LVS+Heartbeat 高可用集群方案操作记录
之前分别介绍了LVS基础知识和Heartbeat基础知识, 今天这里简单说下LVS+Heartbeat实现高可用web集群方案的操作说明.
Heartbeat 项目是 Linux-HA 工程的一个组成部分,它实现了一个高可用集群系统。心跳服务和集群通信是高可用集群的两个关键组件,在 Heartbeat 项目里,由 heartbeat 模块实现了这两个功能。
Heartbeat的高可用集群采用的通信方式是udp协议和串口通信,而且heartbeat插件技术实现了集群间的串口、多播、广播和组播通信。它实现了HA 功能中的核心功能——心跳,将Heartbeat软件同时安装在两台服务器上,用于监视系统的状态,协调主从服务器的工作,维护系统的可用性。它能侦测服务器应用级系统软件、硬件发生的故障,及时地进行错误隔绝、恢复;通过系统监控、服务监控、IP自动迁移等技术实现在整个应用中无单点故障,简单、经济地确保重要的服务持续高可用性。 Heartbeat采用虚拟IP地址映射技术实现主从服务器的切换对客户端透明的功能。但是单一的heartbeat是无法提供健壮的服务的,所以这里结合使用lvs进行负载均衡。
LVS是Linux Virtual Server的简写, 意即Linux虚拟服务器,是一个虚拟的服务器集群系统。说到lvs就得提到ipvs (ipvsadm命令),ipvs 是 lvs集群系统的核心软件,它的主要作用是安装在 Load Balancer 上,把发往 Virtual IP 的请求转发到 Real Server 上。
ldirectord是配合lvs作为一种健康检测机制,要不负载均衡器在节点挂掉后依然没有检测的功能。
案例架构草图如下:
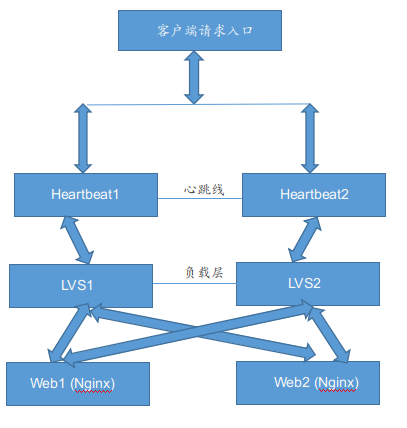
1) 基本环境准备 (centos6.9系统)
172.16.60.206(eth0) HA主节点(ha-master) heartbeat, ipvsadm, ldirectord 172.16.60.207(eth0) HA备节点(ha-slave) heartbeat, ipvsadm, ldirectord 172.16.60.111 VIP地址 172.16.60.204(eth0) 后端节点1(rs-204) nginx, realserver 172.16.60.205(eth0) 后端节点2(rs-205) nginx, realserver 1) 关闭防火墙和selinux (四台节点机都操作) [root@ha-master ~]# /etc/init.d/iptables stop [root@ha-master ~]# setenforce 0 [root@ha-master ~]# vim /etc/sysconfig/selinux SELINUX=disabled 2) 设置主机名和绑定hosts (两台HA节点机器都操作) 主节点操作 [root@ha-master ~]# hostname ha-master [root@ha-master ~]# vim /etc/sysconfig/network HOSTNAME=ha-master [root@ha-master ~]# vim /etc/hosts 172.16.60.206 ha-master 172.16.60.207 ha-slave 备节点操作 [root@ha-slave ~]# hostname ha-slave [root@ha-slave ~]# vim /etc/sysconfig/network HOSTNAME=ha-slave [root@ha-slave ~]# vim /etc/hosts 172.16.60.206 ha-master 172.16.60.207 ha-slave 3) 设置ip路由转发功能 (四台节点机器都设置) [root@ha-master ~]# echo 1 > /proc/sys/net/ipv4/ip_forward [root@ha-master ~]# vim /etc/sysctl.conf net.ipv4.ip_forward = 1 [root@ha-master ~]# sysctl -p
2) 安装配置 Heartbeat (两台HA节点机都操作)
1) 首先安装heartbeat (HA主备两个节点都要同样操作)
分别下载epel-release-latest-6.noarch.rpm 和 ldirectord-3.9.5-3.1.x86_64.rpm
下载地址: https://pan.baidu.com/s/1IvCDEFLCBYddalV89YvonQ
提取密码: gz53
[root@ha-master ~]# ll epel-release-latest-6.noarch.rpm
-rw-rw-r-- 1 root root 14540 Nov 5 2012 epel-release-latest-6.noarch.rpm
[root@ha-master ~]# ll ldirectord-3.9.5-3.1.x86_64.rpm
-rw-rw-r-- 1 root root 90140 Dec 24 15:54 ldirectord-3.9.5-3.1.x86_64.rpm
[root@ha-master ~]# yum install -y epel-release
[root@ha-master ~]# rpm -ivh epel-release-latest-6.noarch.rpm --force
[root@ha-master ~]# yum install -y heartbeat* libnet
[root@ha-master ~]# yum install -y ldirectord-3.9.5-3.1.x86_64.rpm #因为依赖比较多, 所以直接采用yum方式安装
2) 配置heartbeat (HA主备两个节点都要操作)
安装完heartbeat后系统会生成一个/etc/ha.d/目录,此目录用于存放heartbeat的有关配置文件。
Heartbeat自带配置文件的注释信息较多,在此手工编写有关配置文件,heartbeat常用配置文件有四个,分别是:
ha.cf:heartbeat主配置文件
ldirectord.cf:资源管理文件
haresources:本地资源文件
authkeys:认证文件
[root@ha-master ~]# cd /usr/share/doc/heartbeat-3.0.4/
[root@ha-master heartbeat-3.0.4]# cp authkeys ha.cf haresources /etc/ha.d/
[root@ha-master heartbeat-3.0.4]# cd /usr/share/doc/ldirectord-3.9.5
[root@ha-master ldirectord-3.9.5]# cp ldirectord.cf /etc/ha.d/
[root@ha-master ldirectord-3.9.5]# cd /etc/ha.d/
[root@ha-master ha.d]# ll
total 56
-rw-r--r-- 1 root root 645 Dec 24 21:37 authkeys
-rw-r--r-- 1 root root 10502 Dec 24 21:37 ha.cf
-rwxr-xr-x 1 root root 745 Dec 3 2013 harc
-rw-r--r-- 1 root root 5905 Dec 24 21:37 haresources
-rw-r--r-- 1 root root 8301 Dec 24 21:38 ldirectord.cf
drwxr-xr-x 2 root root 4096 Dec 24 21:28 rc.d
-rw-r--r-- 1 root root 692 Dec 3 2013 README.config
drwxr-xr-x 2 root root 4096 Dec 24 21:28 resource.d
-rw-r--r-- 1 root root 2082 Mar 24 2017 shellfuncs
3) 配置heartbeat的主配置文件ha.cf (HA主备节点配置一样)
[root@ha-master ha.d]# pwd
/etc/ha.d
[root@ha-master ha.d]# cp ha.cf ha.cf.bak
[root@ha-master ha.d]# > ha.cf
[root@ha-master ha.d]# vim ha.cf
debugfile /var/log/ha-debug
logfile /var/log/ha-log #日志存放位置
#crm yes #是否开启集群资源管理功能
logfacility local0 #记录日志等级
keepalive 2 #心跳的时间间隔,默认时间单位为秒
deadtime 5 #超出该时间间隔未收到对方节点的心跳,则认为对方已经死亡。
warntime 3 #超出该时间间隔未收到对方节点的心跳,则发出警告并记录到日志中,但此时不会切换
initdead 10 #在某些系统上,系统启动或重启之后需要经过一段时间网络才能正常工作,该选项用于解决这种情况产生的时间间隔。取值至少为deadtime的两倍。
udpport 694 #设置广播通信使用的端口,694为默认使用的端口号。
bcast eth0 # Linux指定心跳使用以太网广播方式,并在eth0上进行广播。"#"后的要完全删除,要不然要出错。
ucast eth0 172.16.60.207 #采用网卡eth0的UDP多播来组织心跳,后面跟的IP地址应该为双机中对方的IP地址!!!!!
