ELK filebeat收集java堆日志
收集Java堆栈日志
一般来说日志的每一行就代表一个完整的请求nginx,但是有些日志是多行的java堆栈日志。多行日志代表了一个事务,如果让elk来处理会认为有四个文档
一般应用记录的日志,每行表示一个事务,但有些日志是多行表示一个事务。
例如,常见的Java堆栈日志:
Exception in thread "main" java.lang.NullPointerException
at com.example.myproject.Book.getTitle(Book.java:16)
at com.example.myproject.Author.getBookTitles(Author.java:25)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)上面文档表示四行,在Kibana里也视为四个单独的文档,但实际这是一个异常日志,如果分开阅读会脱离上下文关系,不利于分析。
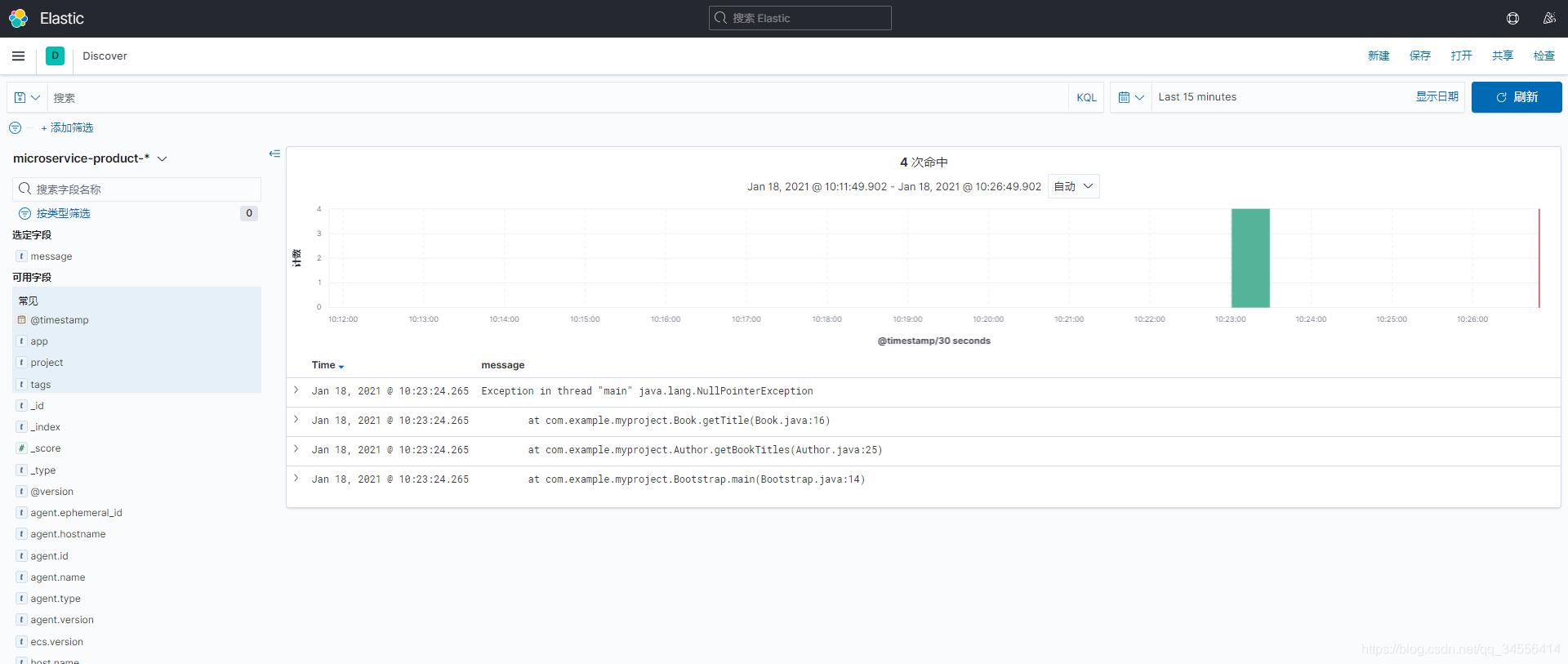
收集Java堆栈日志
因此,为了避免此问题,可以让filebeat启用多行处理,将这四行作为一个事件发送。
filebeat多行参数:(启用多行参数,下面是需要配置的)
• multiline.pattern: '^\s' 正则表达式,匹配行
• multiline.negate: false 否定正则匹配模式,正则取反效果。例如false时将匹配的行合并到上一行,true时将不匹配的行合并到上一行。默认false
• multiline.match: after 合并到上一行的末尾还是开头(before)
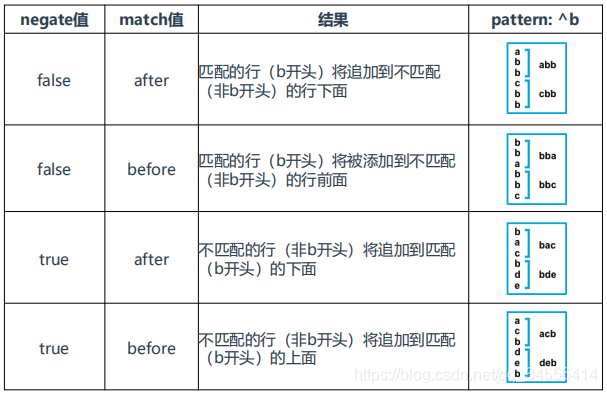
filebeat配置
[root@localhost ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/java.txt
