一次kubernetes calico网络组件的异常状态问题排查
k8s新增节点组件启动成功但是calico启动不成功节点无法加入集群
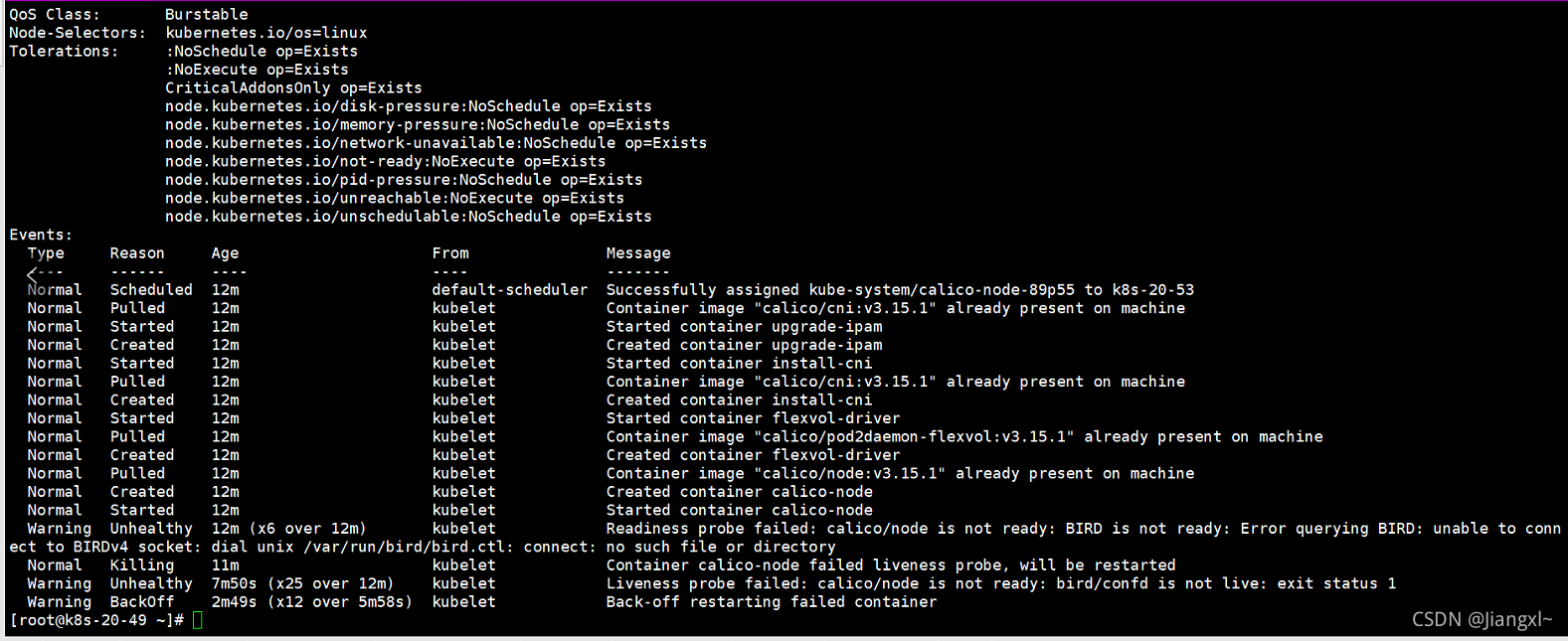
新增了master和node节点,启动完相关组件之后,calico组件一直处于CrashLoopBackOff状态,calico组件pod报错内容如下
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 12m default-scheduler Successfully assigned kube-system/calico-node-89p55 to k8s-20-53
Normal Pulled 12m kubelet Container image "calico/cni:v3.15.1" already present on machine
Normal Started 12m kubelet Started container upgrade-ipam
Normal Created 12m kubelet Created container upgrade-ipam
Normal Started 12m kubelet Started container install-cni
Normal Pulled 12m kubelet Container image "calico/cni:v3.15.1" already present on machine
Normal Created 12m kubelet Created container install-cni
Normal Started 12m kubelet Started container flexvol-driver
Normal Pulled 12m kubelet Container image "calico/pod2daemon-flexvol:v3.15.1" already present on machine
Normal Created 12m kubelet Created container flexvol-driver
Normal Pulled 12m kubelet Container image "calico/node:v3.15.1" already present on machine
Normal Created 12m kubelet Created container calico-node
Normal Started 12m kubelet Started container calico-node
Warning Unhealthy 12m (x6 over 12m) kubelet Readiness probe failed: calico/node is not ready: BIRD is not ready: Error querying BIRD: unable to connect to BIRDv4 socket: dial unix /var/run/bird/bird.ctl: connect: no such file or directory
Normal Killing 11m kubelet Container calico-node failed liveness probe, will be restarted