auto_failback on #在该选项设为on的情况下,一旦主节点恢复运行,则自动获取资源并取代备用节点。off主节点恢复后变为备用节点,备用为主节点!!!!!
#stonith_host * baytech 10.0.0.3 mylogin mysecretpassword
#stonith_host ken3 rps10 /dev/ttyS1 kathy 0
#stonith_host kathy rps10 /dev/ttyS1 ken3 0
#watchdog /dev/watchdog
node ha-master #主机节点名,可通过"uname -n"查看,默认为主节点!!!!!
node ha-slave #备用机节点名,默认为次节点,要注意顺序!!!!
#ping 172.16.60.207 # 选择ping节点,选择固定路由作为节点。ping节点仅用来测试网络连接。一般选择这行ping测试就行, 下面一行注释掉.
ping_group group1 172.16.60.204 172.16.60.205 #这个地址并不是双机中的两个节点地址,而是仅仅用来测试网络的连通性. 当这两个IP 都不能ping通时,对方即开始接管资源。
respawn root /usr/lib64/heartbeat/ipfail #选配项。其中rootr表示启动ipfail进程的身份。要确保/usr/lib64/heartbeat/ipfail这个路径正确(可以用find命令搜索出来), 否则heartbeat启动失败
apiauth ipfail gid=root uid=root
============================温馨提示================================
HA备节点的ha.cf文件只需要将上面配置中的ucast一行内容改为"ucast eth0 172.16.60.206" 即可, 其他配置内容和上面HA主节点的ha.cf完全一样!
4) 配置heartbeat的认证文件authkeys (HA主备节点配置必须一致)
[root@ha-master ~]# cd /etc/ha.d/
[root@ha-master ha.d]# cp authkeys authkeys.bak
[root@ha-master ha.d]# >authkeys
auth 3 #auth后面指定的数字,下一行必须作为关键字再次出现! 一共有"1", "2","3" 三行, 这里选择"3"关键字, 选择"1"和"2"关键字也行, HA主备节点必须一致!
#1 crc
#2 sha1 HI!
3 md5 Hello!
必须将该文件授权为600
[root@ha-master ha.d]# chmod 600 authkeys
[root@ha-master ha.d]# ll authkeys
-rw------- 1 root root 20 Dec 25 00:16 authkeys
5) 修改heartbeat的资源文件haresources (HA主备节点配置必须完全一致)
[root@ha-slave ha.d]# cp haresources haresources.bak
[root@ha-slave ha.d]# >haresources
[root@ha-slave ha.d]# vim haresources # 在文件结尾添加下面一行内容. 由于该文件默认全是注释,可以先清空该文件, 然后添加下面这一行内容
ha-master IPaddr::172.16.60.111 ipvsadm ldirectord
配置说明:
上面设置ha-maser为主节点, 集群VIP为172.16.60.111, ipvsadm ldirectord为所指定需要监视的应用服务.
这样启动heartbeat服务的时候, 会自动启动ipvsadm和ldirectord服务.
ipvsadm服务的配置文件为/etc/sysconfig/ipvsadm, 后面会配置这个.
