kafka单机和集群(全分布)的安装部署过程
目录
一:安装准备
1.必须安装了zookeeper
zookeeper安装操作:zookeeper单机和集群(全分布)的安装过程_一个人的牛牛的博客-CSDN博客
2.下载kafka
可以通过这两个网站下载想要的版本
http://kafka.apache.org/downloadshttps://mirrors.tuna.tsinghua.edu.cn/apache/kafka/或者下载和我一样的版本(我用的是kafka_2.11-2.3.1.tgz)
百度网盘地址:
链接:https://pan.baidu.com/s/1uQTVMzg8E5QULQTAoppdcQ
提取码:58c5二:单机安装
1.上传安装包
把kafka_2.11-2.3.1.tgz上传到hadoop001的/tools目录下,
直接把kafka_2.11-2.3.1.tgz拖到MobaXterm_Portable的框框里就行。
操作参考:MobaXterm_Portable的简单使用_一个人的牛牛的博客-CSDN博客
2.解压
进入/tools目录操作,我的安装包放在/tools目录下,软件放在/training目录下,没有目录的使用mkdir /tools和mkdir /training创建,
tar -zvxf kafka_2.11-2.3.1.tgz -C /training/3.配置环境变量
vi ~/.bash_profile添加内容:
#kafka
export KAFKA_HOME=/training/kafka-2.3.1
export PATH=$PATH:$KAFKA_HOME/bin
环境变量生效
source ~/.bash_profile4.配置文件
创建logs目录(在kafka目录下)
mkdir logs配置server.properties(文件在kafka路径下的config目录中)
vi server.properties(hadoop001是我的主机名 )
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能 生产环境当中都是false
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志和数据存放的路径
log.dirs=/training/kafka-2.3.1/logs
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=24
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop001:21815.启动kafka(在kafka目录下)(需要先启动zookeeper)
bin/kafka-server-start.sh -daemon config/server.properties6.验证
jps查看进程

有kafka进程,安装成功!!!
三:集群安装(全分布)
我的虚拟机分别为:
hadoop001(192.168.17.131)(主节点),
hadoop002(192.168.17.132)(从节点),
hadoop003(192.168.17.133)(从节点)。
以下操作都在主节点hadoop001上执行
1.上传安装包
把kafka_2.11-2.3.1.tgz上传到hadoop001的/tools目录下,
直接把kafka_2.11-2.3.1.tgz拖到MobaXterm_Portable的框框里就行。
操作参考:MobaXterm_Portable的简单使用_一个人的牛牛的博客-CSDN博客
2.解压
进入/tools目录操作,我的安装包放在/tools目录下,软件放在/training目录下,没有目录的使用mkdir /tools和mkdir /training创建,
tar -zvxf kafka_2.11-2.3.1.tgz -C /training/3.配置环境变量
vi ~/.bash_profile添加内容:
#kafka
export KAFKA_HOME=/training/kafka-2.3.1
export PATH=$PATH:$KAFKA_HOME/bin
环境变量生效
source ~/.bash_profile4.配置文件
创建logs目录(在kafka目录下)
mkdir logs配置server.properties(文件在kafka路径下的config目录中)
vi server.properties(hadoop001,hadoop002,hadoop003是我的主机名 )
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能 生产环境当中都是false
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志和数据存放的路径
log.dirs=/training/kafka-2.3.1/logs
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=24
#配置连接Zookeeper集群地址
zookeeper.connect=hadoop001:2181,hadoop002:2181,hadoop003:21815.将配置好的kafka拷贝到其他节点
scp -r /training/kafka-2.3.1/ hadoop002:/training/scp -r /training/kafka-2.3.1/ hadoop003:/training/在training目录下用:
scp -r kafka-2.3.1/ hadoop002:/training/
scp -r kafka-2.3.1/ hadoop003:/training/6.配置其他节点(hadoop002和hadoop003)的环境变量
操作和上面一样!!!
7.修改broker.id
分别在hadoop002和hadoop004上修改配置文件training/kafka-2.3.1/config/server.properties中的broker.id,hadoop002修改为broker.id=1、hadoop003修改为broker.id=2
broker.id不得重复
8.启动zookeeper
在所有节点上都需要执行启动命令!!!
在/training/zookeeper-3.4.5目录下执行:
bin/zkServer.sh startjps看到QuorumPeerMain进程就已经启动成功了!!!

9. 启动kafka(在kafka目录下)(需要先启动zookeeper,每一台都要启动)
每一台都要启动kafka
bin/kafka-server-start.sh -daemon config/server.properties
bin/kafka-server-start.sh -daemon config/server.properties
bin/kafka-server-start.sh -daemon config/server.properties验证
jps查看进程
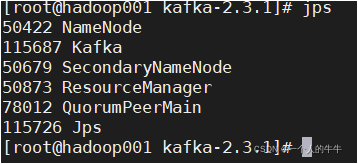

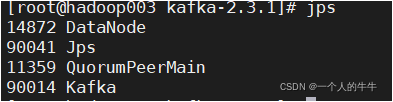
都有kafka进程,安装成功!!!
关闭kafka(在kafka目录下)
bin/kafka-server-stop.sh目录 返回
首页