| 首先在三个节点机上下载calico的命令管理工具calicoctl(百度云下载地址:https://pan.baidu.com/s/1pKKTGbL 密码:r7sm)
[root@node-1 ~]# wget http://www.projectcalico.org/builds/calicoctl
[root@node-1 ~]# chmod +x calicoctl
[root@node-1 ~]# mv calicoctl /usr/local/bin/
[root@node-1 ~]# calicoctl --help //查看帮助信息
启动Calico服务
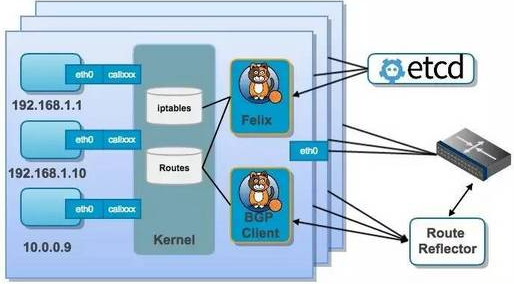
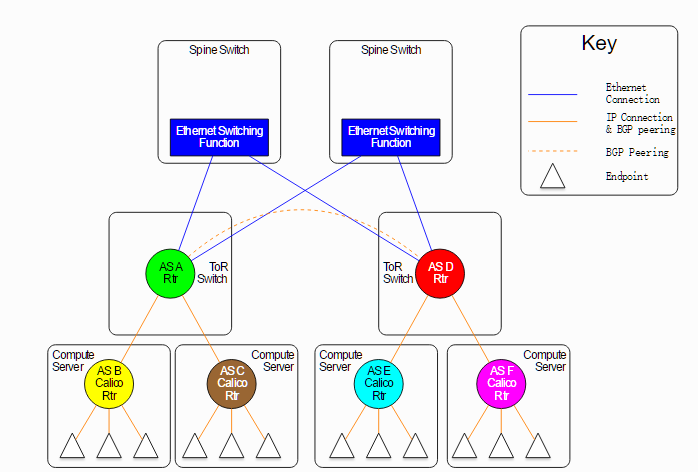
在Docker环境中Calico服务是做为容器来运行的,使用host的网络配置。所有容器配置使用Calico服务,做为calico节点互相通信。
Calico在每个主机上通过一个自己的container与其他主机或者网络通讯,即calico-node的container,这个container里面包含了Bird路由管理、Felix协议等。
千万别忘了在三个节点上都要下载calico的node镜像
(可以先在一个节点上下载镜像,然后将镜像通过docker save导出保存到本地,再将镜像拷贝到其他节点上通过docker load导入,这样对于其他节点来说,比使用docker pull要快)
[root@node-1 ~]# docker pull calico/node
[root@node-1 ~]# docker pull calico/node-libnetwork
[root@node-1 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/calico/node latest 1e0928760e74 11 hours ago 255.2 MB
docker.io/nginx latest 3448f27c273f 6 days ago 109.4 MB
docker.io/calico/node-libnetwork latest 84d99cab9fc4 7 months ago 70.2 MB
下面分别在三个节点上,以Docker方式启动calico-node(这个命令会执行一段时间,耐心等待......)
node-1
[root@node-1 ~]# calicoctl node run --ip=182.48.115.233
Running command to load modules: modprobe -a xt_set ip6_tables
Enabling IPv4 forwarding
.......