ldirectord 服务的配置文件为/etc/ha.d/ldirectord.cf, 后面会配置这个
6) 配置heartbeat的监控文件ldirectord.cf (HA主备节点配置必须完全一致)
ldirectord,用于监控在lvs集群的真实服务。ldirectord是和heartbeat相结合的一个服务,可以作为heartbeat的一个启动服务。
Ldirectord 的作用是监测 Real Server,当 Real Server失效时,把它从 Load Balancer列表中删除,恢复时重新添加。
将ldrectord的配置文件复制到/etc/ha.d下,因为默认没有放到这个路径下, 并且在ldirectord.cf文件中要配置"quiescent=no" 。
[root@ha-master ha.d]# cp ldirectord.cf ldirectord.cf.bak
[root@ha-master ha.d]# vim ldirectord.cf
checktimeout=3 #判定realserver出错时间
checkinterval=1 #指定ldirectord在两次检查之间的间隔时间,即主从切换的时间间隔
autoreload=yes #是否自动重载配置文件
logfile="/var/log/ldirectord.log" #指定ldirectord的日志文件路径
#logfile="local0"
#emailalert="root@30920.cn"
#emailalertfreq=3600
#emailalertstatus=all
quiescent=no #如果一个realserver节点在checktimeout设置的时间周期内没响应,将会被踢除,中断现有客户端的连接。 设置为yes, 则出问题的realserver节点不会被踢出, 只是新的连接不能到达。
virtual=172.16.60.111:80 #指定虚拟IP,注意在virtual这行后面的行必须缩进一个tab字符进行标记!! 否则极有可能因为格式配置不正确而导致ldirectord启动失败
real=172.16.60.204:80 gate #gate为lvs的DR模式,ipip表示TUNL模式,masq表示NAT模式
real=172.16.60.205:80 gate #当所有RS机器不能访问的时候WEB重写向地址; 即表示realserver全部失败,vip指向本机80端口
fallback=127.0.0.1:80 gate #指定服务类型,这里对HTTP进行负载均衡
service=http #指定服务类型,这里对HTTP进行负载均衡
scheduler=wlc #指定调度算法,这里的算法一定要和lvs脚本(/etc/sysconfig/ipvsadm)的算法一样
persistent=600 #持久链接:表示600s之内同一个客户端ip将访问同一台realserver. 除非这个realserver出现故障,才会将请求转发到另一个realserver
#netmask=255.255.255.255
protocol=tcp # 指定协议
checktype=negotiate #指定检查类型为协商 (或者执行检查类型为negotiate, 表示通过交互来判断服务是否正常)
checkport=80 # 监控的端口
request="lvs_testpage.html" #请求监控地址, 这个文件一定要放到后端realserver监控端口的根目录下, 即放到两台realserver的nginx根目录下
receive="Test HA Page" #指定请求和应答字符串,也就是上面lvs_testpage.html的内容
#virtualhost=www.x.y.z #虚拟服务器的名称可任意指定
============================温馨提示======================================
配置如上,通过virtual来定义vip,接下来是定义real service的节点,fallback是当所有real挂掉后,访问请求到本机的80端口上去,一般这个页面显示服务器正在维护等界面。
service表示;调度的服务,scheduler是调度算法,protocol是定义协议,checktype是检查类型为协商,checkport就是检查的端口,也就是健康检查。
上面在/etc/ha.d/ldirectord.cf文件里定义了一个80端口的代理转发, 如果还有其他端口, 比如3306,
则只需要在下面再添加一个"virtual=172.16.60.111:3306 ...."类似上面的配置即可! 配置案例在备份的ldirectord.cf.bak文件里有.
ldirectord.cf文件的配置, 最好按照这个文件里的配置范例去修改, 不要全部清空后自行添加, 否则容易因为配置格式问题导致ldirectord服务启动失败!
使用status查看ldirectord服务, 只要不出现报错信息, 就说明ldirectord.cf文件配置没有问题了!
[root@ha-master ha.d]# /etc/init.d/ldirectord status
3) 安装配置 LVS (两台HA节点机操作一致)
1) 安装lvs依赖
[root@ha-master ~]# yum install -y libnl* popt*
查看是否加载lvs模块
[root@ha-master ~]# modprobe -l |grep ipvs
kernel/net/netfilter/ipvs/ip_vs.ko
kernel/net/netfilter/ipvs/ip_vs_rr.ko
kernel/net/netfilter/ipvs/ip_vs_wrr.ko
kernel/net/netfilter/ipvs/ip_vs_lc.ko
kernel/net/netfilter/ipvs/ip_vs_wlc.ko
kernel/net/netfilter/ipvs/ip_vs_lblc.ko
kernel/net/netfilter/ipvs/ip_vs_lblcr.ko
kernel/net/netfilter/ipvs/ip_vs_dh.ko
kernel/net/netfilter/ipvs/ip_vs_sh.ko
kernel/net/netfilter/ipvs/ip_vs_sed.ko
kernel/net/netfilter/ipvs/ip_vs_nq.ko
kernel/net/netfilter/ipvs/ip_vs_ftp.ko
kernel/net/netfilter/ipvs/ip_vs_pe_sip.ko
2) 下载并安装LVS
[root@ha-master ~]# cd /usr/local/src/
[root@ha-master src]# unlink /usr/src/linux
[root@ha-master src]# ln -s /usr/src/kernels/2.6.32-431.5.1.el6.x86_64/ /usr/src/linux
[root@ha-master src]# wget http://www.linuxvirtualserver.org/software/kernel-2.6/ipvsadm-1.26.tar.gz
[root@ha-master src]# tar -zvxf ipvsadm-1.26.tar.gz
[root@ha-master src]# cd ipvsadm-1.26
[root@ha-master ipvsadm-1.26]# make && make install
LVS安装完成,查看当前LVS集群
[root@ha-master ipvsadm-1.26]# ipvsadm -L -n
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
3) 添加lvs的管理脚本(ipvsadm)
ipvsadm服务的配置文件是/etc/sysconfig/ipvsadm
[root@ha-master ha.d]# vim /etc/sysconfig/ipvsadm
#!/bin/bash
# description: start LVS of DirectorServer
#Written by :NetSeek http://www.linuxtone.org
GW=172.16.60.1 #这个是VIP所在网段的网段地址
# website director vip.
WEB_VIP=172.16.60.111
WEB_RIP1=172.16.60.204
WEB_RIP2=172.16.60.205
. /etc/rc.d/init.d/functions
logger $0 called with $1
case "$1" in
start)
# Clear all iptables rules.
/sbin/iptables -F
# Reset iptables counters.
/sbin/iptables -Z
# Clear all ipvsadm rules/services.
/sbin/ipvsadm -C
#set lvs vip for dr
/sbin/ipvsadm --set 30 5 60
/sbin/ifconfig eth0:0 $WEB_VIP broadcast $WEB_VIP netmask 255.255.255.255 up
/sbin/route add -host $WEB_VIP dev eth0:0
/sbin/ipvsadm -A -t $WEB_VIP:80 -s wlc -p 600
/sbin/ipvsadm -a -t $WEB_VIP:80 -r $WEB_RIP1:80 -g
/sbin/ipvsadm -a -t $WEB_VIP:80 -r $WEB_RIP2:80 -g
touch /var/lock/subsys/ipvsadm >/dev/null 2>&1
# set Arp
/sbin/arping -I eth0 -c 5 -s $WEB_VIP $GW >/dev/null 2>&1
;;
stop)
/sbin/ipvsadm -C
/sbin/ipvsadm -Z
ifconfig eth0:0 down
route del $WEB_VIP >/dev/null 2>&1
rm -rf /var/lock/subsys/ipvsadm >/dev/null 2>&1
/sbin/arping -I eth0 -c 5 -s $WEB_VIP $GW
echo "ipvsadm stoped"
;;
status)
if [ ! -e /var/lock/subsys/ipvsadm ];then
echo "ipvsadm is stoped"
exit 1
else
ipvsadm -ln
echo "..........ipvsadm is OK."
