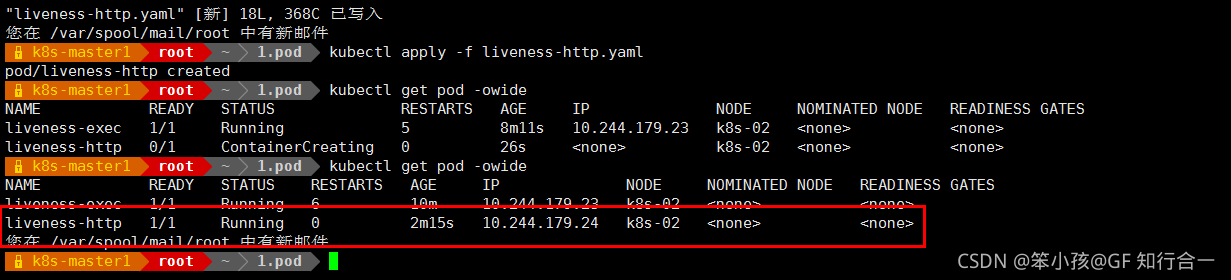
- 在线拉取镜像时间会久一点
- (3)、通过 TCP 方式做健康探测
vim liveness-tcp.yaml
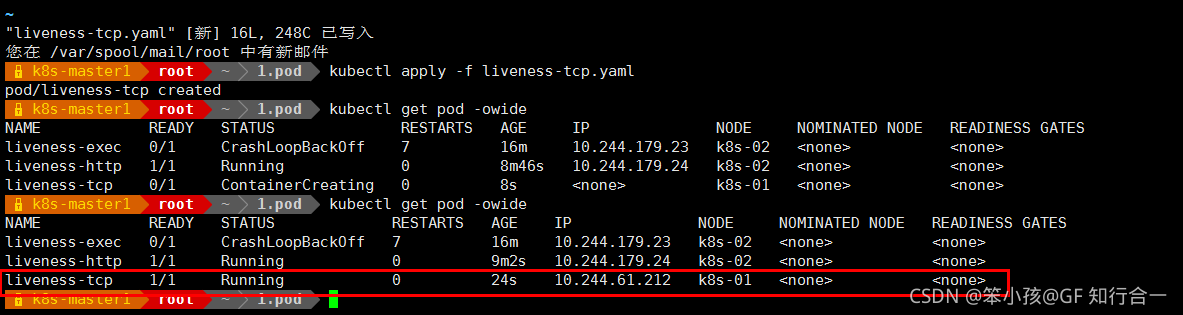
TCP 检查方式和 HTTP 检查方式非常相似,在容器启动 initialDelaySeconds 参数设定的时间后,kubelet 将发送第一个 livenessProbe 探针,尝试连接容器的 80 端口,如果连接失败则将杀死 Pod 重启容器。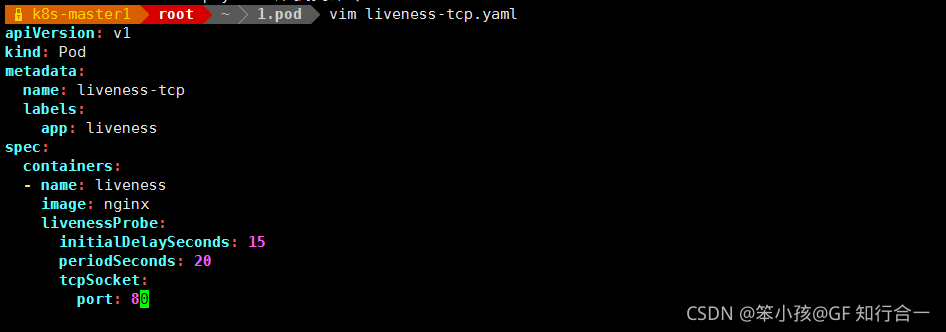
- ReadinessProbe 探针使用
- Pod 的 ReadinessProbe 探针使用方式和 LivenessProbe 探针探测方法一样,也是支持三种,只是一个是用于探测应用的存活,一个是判断是否对外提供流量的条件。这里用一个Springboot 项目,设置 ReadinessProbe 探测 SpringBoot 项目的 8081 端口下的/actuator/health 接口,如果探测成功则代表内部程序以及启动,就开放对外提供接口访问,否则内部应用没有成功启动,暂不对外提供访问,直到就绪探针探测成功。
- vim readiness-exec.yaml
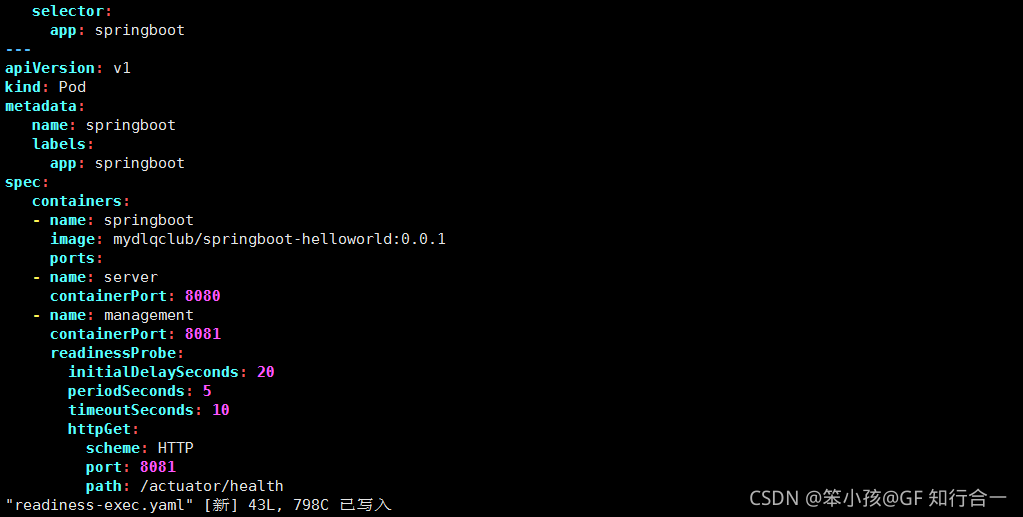
vim readiness-exec.yaml
apiVersion: v1
kind: Service
metadata:
name: springboot
labels:
app: springboot
spec:
type: NodePort
ports:
- name: server
port: 8080
targetPort: 8080
apiVersion: v1
kind: Service
metadata:
name: springboot
labels:
app: springboot
spec:
type: NodePort
ports:
- name: server
port: 8080
targetPort: 8080
nodePort: 31180
- name: management
port: 8081
targetPort: 8081
nodePort: 31181
selector:
app: springboot
---
apiVersion: v1
kind: Pod
metadata:
name: springboot
labels:
app: springboot
spec:
containers:
- name: springboot
image: mydlqclub/springboot-helloworld:0.0.1
ports:
- name: server
containerPort: 8080
- name: management
containerPort: 8081
readinessProbe:
initialDelaySeconds: 20
periodSeconds: 5
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 8081
path: /actuator/health - ReadinessProbe + LivenessProbe 配合使用
- 一般程序中需要设置两种探针结合使用,并且也要结合实际情况,来配置初始化检查时间和检测间隔,下面列一个简单的 SpringBoot 项目的 Deployment 例子。
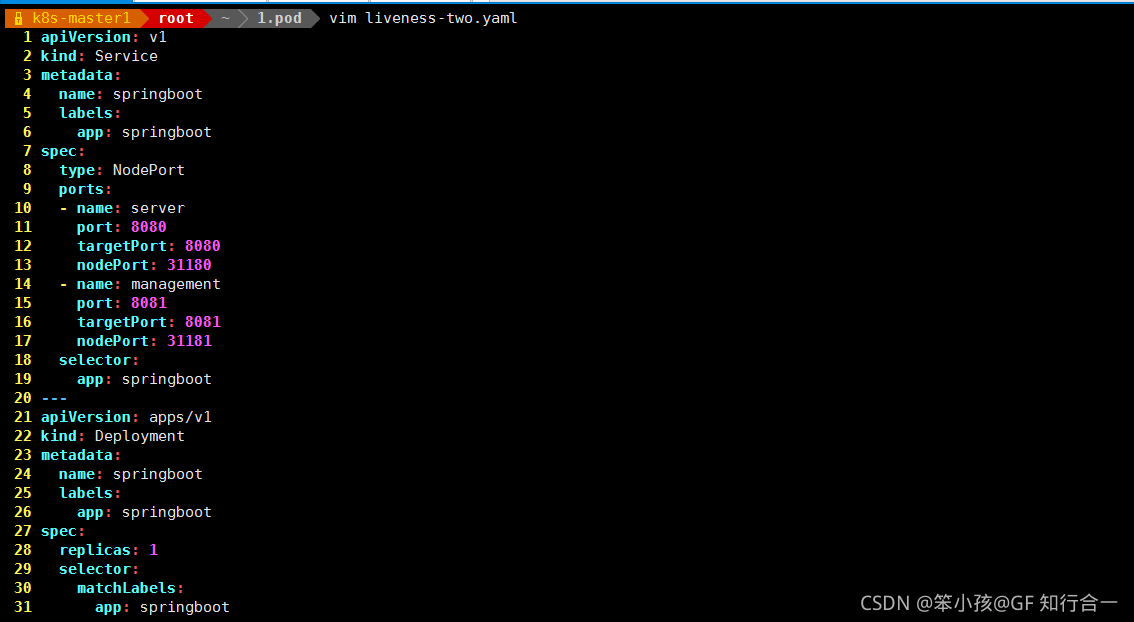
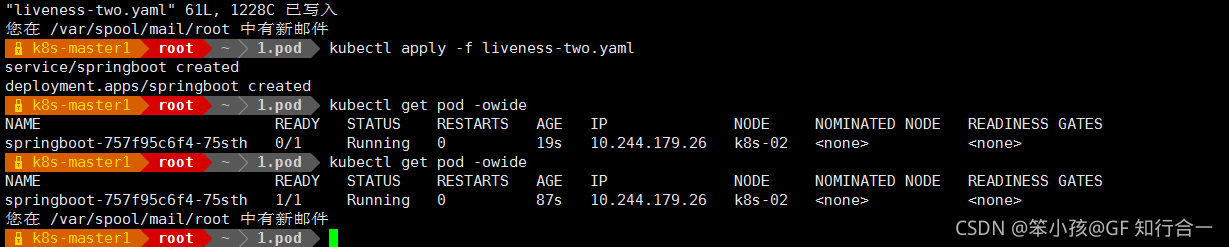
vim liveness-two.yaml
apiVersion: v1
kind: Service
metadata:
name: springboot
labels:
