Apache Kylin 2.5.0安装和使用
1.背景
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
Apache Kylin官网:http://kylin.apache.org/
Kylin的官网上每个版本的都提供两个包一个for HBase的一个for CDH的,根据自己的环境选择下载对应的kylin的安装包,否则后面会报各种各样的错误。
Kylin依赖于hadoop的环境:
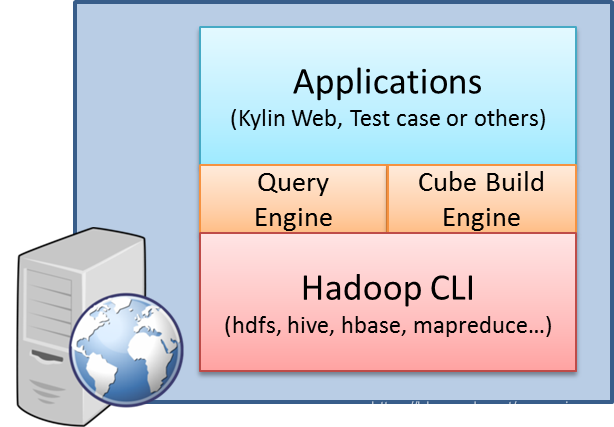
所以在安装kylin之前需要先安装好Hadoop的环境(包括hdfs、hive、hbase等);而且Kylin对各组件的版本要求很严格,只要有组件版本不匹配就会导致Kylin无法正常使用。本文选择使用如下版本的组件:
Kylin:2.5.0(apache-kylin-2.5.0-bin-hbase1x)
JDK:1.8.0_162
Hadoop:hadoop-2.7.6
HBase:1.2.7
Hive:1.2.2
Hadoop注意开启JobHistoryServer,yarn的资源配置(default队列)要足够(主要是内存),JDK、Hadoop和HBase的安装可以在网上搜索相关资料,下面主要介绍Hive和Kylin的安装。
2.Hive安装
2.1 Mysql安装配置
这里选择使用mysql来保存hive的元数据信息,所以需要安装mysql,centos 7.2上面直接使用yum -y install mariadb mariadb-server来进行安装,然后启动mariadb,并设置开机自启动:
# systemctl start mariadb
# systemctl enable mariadb
设置root密码
# mysqladmin -u root password 123456
然后进入mysql(mysql -uroot -p123456),创建数据库并设置相关权限:
mysql> CREATE DATABASE hive; # 创建hive数据库
mysql> grant all on hive.* to hive@'%' identified by '123456'; # 给hive的权限,123456是数据库的密码
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> grant all on hive.* to hive@localhost identified by '123456';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
2.2 Hive安装配置
Hive安装包拷贝到/opt/目录下,然后解压。配置好各环境变量:
# vim /etc/profile
# set hive environment
#java
export JAVA_HOME=/opt/jdk1.8.0_162/
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#hadoop
export HADOOP_HOME=/opt/hadoop-2.7.6
#hbase
export HBASE_HOME=/opt/hbase-1.2.7
#hive
export HIVE_HOME=/opt/apache-hive-1.2.2-bin
#export HCAT_HOME=/opt/apache-hive-1.2.2-bin/hive-hcatalog
#kylin
export KYLIN_HOME=/opt/apache-kylin-2.5.0-bin-hbase1x
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$HIVE_HOME/bin:$KYLIN_HOME:$PATH
# source /etc/profile
修改hive配置文件:
# cd $HIVE_HOME/conf/
# cp hive-default.xml.template hive-site.xml
# cp hive-env.sh.template hive-env.sh
# cp hive-exec-log4j.properties.template hive-exec-log4j.properties
# cp hive-log4j.properties.template hive-log4j.properties
#vi hive-site.xml
主要配置了以下配置项:
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>location of default database for the warehouse,Hive在HDFS上的根目录</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/hive/exec</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/hive/downloadedsource</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
配置文件中的几个目录需要创建下:
Hdfs上创建:
# hadoop fs -mkdir -p /hive/warehouse
# hadoop fs -mkdir -p /hive/logs
# hadoop fs -mkdir -p /hive/tmp
本地创建:
# mkdir -p /hive/logs
# mkdir -p /hive/exec
# mkdir -p /hive/downloadedsource
另外hive中没有mysql jdbc的jar包,需要单独下载,下载地址:https://dev.mysql.com/downloads/connector/j/
下载后解压,然后将jar包拷贝到hive的lib目录下。
另外需要注意的是配置项hive.metastore.uris,Kylin是用 HCatalog 读取Hive表的,而HCatalog用 hive.metastore.uris 创建HiveMetaStoreClient 得到元信息,所以这里要配置hive的metastore的地址信息。