fi
;;
*)
echo "Usage: $0 {start|stop|status}"
exit 1
esac
exit 0
===============温馨提示=================
上面配置中的"-p 600"的意思是会话保持时间为600秒,这个应该和ldirectord.cf文件配置一致 (还有lvs策略也要一致, 如这里的lwc)
授权脚本执行权限
[root@ha-master ha.d]# chmod 755 /etc/sysconfig/ipvsadm
4) realserver 节点配置
1) 在realserver节点上编写LVS启动脚本 (两个realserver节点操作完全一致)
[root@rs-204 ~]# vim /etc/init.d/realserver
#!/bin/sh
VIP=172.16.60.111
. /etc/rc.d/init.d/functions
case "$1" in
# 禁用本地的ARP请求、绑定本地回环地址
start)
/sbin/ifconfig lo down
/sbin/ifconfig lo up
echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce
/sbin/sysctl -p >/dev/null 2>&1
/sbin/ifconfig lo:0 $VIP netmask 255.255.255.255 up
/sbin/route add -host $VIP dev lo:0
echo "LVS-DR real server starts successfully.\n"
;;
stop)
/sbin/ifconfig lo:0 down
/sbin/route del $VIP >/dev/null 2>&1
echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce
echo "LVS-DR real server stopped.\n"
;;
status)
isLoOn=`/sbin/ifconfig lo:0 | grep "$VIP"`
isRoOn=`/bin/netstat -rn | grep "$VIP"`
if [ "$isLoON" == "" -a "$isRoOn" == "" ]; then
echo "LVS-DR real server has run yet."
else
echo "LVS-DR real server is running."
fi
exit 3
;;
*)
echo "Usage: $0 {start|stop|status}"
exit 1
esac
exit 0
启动两台realserver节点的realserver脚本
[root@rs-204 ~]# chmod 755 /etc/init.d/realserver
[root@rs-204 ~]# ll /etc/init.d/realserver
-rwxr-xr-x 1 root root 1278 Dec 24 13:40 /etc/init.d/realserver
[root@rs-204 ~]# /etc/init.d/realserver start
LVS-DR real server starts successfully.\n
设置开机启动
[root@rs-204 ~]# echo "/etc/init.d/realserver" >> /etc/rc.local
查看, 发现两台realserver节点上的lo:0上已经配置了vip地址
[root@rs-204 ~]# ifconfig
...........
lo:0 Link encap:Local Loopback
inet addr:172.16.60.111 Mask:255.255.255.255
UP LOOPBACK RUNNING MTU:65536 Metric:1
2) 接着部署两台realserver的web测试环境 (两个realserver节点安装操作一致)
采用yum方式安装nginx (先安装nginx的yum源)
[root@rs-204 ~]# rpm -ivh http://nginx.org/packages/centos/6/noarch/RPMS/nginx-release-centos-6-0.el6.ngx.noarch.rpm
[root@rs-204 ~]# yum install nginx
realserver01的nginx配置
[root@rs-204 ~]# cd /etc/nginx/conf.d/
[root@rs-204 conf.d]# cat default.conf
[root@rs-204 conf.d]# >/usr/share/nginx/html/index.html
[root@rs-204 conf.d]# vim /usr/share/nginx/html/index.html
this is test page of realserver01:172.16.60.204
[root@rs-204 conf.d]# vim /usr/share/nginx/html/lvs_testpage.html
Test HA Page
[root@rs-204 conf.d]# /etc/init.d/nginx start
Starting nginx: [ OK ]
[root@rs-204 conf.d]# lsof -i:80
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nginx 31944 root 6u IPv4 91208 0t0 TCP *:http (LISTEN)
nginx 31945 nginx 6u IPv4 91208 0t0 TCP *:http (LISTEN)
realserver02的nginx配置
[root@rs-205 src]# cd /etc/nginx/conf.d/
[root@rs-205 conf.d]# cat default.conf
[root@rs-205 conf.d]# >/usr/share/nginx/html/index.html
[root@rs-205 conf.d]# vim /usr/share/nginx/html/index.html
this is test page of realserver02:172.16.60.205
[root@rs-205 conf.d]# vim /usr/share/nginx/html/lvs_testpage.html
Test HA Page
[root@rs-205 conf.d]# /etc/init.d/nginx start
Starting nginx: [ OK ]
[root@rs-205 conf.d]# lsof -i:80
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nginx 20839 root 6u IPv4 289527645 0t0 TCP *:http (LISTEN)
nginx 20840 nginx 6u IPv4 289527645 0t0 TCP *:http (LISTEN)
最后分别访问realserver01和realserver02节点的nginx,:
访问http://172.16.60.204/, 访问结果为"this is test page of realserver01:172.16.60.204"
访问http://172.16.60.204/lvs_testpage.html, 访问结果为"Test HA Page"
访问http://172.16.60.205/, 访问结果为"this is test page of realserver02:172.16.60.205"
访问http://172.16.60.205/lvs_testpage.html, 访问结果为"Test HA Page"
5) 配置两台HA节点上转发到自身80端口的页面内容 (两台HA节点操作一致)
由于在ldirectord.cf文件中配置了"fallback=127.0.0.1:80 gate", 即当后端realserver都发生故障时, 客户端的访问请求将转发到LVS的HA节点自身的80端口上 [root@ha-master ~]# rpm -ivh http://nginx.org/packages/centos/6/noarch/RPMS/nginx-release-centos-6-0.el6.ngx.noarch.rpm [root@ha-master ~]# yum install nginx realserver01的nginx配置 [root@ha-master ~]# cd /etc/nginx/conf.d/ [root@ha-master conf.d]# cat default.conf [root@ha-master conf.d]# >/usr/share/nginx/html/index.html [root@ha-master conf.d]# vim /usr/share/nginx/html/index.html Sorry, the access is in maintenance for the time being. Please wait a moment. [root@ha-master conf.d]# /etc/init.d/nginx start Starting nginx: [ OK ] [root@ha-master conf.d]# lsof -i:80 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME nginx 31944 root 6u IPv4 91208 0t0 TCP *:http (LISTEN) nginx 31945 nginx 6u IPv4 91208 0t0 TCP *:http (LISTEN) 访问http://172.16.60.206/ 或者 http://172.16.60.207 访问结果为"Sorry, the access is in maintenance for the time being. Please wait a moment."