app: springboot
spec:
type: NodePort
ports:
- name: server
port: 8080
targetPort: 8080
nodePort: 31180
- name: management
port: 8081
targetPort: 8081
nodePort: 31181
selector:
app: springboot
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: springboot
labels:
app: springboot
spec:
replicas: 1
selector:
matchLabels:
app: springboot
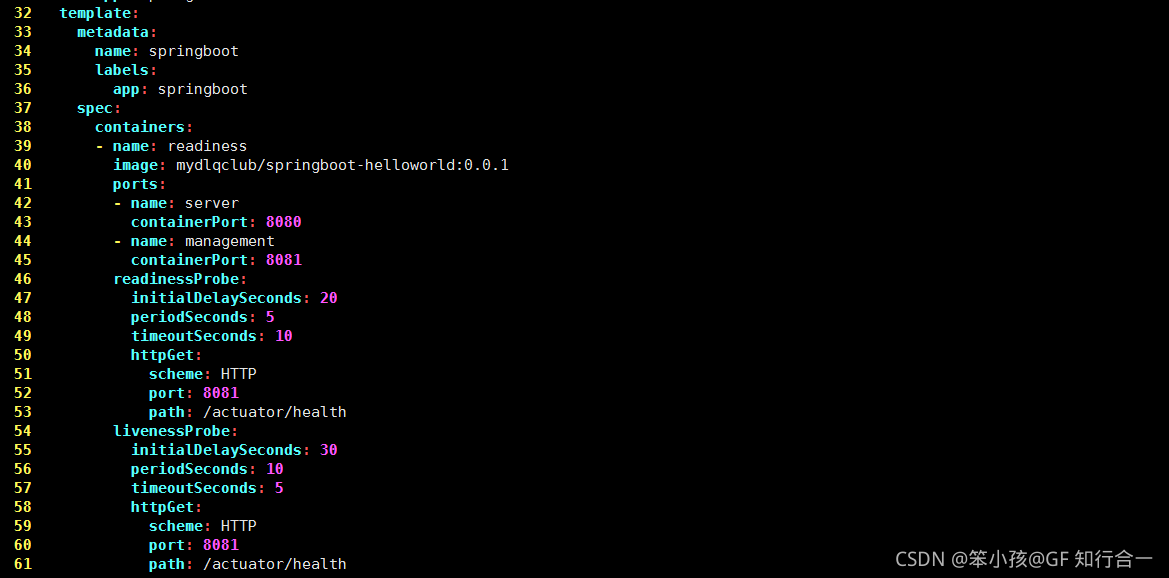
template:
metadata:
name: springboot
labels:
app: springboot
spec:
containers:
- name: readiness
image: mydlqclub/springboot-helloworld:0.0.1
ports:
- name: server
containerPort: 8080
- name: management
containerPort: 8081
readinessProbe:
initialDelaySeconds: 20
periodSeconds: 5
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 8081
path: /actuator/health
livenessProbe:
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
httpGet:
scheme: HTTP
port: 8081
path: /actuator/health
目录 返回
首页