ELK Filebeat采集日志推送到Logstash
Filebeat介绍
logstash是可以日志采集,但是资源消耗比较大,其主要功能是日志的过滤以及格式化的输出,也就是独立作为日志格式化输出的。使用filebeat是代替其采集功能,消耗的资源小,哪台机器需要日志采集就部署filebeat。
filebeat.config.modules:
filebeat里面内置了一些模块,这些模块可以对特定的软件进行采集,像nginx mysql这些
可以使用其对应的模块而不需要自己配置相关的采集规则了。
如果不需要对日志的格式化处理的话直接将filebeat的日志输出到es里面,这样是最好的。如果日志本来就没有格式化那么需要grok去做正则的匹配才能去完成其格式化。
不做格式化存储,就直接使用原始的日志,那么就不经过logstash,这是比较建议的,因为logstash消耗比较大,因为要对日志处理,这样会影响入库的时间。
支持容器和k8s这块日志的采集
如果有些以特定字符开头的不想采集可以exclude_lines使用通配符匹配
Tags配置日志来源,也就是属于哪个项目的,哪个项目下的应用,方便在logstash去判断写到哪个索引
配置比较简单,指定采集哪些文件,或者不想采集哪些文件,或者想采集文件的那些行,不想采集哪些行,然后给采集的日志打上标记,标记属于哪个项目的。更加复杂的是在logstash那里去完成的,把日志推给logstash做结构化解析,更加细粒度的格式化
Filebeat部署
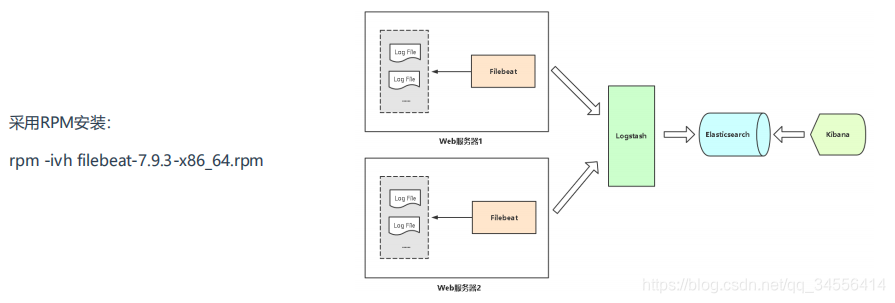
配置采集指定日志

推送到Logstash或ES

filebeat推送到logstash再到es实战如下
[root@localhost ~]# vim /etc/filebeat/filebeat.yml
[root@localhost ~]# cat /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/*.log
tags: ["nginx"]
fields_under_root: true
fields:
project: microservice
app: product
output.logstash:
hosts: ["192.168.179.102:5044"]fields_under_root: true 把数据放在事件的顶层
配置好输入,那么要配置输出到哪,推送到es是要修改索引名称的,要将其自己对索引管理的功能关闭,才能修改索引名。否者使用filebeat开头的索引名
[root@localhost ~]# systemctl restart filebeat
project: microservice
app: product
标志日志来源
Logstash这里支持beats插件,这里接收beats数据采集器发来的数据,像filebeat就是其中的一个
[root@localhost ~]# cat /usr/local/logstash/conf.d/test.conf
input {
beats {
host => "0.0.0.0"
port => 5044
}
}
filter {
json {
source => "message"
}
if [app] == "product" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-product-%{+YYYY.MM}"
}
}
} else if [app] == "gateway" {
mutate {
add_field => {
"[@metadata][target_index]" => "microservice-gateway-%{+YYYY.MM.dd}"
}
}
} else {
mutate {
add_field => {
"[@metadata][target_index]" => "unknown-%{+YYYY}"
}
}
}
}
output {
elasticsearch {
hosts => "192.168.179.102:9200"
index => "%{[@metadata][target_index]}"
}
}[root@localhost logs]# netstat -tpln | grep 5044
tcp6 0 0 :::5044 :::* LISTEN 2614/java 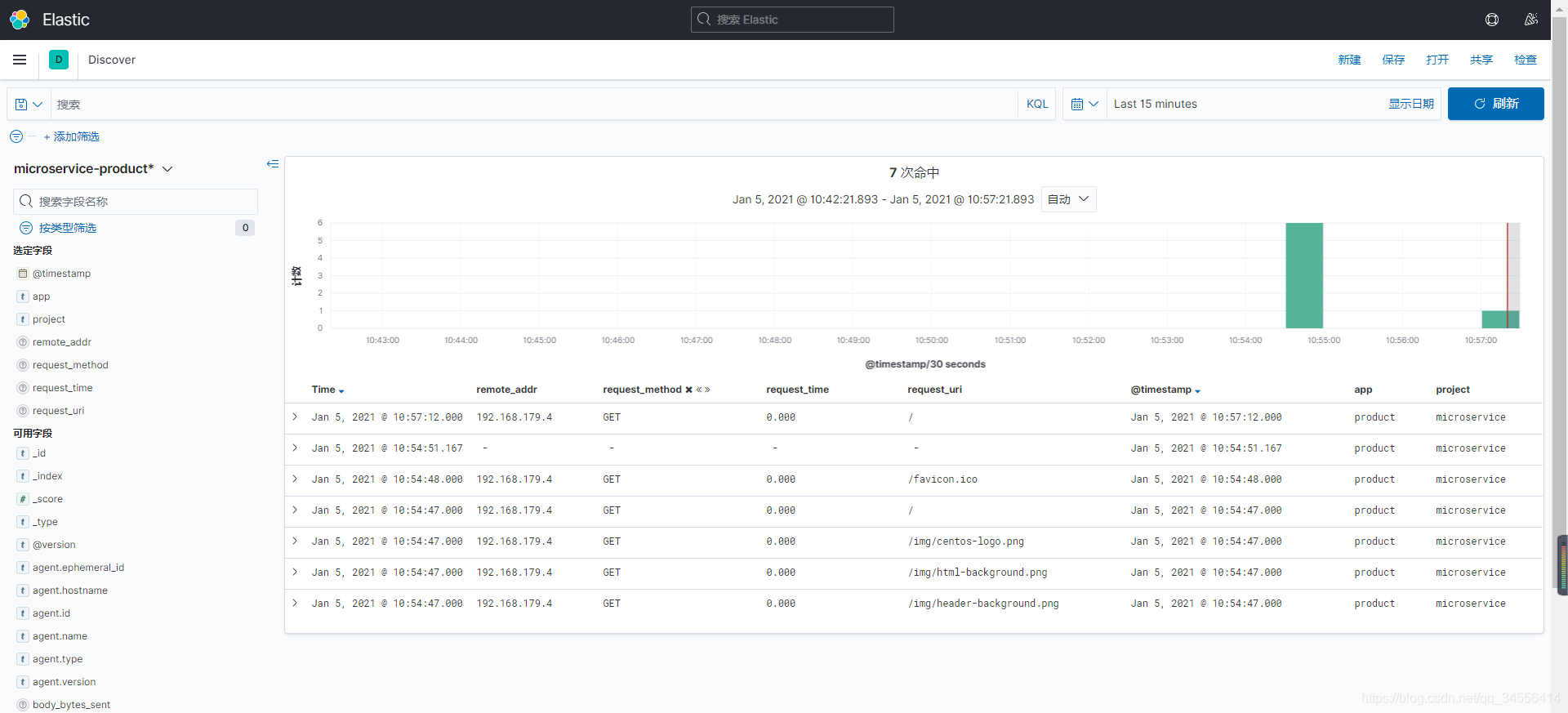
目录 返回
首页