6) 启动heartbeat服务 (两个HA节点都要操作)
启动heartbeat服务的时候, 就会自带启动ipvsadm 和 ldirectord, 因为在/etc/ha.d/haresources文件里配置了!
需要知道的是: 只有当前提供lvs转发服务(即拥有VIP资源)的一方 才能在启动heartbeat的时候, 自带启动ipvsadm 和 ldirectord!
1) 先启动HA主节点的heartbeat
[root@ha-master ~]# /etc/init.d/heartbeat start
Starting High-Availability services: INFO: Resource is stopped
Done.
[root@ha-master ~]# ps -ef|grep heartbeat
root 20886 1 0 15:41 ? 00:00:00 heartbeat: master control process
root 20891 20886 0 15:41 ? 00:00:00 heartbeat: FIFO reader
root 20892 20886 0 15:41 ? 00:00:00 heartbeat: write: bcast eth0
root 20893 20886 0 15:41 ? 00:00:00 heartbeat: read: bcast eth0
root 20894 20886 0 15:41 ? 00:00:00 heartbeat: write: ucast eth0
root 20895 20886 0 15:41 ? 00:00:00 heartbeat: read: ucast eth0
root 20896 20886 0 15:41 ? 00:00:00 heartbeat: write: ping_group group1
root 20897 20886 0 15:41 ? 00:00:00 heartbeat: read: ping_group group1
root 20917 20886 0 15:41 ? 00:00:00 /usr/lib64/heartbeat/ipfail
root 20938 17616 0 15:41 pts/0 00:00:00 grep heartbeat
heartbeat服务端口默认是694.
[root@ha-master ~]# lsof -i:694
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
heartbeat 20892 root 7u IPv4 42238 0t0 UDP *:ha-cluster
heartbeat 20893 root 7u IPv4 42238 0t0 UDP *:ha-cluster
heartbeat 20894 root 7u IPv4 42244 0t0 UDP *:ha-cluster
heartbeat 20895 root 7u IPv4 42244 0t0 UDP *:ha-cluster
发现ldirectord服务被自带启动了, 说明master节点是当前提供lvs转发服务的一方
[root@ha-master ~]# ps -ef|grep ldirectord
root 21336 1 0 15:41 ? 00:00:00 /usr/bin/perl -w /usr/sbin/ldirectord start
root 21365 17616 0 15:42 pts/0 00:00:00 grep ldirectord
[root@ha-master ~]# /etc/init.d/ldirectord status
ldirectord for /etc/ha.d/ldirectord.cf is running with pid: 21336
查看master节点,发现master节点当前占有vip资源 (首次启动heartbeat服务后, 需要稍微等待一段时间, vip资源才会出来. 后续再重启或切换时, vip资源就会迅速出现了)
[root@ha-master ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:50:56:ac:50:9b brd ff:ff:ff:ff:ff:ff
inet 172.16.60.206/24 brd 172.16.60.255 scope global eth0
inet 172.16.60.111/24 brd 172.16.60.255 scope global secondary eth0
inet6 fe80::250:56ff:feac:509b/64 scope link
valid_lft forever preferred_lft forever
master节点当前提供了lvs转发功能, 可以查看到转发效果
[root@ha-master ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.60.111:80 wlc persistent 600
-> 172.16.60.204:80 Route 1 0 0
-> 172.16.60.205:80 Route 1 0 0
查看master节点的heartbeat日志
[root@ha-master ~]# tail -f /var/log/ha-log
ip-request-resp(default)[21041]: 2018/12/25_15:41:48 received ip-request-resp IPaddr::172.16.60.111 OK yes
ResourceManager(default)[21064]: 2018/12/25_15:41:48 info: Acquiring resource group: ha-master IPaddr::172.16.60.111 ipvsadm ldirectord
/usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_172.16.60.111)[21092]: 2018/12/25_15:41:48 INFO: Resource is stopped
ResourceManager(default)[21064]: 2018/12/25_15:41:48 info: Running /etc/ha.d/resource.d/IPaddr 172.16.60.111 start
IPaddr(IPaddr_172.16.60.111)[21188]: 2018/12/25_15:41:48 INFO: Adding inet address 172.16.60.111/24 with broadcast address 172.16.60.255 to device eth0
IPaddr(IPaddr_172.16.60.111)[21188]: 2018/12/25_15:41:48 INFO: Bringing device eth0 up
IPaddr(IPaddr_172.16.60.111)[21188]: 2018/12/25_15:41:48 INFO: /usr/libexec/heartbeat/send_arp -i 200 -r 5 -p /var/run/resource-agents/send_arp-172.16.60.111 eth0 172.16.60.111 auto not_used not_used
/usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_172.16.60.111)[21174]: 2018/12/25_15:41:48 INFO: Success
ResourceManager(default)[21064]: 2018/12/25_15:41:48 info: Running /etc/init.d/ipvsadm start
ResourceManager(default)[21064]: 2018/12/25_15:41:48 info: Running /etc/init.d/ldirectord start
2) 接着启动HA备份节点的heartbeat
[root@ha-slave ha.d]# /etc/init.d/heartbeat start
Starting High-Availability services: INFO: Resource is stopped
Done.
