安装elasticsearch集群
认识elasticsearch
最近在做一个关于spark整合Elasticsearch的项目,闲暇时便在自己机器上安装了一下elasticsearch集群。关于elasticserarch,这里简单做一下介绍:它 是一个实时分布式搜索和分析引擎。它让你以前所未有的速度处理大数据成为可能。它的底层是基于Lucene实现的一个搜索引擎,关于Lucene知识,我在四年前写过几篇文章,大家可以看一下。
Luncen介绍
Luncen分词器的使用
安装
环境: JDK1.7.55+
elasticsearch-2.3.1.tar.gz
- 安装jdk(1.7.55以上)建议直接jdk1.8.20或更高
- 上传elasticsearch-2.3.1.tar.gz安装包
- 利用tar命令解压到指定的目录下
- 利用vim 修改config/elasticsearch.yml文件,修改内容主要有一下几点
a.#集群名称,通过组播的方式通信,通过名称判断属于哪个集群
cluster.name: bigdata(这里是集群名称)
b.#节点名称,要唯一
node.name: hadoop-master(这里填写别名,一般写自己的机器名即可)
c.#数据存放位置
path.data: /data/es/data (存放数据的路径)
d.#日志存放位置 (这里也可不用修改,有一个默认位置)
path.logs: /data/es/logs
e.#es绑定的ip地址
network.host: 192.168.2.852
f.#初始化时可进行选举的节点 (这里填写参加选举的节点即可,我只有三台,就全部列上去了)
discovery.zen.ping.unicast.hosts: ["hadoop-master", "hadoop-node1", "hadoop-node2"]
- 复制到其他主机,然后修改上边改动的东西 network.host: node.name:等
scp -r elasticsearch-2.3.1 hadoop-node1:/usr/local/
scp -r elasticsearch-2.3.1 hadoop-node2:/usr/local/
- 启动服务(多台都要启动)
/usr/local/elasticsearch-2.3.1/bin/elasticsearch -d
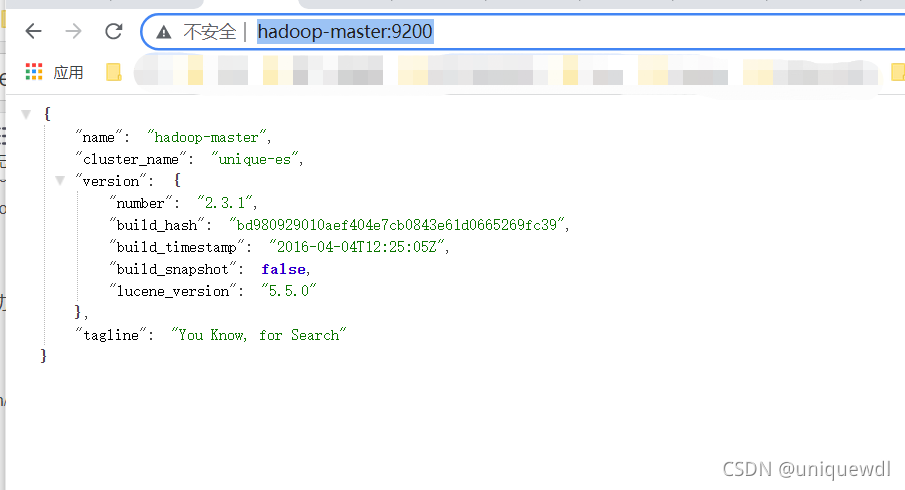
- 验证
http://hadoop-master:9200/
安装插件
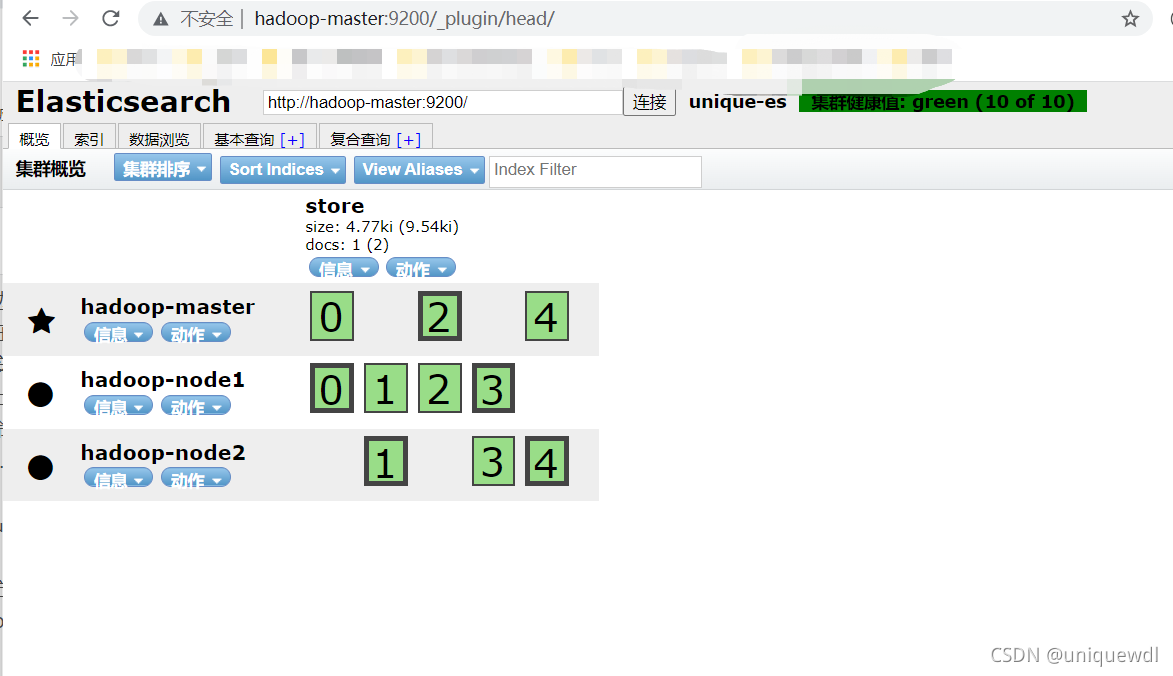
上边展示方式很不友好,所以需要一款图形化界面来展示数据。这里我们需要下载一个压缩包上传到服务器elasticsearch-head-master.zip,然后通过离线安装的方式来进行安装插件,具体安装方式如下:
1.上传到指定位置
2.命令安装 切换到bin目录下
eg:./plugin install file:///home/bigdata/elasticsearch-head-master.zip
./plugin install file:///home/bigdata/elasticsearch-head-master.zip [插件上传的目录]
3.访问浏览器可以看到管理页面
http://hadoop-master:9200/_plugin/head
注意点
- 启动elasticsearch不能用root账号,我们可以通过如下操作来进行创建一个普通账户并授权.
- jdk版本尽量不要低于1.8
useradd unique
#为unique用户添加密码:
echo 123456 | passwd --stdin unique
#将unique添加到sudoers
echo "uniqueALL = (root) NOPASSWD:ALL" | tee /etc/sudoers.d/unique
chmod 0440 /etc/sudoers.d/unique
#解决sudo: sorry, you must have a tty to run sudo问题,在/etc/sudoer注释掉 Default requiretty 一行
sudo sed -i 's/Defaults requiretty/Defaults:bigdata !requiretty/' /etc/sudoers
结束语
上述就是关于linux安装elasticsearch集群的全部内容,如果有帮助大家可以点赞收藏,有条件的可以互粉一波哦,如有不足之处请指点。
目录 返回
首页