Using node name: node-1
Starting libnetwork service
Calico node started successfully
node-2
[root@node-2 ~]# calicoctl node run --ip=182.48.115.236
node-3
[root@node-3 ~]# calicoctl node run --ip=182.48.115.239
可以在三个节点上查看calico-node启动情况
[root@node-1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2ac613b1af9a quay.io/calico/node:latest "start_runit" 22 seconds ago Up 17 seconds calico-node
[root@node-1 ~]# ps -ef|grep calico
root 14339 14336 0 15:43 ? 00:00:00 svlogd -tt /var/log/calico/bird6
root 14340 14336 0 15:43 ? 00:00:00 bird6 -R -s /var/run/calico/bird6.ctl -d -c /etc/calico/confd/config/bird6.cfg
root 14341 14337 0 15:43 ? 00:00:00 svlogd /var/log/calico/confd
root 14342 14337 0 15:43 ? 00:00:00 confd -confdir=/etc/calico/confd -interval=5 -watch -no-discover --log-level=debug -node=http://127.0.0.1:2379 -client-key= -client-cert= -client-ca-keys=
root 14343 14334 0 15:43 ? 00:00:00 svlogd /var/log/calico/felix
root 14344 14334 2 15:43 ? 00:00:03 calico-felix
root 14346 14338 0 15:43 ? 00:00:00 svlogd /var/log/calico/libnetwork
root 14349 14335 0 15:43 ? 00:00:00 svlogd -tt /var/log/calico/bird
root 14350 14335 0 15:43 ? 00:00:00 bird -R -s /var/run/calico/bird.ctl -d -c /etc/calico/confd/config/bird.cfg
root 14597 13854 0 15:45 pts/2 00:00:00 grep --color=auto calico
查看节点状态信息(在三个节点上都可以查看)
[root@node-1 ~]# calicoctl node status
Calico process is running.
IPv4 BGP status
+----------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+----------------+-------------------+-------+----------+-------------+
| 182.48.115.236 | node-to-node mesh | up | 07:47:20 | Established |
| 182.48.115.239 | node-to-node mesh | up | 07:52:55 | Established |
+----------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
[root@node-2 ~]# calicoctl node status
Calico process is running.
IPv4 BGP status
+----------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+----------------+-------------------+-------+----------+-------------+
| 182.48.115.233 | node-to-node mesh | up | 07:46:19 | Established |
| 182.48.115.239 | node-to-node mesh | up | 07:51:54 | Established |
+----------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
[root@node-3 ~]# calicoctl node status
Calico process is running.
IPv4 BGP status
+----------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+----------------+-------------------+-------+----------+-------------+
| 182.48.115.233 | node-to-node mesh | up | 09:51:54 | Established |
| 182.48.115.236 | node-to-node mesh | up | 09:51:54 | Established |
+----------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
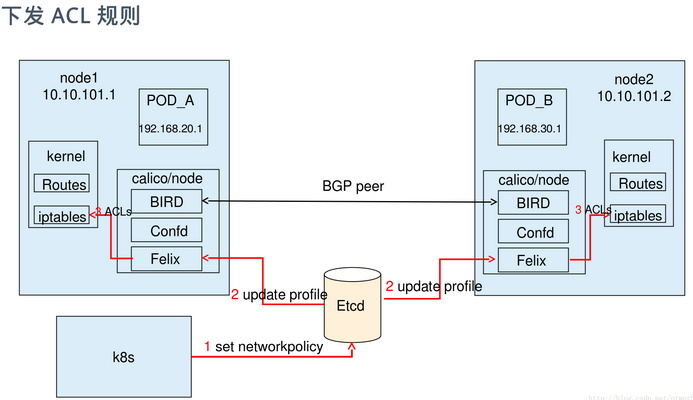
使用calicoctl创建ipPool
在启动别的容器之前,我们需要配置一个IP地址池带有ipip和nat-outgoing选项。所以带有有效配置的容器就可以访问互联网,在每个节点上运行下面的命令:
先查看calico的ip池(任意一个节点上都能查看)
[root@node-1 ~]# calicoctl get ipPool
CIDR
192.168.0.0/16
fd80:24e2:f998:72d6::/64
[root@node-1 ~]# calicoctl get ippool -o wide
CIDR NAT IPIP
192.168.0.0/16 true false
fd80:24e2:f998:72d6::/64 true false
上面查出的192.168.0.0/16是calico默认的网络。
可以使用命令"calicoctl delete ippool 192.168.0.0/16"删除calico默认的网络,这是非必要操作,可以保留calico默认的网络!