[root@ha-slave ha.d]# ps -ef|grep heartbeat
root 21703 1 0 15:41 ? 00:00:00 heartbeat: master control process
root 21708 21703 0 15:41 ? 00:00:00 heartbeat: FIFO reader
root 21709 21703 0 15:41 ? 00:00:00 heartbeat: write: bcast eth0
root 21710 21703 0 15:41 ? 00:00:00 heartbeat: read: bcast eth0
root 21711 21703 0 15:41 ? 00:00:00 heartbeat: write: ucast eth0
root 21712 21703 0 15:41 ? 00:00:00 heartbeat: read: ucast eth0
root 21713 21703 0 15:41 ? 00:00:00 heartbeat: write: ping_group group1
root 21714 21703 0 15:41 ? 00:00:00 heartbeat: read: ping_group group1
root 21734 21703 0 15:41 ? 00:00:00 /usr/lib64/heartbeat/ipfail
root 21769 19163 0 15:42 pts/0 00:00:00 grep heartbeat
[root@ha-slave ha.d]# lsof -i:694
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
heartbeat 21709 root 7u IPv4 105186 0t0 UDP *:ha-cluster
heartbeat 21710 root 7u IPv4 105186 0t0 UDP *:ha-cluster
heartbeat 21711 root 7u IPv4 105192 0t0 UDP *:ha-cluster
heartbeat 21712 root 7u IPv4 105192 0t0 UDP *:ha-cluster
发现ldirectord服务没有被heartbeat自带启动 (因为当前备份节点没有提供lvs转发功能, 即没有接管vip资源)
[root@ha-slave ha.d]# /etc/init.d/ldirectord status
ldirectord is stopped for /etc/ha.d/ldirectord.cf
[root@ha-slave ha.d]# ps -ef|grep ldirectord
root 21822 19163 0 15:55 pts/0 00:00:00 grep ldirectord
发现ipvsadm服务也没有被heartbeat自带启动 (因为当前备份节点没有提供lvs转发功能, 即没有接管vip资源)
[root@ha-slave ha.d]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:50:56:ac:05:b5 brd ff:ff:ff:ff:ff:ff
inet 172.16.60.207/24 brd 172.16.60.255 scope global eth0
inet6 fe80::250:56ff:feac:5b5/64 scope link
valid_lft forever preferred_lft forever
[root@ha-slave ha.d]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
查看HA备份节点的heartbeat日志
[root@ha-slave ha.d]# tail -f /var/log/ha-log
Dec 25 15:41:37 ha-slave heartbeat: [21734]: info: Starting "/usr/lib64/heartbeat/ipfail" as uid 0 gid 0 (pid 21734)
Dec 25 15:41:38 ha-slave heartbeat: [21703]: info: Status update for node ha-master: status active
harc(default)[21737]: 2018/12/25_15:41:38 info: Running /etc/ha.d//rc.d/status status
Dec 25 15:41:42 ha-slave ipfail: [21734]: info: Status update: Node ha-master now has status active
Dec 25 15:41:44 ha-slave ipfail: [21734]: info: Asking other side for ping node count.
Dec 25 15:41:47 ha-slave ipfail: [21734]: info: No giveup timer to abort.
Dec 25 15:41:48 ha-slave heartbeat: [21703]: info: remote resource transition completed.
Dec 25 15:41:48 ha-slave heartbeat: [21703]: info: remote resource transition completed.
Dec 25 15:41:48 ha-slave heartbeat: [21703]: info: Initial resource acquisition complete (T_RESOURCES(us))
Dec 25 15:41:48 ha-slave heartbeat: [21754]: info: No local resources [/usr/share/heartbeat/Resourc
访问使用vip地址访问, 即:
访问http://172.16.60.111/, 结果为"this is test page of realserver01:172.16.60.204" 或者 "this is test page of realserver02:172.16.60.205"
访问http://172.16.60.111/lvs_testpage.html, 结果为"Test HA Page"
温馨提示:
下面是两个常用的ipvsadm 关于查看lvs状态的命令
======================================
查看lvs的连接状态命令
[root@ha-master ~]# ipvsadm -l --stats
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Conns InPkts OutPkts InBytes OutBytes
-> RemoteAddress:Port
TCP 172.16.60.111:http 0 0 0 0 0
-> 172.16.60.204:http 0 0 0 0 0
-> 172.16.60.205:http 0 0 0 0 0
说明:
Conns (connections scheduled) 已经转发过的连接数
InPkts (incoming packets) 入包个数
OutPkts (outgoing packets) 出包个数
InBytes (incoming bytes) 入流量(字节)
OutBytes (outgoing bytes) 出流量(字节)
======================================
查看lvs的速率
[root@ha-master ~]# ipvsadm -l --rate
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port CPS InPPS OutPPS InBPS OutBPS
-> RemoteAddress:Port
TCP 172.16.60.111:http 0 0 0 0 0
-> 172.16.60.204:http 0 0 0 0 0
-> 172.16.60.205:http 0 0 0 0 0
说明:
CPS (current connection rate) 每秒连接数
InPPS (current in packet rate) 每秒的入包个数
OutPPS (current out packet rate) 每秒的出包个数
InBPS (current in byte rate) 每秒入流量(字节)
OutBPS (current out byte rate) 每秒入流量(字节)
======================================
上面的两台HA节点均只有一个网卡设备eth0, 如果有两块网卡, 比如还有一个eth1, 则可以将这个eth1作为heartbeat交叉线直连的设备,
即HA主备两台机器之间使用一根串口直连线缆eth1进行连接.
比如:
HA主节点 172.16.60.206(eth0), 10.0.11.21(eth1, heartbeat交叉线直连)
HA备节点 172.16.60.207(eth0), 10.0.11.22(eth1, heartbeat交叉线直连)
这样比起只有一个eth0, 只需要在ha.cf文件中多加下面一行 (其他的操作配置都不用变!)
ping_group group1 10.0.11.21 10.0.11.22 //多加这一行
ping_group group1 172.16.60.204 172.16.60.205
7) 故障转移切换测试
1) 先关闭HA主节点的heartbeat
[root@ha-master ~]# /etc/init.d/heartbeat stop
Stopping High-Availability services: Done.
[root@ha-master ~]# ps -ef|grep heartbeat
root 21625 17616 0 16:03 pts/0 00:00:00 grep heartbeat
发现关闭heartbeat服务后, 主节点的ipvsadm 和 ldirectord都会被自带关闭, VIP资源也被转移走了, 即当前master节点不提供lvs转发服务
[root@ha-master ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:50:56:ac:50:9b brd ff:ff:ff:ff:ff:ff
inet 172.16.60.206/24 brd 172.16.60.255 scope global eth0
inet6 fe80::250:56ff:feac:509b/64 scope link
valid_lft forever preferred_lft forever
[root@ha-master ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
[root@ha-master ~]# ps -ef|grep ldirectord
root 21630 17616 0 16:03 pts/0 00:00:00 grep ldirectord
查看此时HA主节点的heartbeat日志
[root@ha-master ~]# tail -1000 /var/log/ha-log
........
Dec 25 16:02:38 ha-master heartbeat: [20886]: info: Heartbeat shutdown in progress. (20886)
Dec 25 16:02:38 ha-master heartbeat: [21454]: info: Giving up all HA resources.