tags: ["nginx"]
fields_under_root: true
fields:
project: microservice
app: product
multiline.pattern: '^\s'
multiline.negate: false
multiline.match: after
output.logstash:
hosts: ["192.168.179.102:5044"]logstash配置
[root@localhost ~]# cat /usr/local/logstash/conf.d/test.conf
input {
beats {
host => "0.0.0.0"
port => 5044
}
}
filter {
json {
source => "message"
}
if [app] == "product" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-product-%{+YYYY.MM}"
}
}
} else if [app] == "gateway" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-gateway-%{+YYYY.MM.dd}"
}
}
} else {
mutate {
add_field => {
"[@metadata][target_index]" => "unknown-%{+YYYY}"
}
}
}
}
output {
elasticsearch {
hosts => "192.168.179.102:9200"
index => "%{[@metadata][target_index]}"
}
}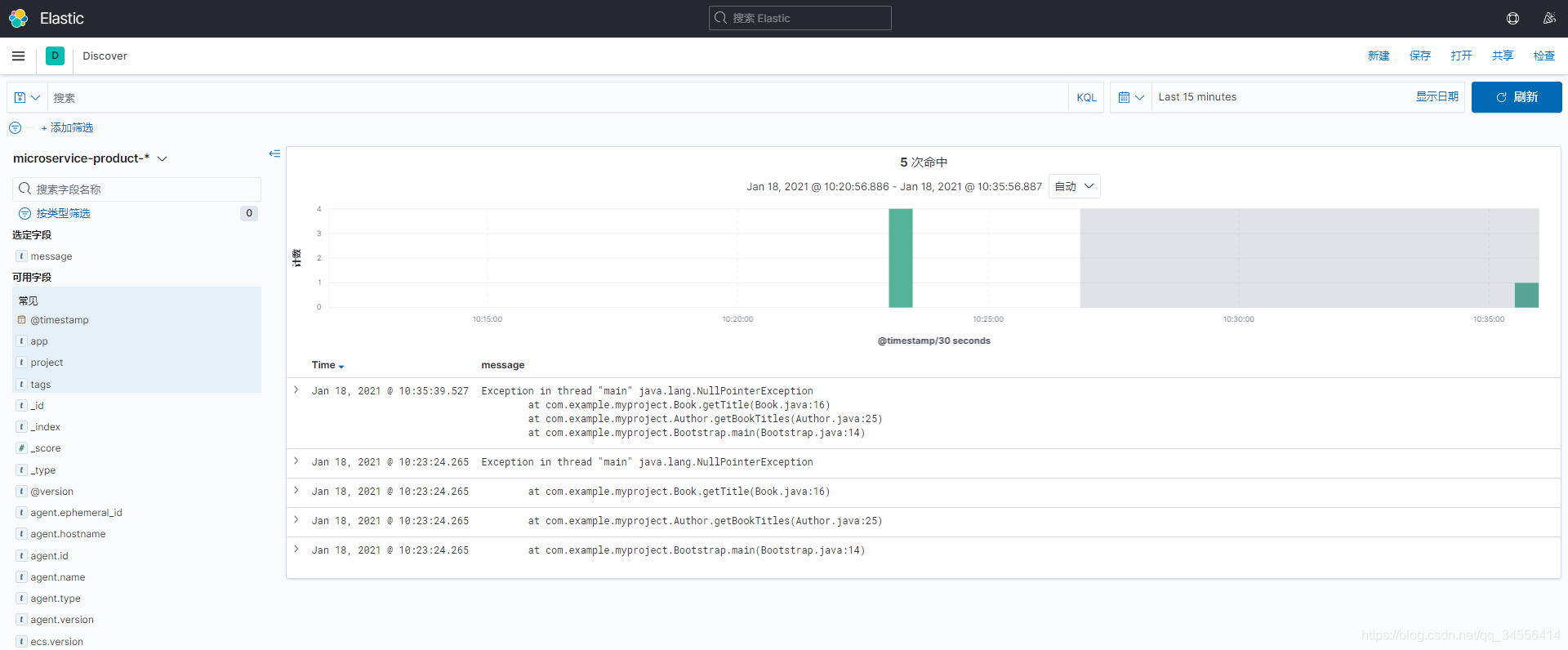
可以看到成功收集到java堆日志
目录 返回
首页