然后配置两个log4j的配置文件:
hive.log.dir=/hive/logs
最后进入到hive的bin目录启动hive:
# ./hive --service metastore &
2.3 Hive测试
直接运行在控制台输入hive进入到hive的控制台页面,执行下show tables,看看hive是否正常。
2.4 可能遇到的问题
错误描述
Caused by: MetaException(message:Version information not found in metastore. )
解决办法
修改conf/hive-site.xml 中的 “hive.metastore.schema.verification” 值为 false 即可解决 “Caused by: MetaException(message:Version information not found in metastore. )”
错误描述
配置好hive并启动两个必要后台进程metastore和hiveserver2后,启动hive时可能会遇到Required table missing : "DBS`" in Catalog "" Schema "这样的错误。因为在此实验环境中,hive的元数据保存在远程的mysql中,所以该错误意思是:在远程的数据库中没有找到相应的数据对象。
解决办法
在配置文件hive-sit.xml中,将datanucleus.schema.autoCreateAll的值改为true,
这个属性的含义是:当元数据库中必要的数据对象不存在是,会自动创建。
3. Kylin安装使用
3.1 配置安装
Kylin使用的是apache-kylin-2.5.0-bin-hbase1x的二进制包,拷贝到/opt/目录,然后解压。然后进入到/opt/apache-kylin-2.5.0-bin-hbase1x/conf目录修改配置文件kylin.properties。
# vi kylin.properties
# 根据实际环境进行配置
kylin.env.hadoop-conf-dir=/opt/hadoop-2.7.6/etc/hadoop
kylin.engine.spark-conf.spark.master=yarn
kylin.engine.spark-conf.spark.submit.deployMode=cluster
kylin.engine.spark-conf.spark.yarn.queue=default
kylin.engine.spark-conf.spark.driver.memory=2G
kylin.engine.spark-conf.spark.executor.memory=4G
kylin.engine.spark-conf.spark.yarn.executor.memoryOverhead=1024
kylin.engine.spark-conf.spark.executor.instances=2
kylin.engine.spark-conf.spark.executor.cores=1
kylin.engine.spark-conf.spark.shuffle.service.enabled=false
kylin.engine.spark-conf.spark.network.timeout=600
kylin.engine.spark-conf.spark.eventLog.enabled=true
kylin.engine.spark-conf.spark.hadoop.dfs.replication=2
kylin.engine.spark-conf.spark.hadoop.mapreduce.output.fileoutputformat.compress=true
kylin.engine.spark-conf.spark.hadoop.mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DefaultCodec
kylin.engine.spark-conf.spark.io.compression.codec=org.apache.spark.io.SnappyCompressionCodec
kylin.engine.spark-conf.spark.eventLog.dir=hdfs:///kylin/spark-history
kylin.engine.spark-conf.spark.history.fs.logDirectory=hdfs:///kylin/spark-history
kylin.engine.spark-conf.spark.yarn.archive=hdfs://d120:9000/kylin/spark/spark-libs.jar
上传spark的jar包:
jar cv0f spark-libs.jar -C $KYLIN_HOME/spark/jars/ .
hadoop fs -mkdir -p /kylin/spark/
hadoop fs -put spark-libs.jar /kylin/spark/
配置完成后,进到bin目录下执行./check-env.sh, ./find-hbase-dependency.sh,./find-hive-dependency.sh检查环境是否OK,环境OK后启动kylin:
# ./kylin.sh start
启动后查看日志有无报错(logs/kylin.log和logs/kylin.out),没有报错就可以登录kylin的web界面开始使用kylin。
3.2 Web使用
登陆kylin:http://<ip>:7070/kylin(User: ADMIN Pass: KYLIN)
看下System页面是不是OK,组件版本不对会导致这个页面加载失败,没报错的话下面就可以跑一下kylin中的例子。
执行./bin/sample.sh,执行完会提示:
Sample cube is created successfully in project 'learn_kylin'.