ResourceManager(default)[21467]: 2018/12/25_16:02:38 info: Releasing resource group: ha-master IPaddr::172.16.60.111 ipvsadm ldirectord
ResourceManager(default)[21467]: 2018/12/25_16:02:38 info: Running /etc/init.d/ldirectord stop
ResourceManager(default)[21467]: 2018/12/25_16:02:38 info: Running /etc/init.d/ipvsadm stop
ResourceManager(default)[21467]: 2018/12/25_16:02:38 info: Running /etc/ha.d/resource.d/IPaddr 172.16.60.111 stop
IPaddr(IPaddr_172.16.60.111)[21563]: 2018/12/25_16:02:38 INFO: IP status = ok, IP_CIP=
/usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_172.16.60.111)[21549]: 2018/12/25_16:02:38 INFO: Success
接着查看HA备份节点的情况, 发现VIP已将已经切换到备份节点这边了, 说明当前备份节点提供lvs转发服务, 则备份节点的ipvsadm 和 ldirectord也被自带启动了
[root@ha-slave ha.d]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:50:56:ac:05:b5 brd ff:ff:ff:ff:ff:ff
inet 172.16.60.207/24 brd 172.16.60.255 scope global eth0
inet 172.16.60.111/24 brd 172.16.60.255 scope global secondary eth0
inet6 fe80::250:56ff:feac:5b5/64 scope link
valid_lft forever preferred_lft forever
[root@ha-slave ha.d]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.60.111:80 wlc persistent 600
-> 172.16.60.204:80 Route 1 0 0
-> 172.16.60.205:80 Route 1 0 0
[root@ha-slave ha.d]# ps -ef|grep ldirectord
root 22203 1 0 16:02 ? 00:00:01 /usr/bin/perl -w /usr/sbin/ldirectord start
root 22261 19163 0 16:07 pts/0 00:00:00 grep ldirectord
查看此时HA备份节点的heartbeat日志
[root@ha-slave ha.d]# tail -1000 /var/log/ha-log
...........
harc(default)[21887]: 2018/12/25_16:02:39 info: Running /etc/ha.d//rc.d/status status
mach_down(default)[21904]: 2018/12/25_16:02:39 info: Taking over resource group IPaddr::172.16.60.111
ResourceManager(default)[21931]: 2018/12/25_16:02:39 info: Acquiring resource group: ha-master IPaddr::172.16.60.111 ipvsadm ldirectord
/usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_172.16.60.111)[21959]: 2018/12/25_16:02:39 INFO: Resource is stopped
ResourceManager(default)[21931]: 2018/12/25_16:02:39 info: Running /etc/ha.d/resource.d/IPaddr 172.16.60.111 start
IPaddr(IPaddr_172.16.60.111)[22055]: 2018/12/25_16:02:39 INFO: Adding inet address 172.16.60.111/24 with broadcast address 172.16.60.255 to device eth0
IPaddr(IPaddr_172.16.60.111)[22055]: 2018/12/25_16:02:39 INFO: Bringing device eth0 up
IPaddr(IPaddr_172.16.60.111)[22055]: 2018/12/25_16:02:39 INFO: /usr/libexec/heartbeat/send_arp -i 200 -r 5 -p /var/run/resource-agents/send_arp-172.16.60.111 eth0 172.16.60.111 auto not_used not_used
/usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_172.16.60.111)[22041]: 2018/12/25_16:02:39 INFO: Success
ResourceManager(default)[21931]: 2018/12/25_16:02:39 info: Running /etc/init.d/ipvsadm start
ResourceManager(default)[21931]: 2018/12/25_16:02:39 info: Running /etc/init.d/ldirectord start
mach_down(default)[21904]: 2018/12/25_16:02:39 info: /usr/share/heartbeat/mach_down: nice_failback: foreign resources acquired
mach_down(default)[21904]: 2018/12/25_16:02:39 info: mach_down takeover complete for node ha-master.
2) 然后在重新启动HA主节点的heartbeat服务
由于在ha.cf文件中配置了"auto_failback on "参数, 所以当主节点恢复后, 会将VIP资源自动抢占回来并替换备份节点重新接管lvs转发服务.
主节点的heartbeat恢复后, ipvsadm 和 ldirectord也会被重新启动
[root@ha-master ~]# /etc/init.d/heartbeat start
Starting High-Availability services: INFO: Resource is stopped
Done.
[root@ha-master ~]# ps -ef|grep heartbeat
root 21778 1 0 16:12 ? 00:00:00 heartbeat: master control process
root 21783 21778 0 16:12 ? 00:00:00 heartbeat: FIFO reader
root 21784 21778 0 16:12 ? 00:00:00 heartbeat: write: bcast eth0
root 21785 21778 0 16:12 ? 00:00:00 heartbeat: read: bcast eth0
root 21786 21778 0 16:12 ? 00:00:00 heartbeat: write: ucast eth0
root 21787 21778 0 16:12 ? 00:00:00 heartbeat: read: ucast eth0
root 21788 21778 0 16:12 ? 00:00:00 heartbeat: write: ping_group group1
root 21789 21778 0 16:12 ? 00:00:00 heartbeat: read: ping_group group1
root 21809 21778 0 16:12 ? 00:00:00 /usr/lib64/heartbeat/ipfail
root 21812 21778 0 16:12 ? 00:00:00 heartbeat: master control process
root 21825 21812 0 16:12 ? 00:00:00 /bin/sh /usr/share/heartbeat/ResourceManager takegroup IPaddr::172.16.60.111 ipvsadm ldirectord
root 21949 21935 0 16:12 ? 00:00:00 /bin/sh /usr/lib/ocf/resource.d//heartbeat/IPaddr start
root 21956 17616 0 16:12 pts/0 00:00:00 grep heartbeat
[root@ha-master ~]# lsof -i:694
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
heartbeat 21784 root 7u IPv4 46306 0t0 UDP *:ha-cluster
heartbeat 21785 root 7u IPv4 46306 0t0 UDP *:ha-cluster
heartbeat 21786 root 7u IPv4 46312 0t0 UDP *:ha-cluster
heartbeat 21787 root 7u IPv4 46312 0t0 UDP *:ha-cluster
[root@ha-master ~]# ps -ef|grep ldirectord
root 22099 1 1 16:12 ? 00:00:00 /usr/bin/perl -w /usr/sbin/ldirectord start
root 22130 17616 0 16:12 pts/0 00:00:00 grep ldirectord
[root@ha-master ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:50:56:ac:50:9b brd ff:ff:ff:ff:ff:ff
inet 172.16.60.206/24 brd 172.16.60.255 scope global eth0
inet 172.16.60.111/24 brd 172.16.60.255 scope global secondary eth0
inet6 fe80::250:56ff:feac:509b/64 scope link
valid_lft forever preferred_lft forever
[root@ha-master ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.60.111:80 wlc persistent 600
-> 172.16.60.204:80 Route 1 0 0
-> 172.16.60.205:80 Route 1 1 0
查看此时HA主节点的heartbeat日志
[root@ha-master ~]# tail -1000 /var/log/ha-log
........