Warning Unhealthy 7m50s (x25 over 12m) kubelet Liveness probe failed: calico/node is not ready: bird/confd is not live: exit status 1
Warning BackOff 2m49s (x12 over 5m58s) kubelet Back-off restarting failed container
calico的pod日志如下,连接apiserver一直是超时
root@k8s-20-49 ~]# kubectl logs -f calico-node-89p55 -n kube-system
2021-09-16 00:56:52.987 [INFO][9] startup/startup.go 299: Early log level set to info
2021-09-16 00:56:52.987 [INFO][9] startup/startup.go 315: Using NODENAME environment for node name
2021-09-16 00:56:52.987 [INFO][9] startup/startup.go 327: Determined node name: k8s-20-53
2021-09-16 00:56:52.991 [INFO][9] startup/startup.go 359: Checking datastore connection
2021-09-16 00:57:22.992 [INFO][9] startup/startup.go 374: Hit error connecting to datastore - retry error=Get https://10.0.0.1:443/api/v1/nodes/foo: dial tcp 10.0.0.1:443: i/o timeout
2021-09-16 00:57:53.993 [INFO][9] startup/startup.go 374: Hit error connecting to datastore - retry error=Get https://10.0.0.1:443/api/v1/nodes/foo: dial tcp 10.0.0.1:443: i/o timeout
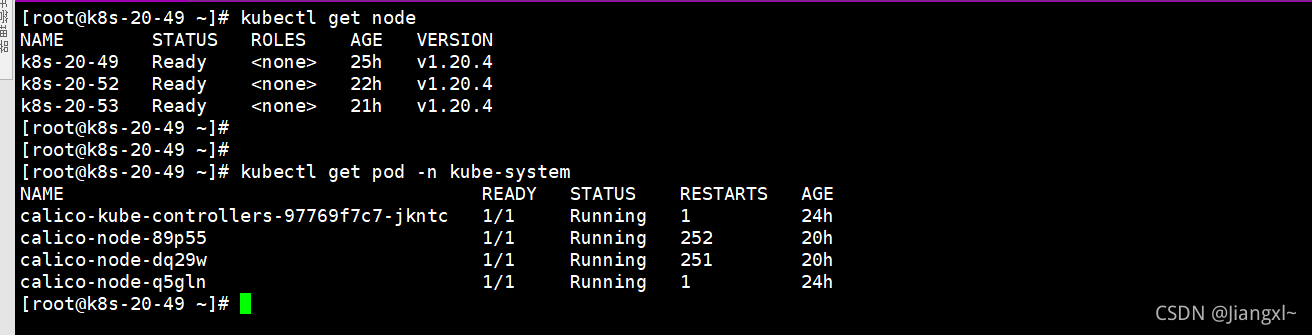
calico组件并没有成功运行,但是其状态却为running,这点非常诡异

紧接着去看k8s各个node节点,发现有问题的新node节点的状态却也是Ready状态

根据这两个日志报错以及可靠的信息进行分析,经过n次的反复排查和尝试(重新安装、百度各种报错信息),最终定位问题可能存在的原因有三点:
- 1、由于新节点的IP地址没有在apsierver证书文件的hosts字段里,从而使calico组件产生报错,节点无法成功加入集群
- 2、新节点的kube-proxy组件没有部署或者没有启动,就先启动了kubelet,并且master组件也授权加入了集群,但此时没有kube-proxy的加入,无法解析新的node节点,因此就会导致calico组件无法正常启动,从而无法加集群
- 3、新节点IP地址存在于apiserver的证书文件里,kube-proxy服务也都全部启动成功,但是calico依旧报上面的错误,这个现象的处理方法就是重启所有master以及node节点上的kube-apiserver、kubelet、kube-proxy服务,从而得到处理
经过以上三种现象的种种处理后,kubernetes新节点一切准备就绪
目录 返回
首页