Restart Kylin Server or click Web UI => System Tab => Reload Metadata to take effect
#这句话的意思是 例子cube已成成功创建在了工程名称叫'learn_kylin'里面了
#重启kylin或者通过webUI => System选项卡=> 重新导入元数据信息
查看Hive default库中的表,多了五张表:

然后到web页面进行操作来创建cube:
1.Reload Metadata

2.Build Cube
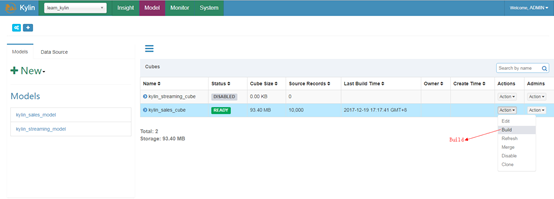
3.Finish Build
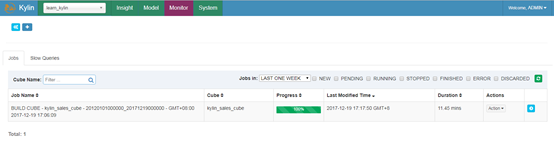
到这里cube就创建完了,可以执行下select语句来查询
select part_dt, sum(price) as total_selled, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt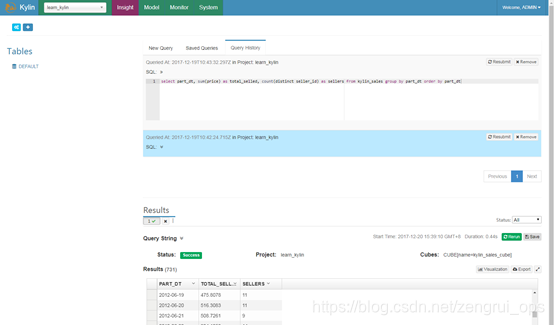
其他像Cube的设计、优化、流式构建等功能的使用,可直接参见kylin的官方文档,http://kylin.apache.org/docs/,目前kylin的支持的数据源有hive、kafka和jdbc源,其流式构建是使用hadoop(mr)消费kafka的数据来增量构建cube segment,目前都需要用户去触发每次的构建,而且构建都是分钟以上的延时。
目前ebay做了一个New Kylin Streaming的feature,该feature说是实时性达到毫秒级,可以水平扩展(Streaming Receiver),每个Streaming Receiver处理速度达到44000 events/s,目前已经在整理代码,即将合并到新版本的kylin中,等kylin的下个版本(2.6.0)发布估计就有该功能了,到时候可以测试使用一下。
3.3 Kylin调试
在使用过程中难免会遇到各种各样的问题,这时候可能就需要来进行调试,Kylin可以通过以下方式进行远程调试:
在kylin安装目录下,修改bin目录下的kylin.sh启动脚本:
# vi bin/kylin.sh
hbase ${KYLIN_EXTRA_START_OPTS} \
-Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager \
-Dlog4j.configuration=file:${KYLIN_HOME}/conf/kylin-server-log4j.properties \
-Dorg.apache.tomcat.util.buf.UDecoder.ALLOW_ENCODED_SLASH=true \
-Dorg.apache.catalina.connector.CoyoteAdapter.ALLOW_BACKSLASH=true \
-Djava.endorsed.dirs=${tomcat_root}/endorsed \
-Dcatalina.base=${tomcat_root} \
-Dcatalina.home=${tomcat_root} \
-Djava.io.tmpdir=${tomcat_root}/temp \
-Dkylin.hive.dependency=${hive_dependency} \
-Dkylin.hbase.dependency=${hbase_dependency} \
-Dkylin.kafka.dependency=${kafka_dependency} \
-Dkylin.spark.dependency=${spark_dependency} \
-Dkylin.hadoop.conf.dir=${kylin_hadoop_conf_dir} \
-Dspring.profiles.active=${spring_profile} \
-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=9001 \
org.apache.hadoop.util.RunJar ${tomcat_root}/bin/bootstrap.jar org.apache.catalina.startup.Bootstrap start >> ${KYLIN_HOME}/logs/kylin.out 2>&1 & echo $! > ${KYLIN_HOME}/pid &
然后在idea中使用远程调试连接服务器的9001端口进行相关调试,当然也可以搭建开发环境来进行本地的调试。
目录 返回
首页