ResourceManager(default)[21825]: 2018/12/25_16:12:12 info: Acquiring resource group: ha-master IPaddr::172.16.60.111 ipvsadm ldirectord
/usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_172.16.60.111)[21853]: 2018/12/25_16:12:13 INFO: Resource is stopped
ResourceManager(default)[21825]: 2018/12/25_16:12:13 info: Running /etc/ha.d/resource.d/IPaddr 172.16.60.111 start
IPaddr(IPaddr_172.16.60.111)[21949]: 2018/12/25_16:12:13 INFO: Adding inet address 172.16.60.111/24 with broadcast address 172.16.60.255 to device eth0
IPaddr(IPaddr_172.16.60.111)[21949]: 2018/12/25_16:12:13 INFO: Bringing device eth0 up
IPaddr(IPaddr_172.16.60.111)[21949]: 2018/12/25_16:12:13 INFO: /usr/libexec/heartbeat/send_arp -i 200 -r 5 -p /var/run/resource-agents/send_arp-172.16.60.111 eth0 172.16.60.111 auto not_used not_used
/usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_172.16.60.111)[21935]: 2018/12/25_16:12:13 INFO: Success
ResourceManager(default)[21825]: 2018/12/25_16:12:13 info: Running /etc/init.d/ipvsadm start
ResourceManager(default)[21825]: 2018/12/25_16:12:13 info: Running /etc/init.d/ldirectord start
再观察此时HA备份节点的情况, 发现VIP资源在主节点的heartbeat恢复后就被主节点抢占回去了, 即此时备份节点没有vip资源, 也就不提供lvs转发服务了,
则备份节点的ipvsadm 和 ldirectord服务也会被关闭
[root@ha-slave ha.d]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 00:50:56:ac:05:b5 brd ff:ff:ff:ff:ff:ff
inet 172.16.60.207/24 brd 172.16.60.255 scope global eth0
inet6 fe80::250:56ff:feac:5b5/64 scope link
valid_lft forever preferred_lft forever
[root@ha-slave ha.d]# ps -ef|grep ldirectord
root 22516 19163 0 16:14 pts/0 00:00:00 grep ldirectord
[root@ha-slave ha.d]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
查看此时HA备份节点的heartbeat日志
[root@ha-slave ha.d]# tail -1000 /var/log/ha-log
.......
ResourceManager(default)[22342]: 2018/12/25_16:12:12 info: Releasing resource group: ha-master IPaddr::172.16.60.111 ipvsadm ldirectord
ResourceManager(default)[22342]: 2018/12/25_16:12:12 info: Running /etc/init.d/ldirectord stop
ResourceManager(default)[22342]: 2018/12/25_16:12:12 info: Running /etc/init.d/ipvsadm stop
ResourceManager(default)[22342]: 2018/12/25_16:12:12 info: Running /etc/ha.d/resource.d/IPaddr 172.16.60.111 stop
IPaddr(IPaddr_172.16.60.111)[22438]: 2018/12/25_16:12:12 INFO: IP status = ok, IP_CIP=
/usr/lib/ocf/resource.d//heartbeat/IPaddr(IPaddr_172.16.60.111)[22424]: 2018/12/25_16:12:12 INFO: Success
Dec 25 16:12:12 ha-slave heartbeat: [22329]: info: foreign HA resource release completed (standby).
在上面HA主备节点故障切换的过程中, 客户端访问http://172.16.60.111/都是不受影响的, 即对客户端访问来说是无感知的故障切换, 实现了lvs代理层的高可用!
3) 先后关闭两台realserver节点中的nginx, 然后观察lvs的转发情况
[root@ha-master ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.60.111:80 wlc persistent 600
-> 172.16.60.204:80 Route 1 0 0
-> 172.16.60.205:80 Route 1 0 2
先关闭rs-204的nginx服务
[root@rs-204 ~]# /etc/init.d/nginx stop
Stopping nginx: [ OK ]
[root@rs-204 ~]# lsof -i:80
[root@rs-204 ~]#
rs-205的nginx保留
[root@rs-205 ~]# ps -ef|grep nginx
root 5211 1 0 15:45 ? 00:00:00 nginx: master process /usr/sbin/nginx -c /etc/nginx/nginx.conf
nginx 5212 5211 0 15:45 ? 00:00:00 nginx: worker process
root 5313 4852 0 16:19 pts/0 00:00:00 grep nginx
查看lvs转发情况
[root@ha-master ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.60.111:80 wlc persistent 600
-> 172.16.60.205:80 Route 1 0 2
这时候访问http://172.16.60.111, 结果是"this is test page of realserver02:172.16.60.205"
接着启动rs-204的nginx, 关闭rs-205的nginx
[root@rs-204 ~]# /etc/init.d/nginx start
Starting nginx: [ OK ]
[root@rs-204 ~]# lsof -i:80
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
nginx 4883 root 6u IPv4 143621 0t0 TCP *:http (LISTEN)
nginx 4884 nginx 6u IPv4 143621 0t0 TCP *:http (LISTEN)
关闭rs-205的nginx
[root@rs-205 ~]# /etc/init.d/nginx stop
Stopping nginx: [ OK ]
[root@rs-205 ~]# lsof -i:80
[root@rs-205 ~]#
查看lvs转发情况
[root@ha-master ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.60.111:80 wlc persistent 600
-> 172.16.60.204:80 Route 1 0 0
这时候访问http://172.16.60.111, 结果是"this is test page of realserver01:172.16.60.204"
然后把rs-204 和 rs-205两个节点的nginx都关闭
[root@rs-204 ~]# /etc/init.d/nginx stop
Stopping nginx: [ OK ]
[root@rs-205 ~]# /etc/init.d/nginx stop
Stopping nginx: [ OK ]
查看lvs转发情况
[root@ha-master ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.60.111:80 wlc persistent 600
-> 127.0.0.1:80 Local 1 0 0
这时候访问http://172.16.60.111, 结果是"Sorry, the access is in maintenance for the time being. Please wait a moment."
上面可知, 在realserver节点发生故障后, 会从lvs集群中踢出来, 待realserver节点恢复后会再次重新加入到lvs集群中
这是因为在ldirectord.cf文件中配置了"quiescent=no "参数 , 这样就实现了代理节点的高可用!
目录 返回
首页