现在开始在三个节点机器上使用calicoctl创建ipPool
创建ip pool首先定义一个资源文件ipPool.yaml,如下:
node-1节点机器上
[root@node-1 ~]# vim ipPool.yaml
apiVersion: v1
kind: ipPool
metadata:
cidr: 192.168.10.1/24
spec:
ipip:
enabled: true
nat-outgoing: true
disabled: false
[root@node-1 ~]# calicoctl create -f ipPool.yaml
Successfully created 1 'ipPool' resource(s)
[root@node-1 ~]# calicoctl get ippool -o wide
CIDR NAT IPIP
192.168.0.0/16 true false
192.168.10.1/24 true true //两个true,说明使用了IPIP
fd80:24e2:f998:72d6::/64 true false
--------------------------------------------------------------------------------
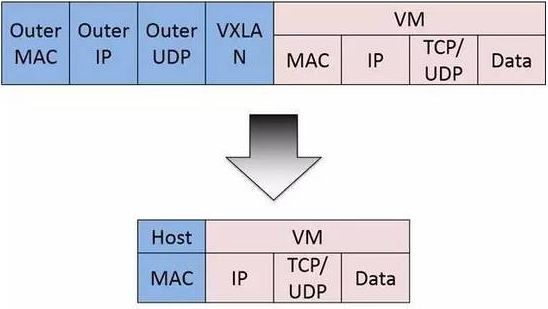
上面在创建ipPool的时候,使用了IPIP。也可以选择不使用IPIP,如下:(这里我选择的是使用IPIP)
[root@node-1 ~]# vim ipPool.yaml
apiVersion: v1
kind: ipPool
metadata:
cidr: 192.168.10.1/24
spec:
ipip:
enabled: false
nat-outgoing: true
disabled: false
-------------------------------------------------------------------------------
同理,node-2节点机器上
[root@node-2 ~]# vim ipPool.yaml
apiVersion: v1
kind: ipPool
metadata:
cidr: 192.168.20.1/24
spec:
ipip:
enabled: true
nat-outgoing: true
disabled: false
[root@node-2 ~]# calicoctl create -f ipPool.yaml
Successfully created 1 'ipPool' resource(s)
[root@node-2 ~]# calicoctl get ippool -o wide
CIDR NAT IPIP
192.168.0.0/16 true false
192.168.10.1/24 true true
192.168.20.1/24 true true
fd80:24e2:f998:72d6::/64 true false
node-3节点机器上
[root@node-3 ~]# vim ipPool.yaml
apiVersion: v1
kind: ipPool
metadata:
cidr: 192.168.30.1/24
spec:
ipip:
enabled: true
nat-outgoing: true
disabled: false
[root@node-3 ~]# calicoctl create -f ipPool.yaml
Successfully created 1 'ipPool' resource(s)
[root@node-3 ~]# calicoctl get ippool -o wide
CIDR NAT IPIP
192.168.0.0/16 true false
192.168.10.1/24 true true
192.168.20.1/24 true true
192.168.30.1/24 true true
fd80:24e2:f998:72d6::/64 true false
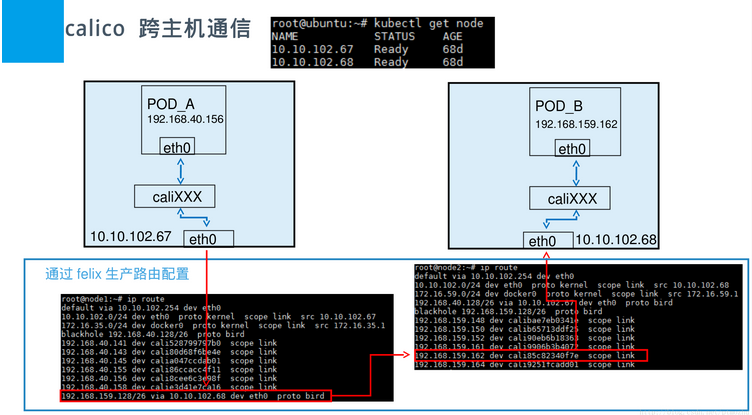
由上面可以看出,当三个节点都创建了ipPool后,再次查看calico的ip池,就会发现三个节点的Docker网桥网络ip都显示出来了
|