ELK Logstash 自定义正则模式patterns_dir
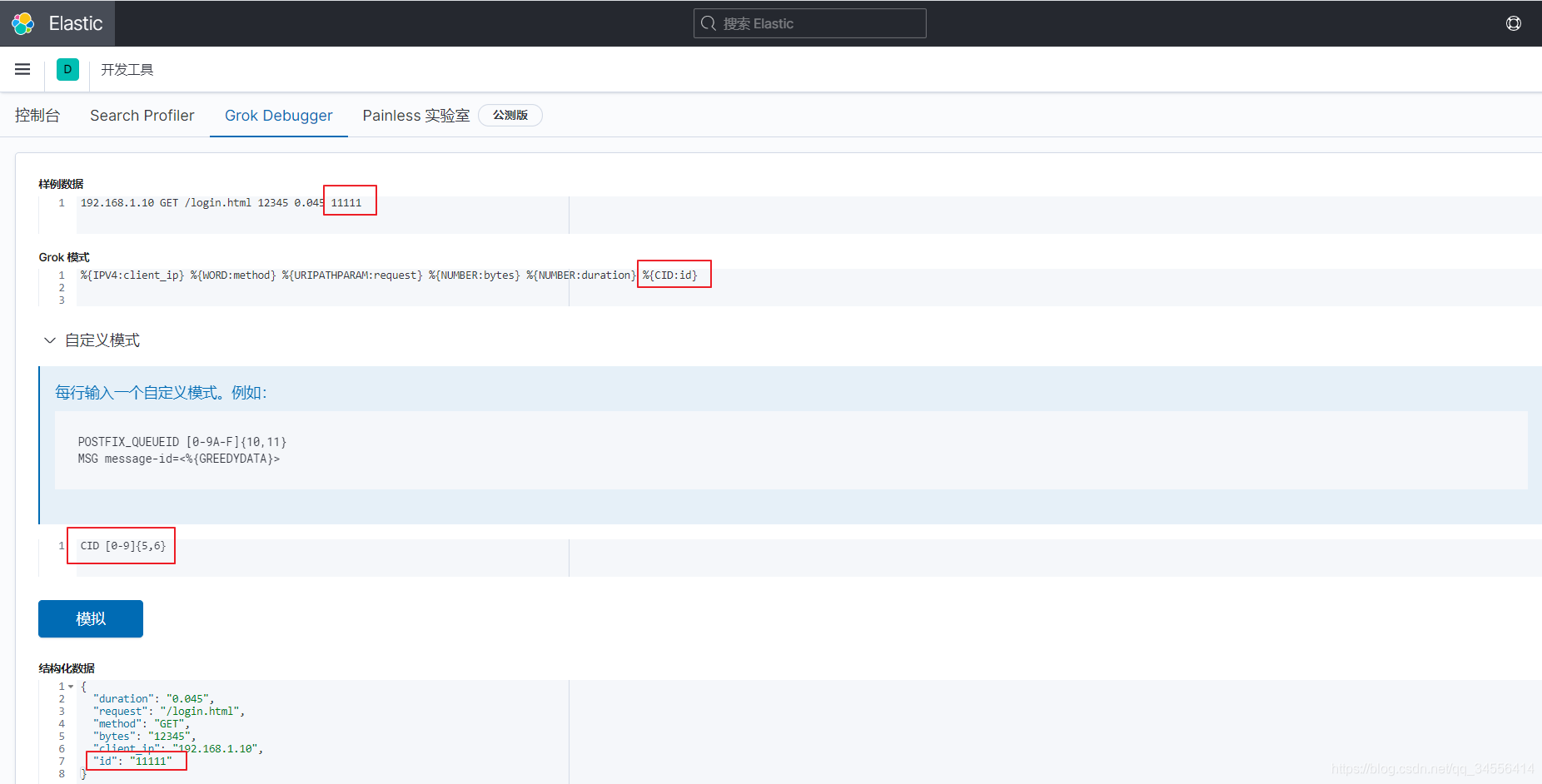
如果过滤插件里面自带的正则匹配无法满足你的需求,那么你可以写自己的正则匹配规则,如何使用,CID [0-9]{5,6}这个是自定义规则
[root@localhost ~]# cat /usr/local/logstash/conf.d/test.conf
input {
file {
path => "/var/log/test.log"
}
}
filter {
grok {
patterns_dir => "/opt/patterns"
match => {
"message" => "%{IPV4:client_ip} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} %{CID:id}"
}
}
}
output {
elasticsearch {
hosts => ["192.168.179.102:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}[root@localhost ~]# cat /opt/patterns
CID [0-9]{5,6}
[root@localhost ~]# echo "192.168.1.10 GET /login.html 12345 0.666 11111" >> /var/log/test.log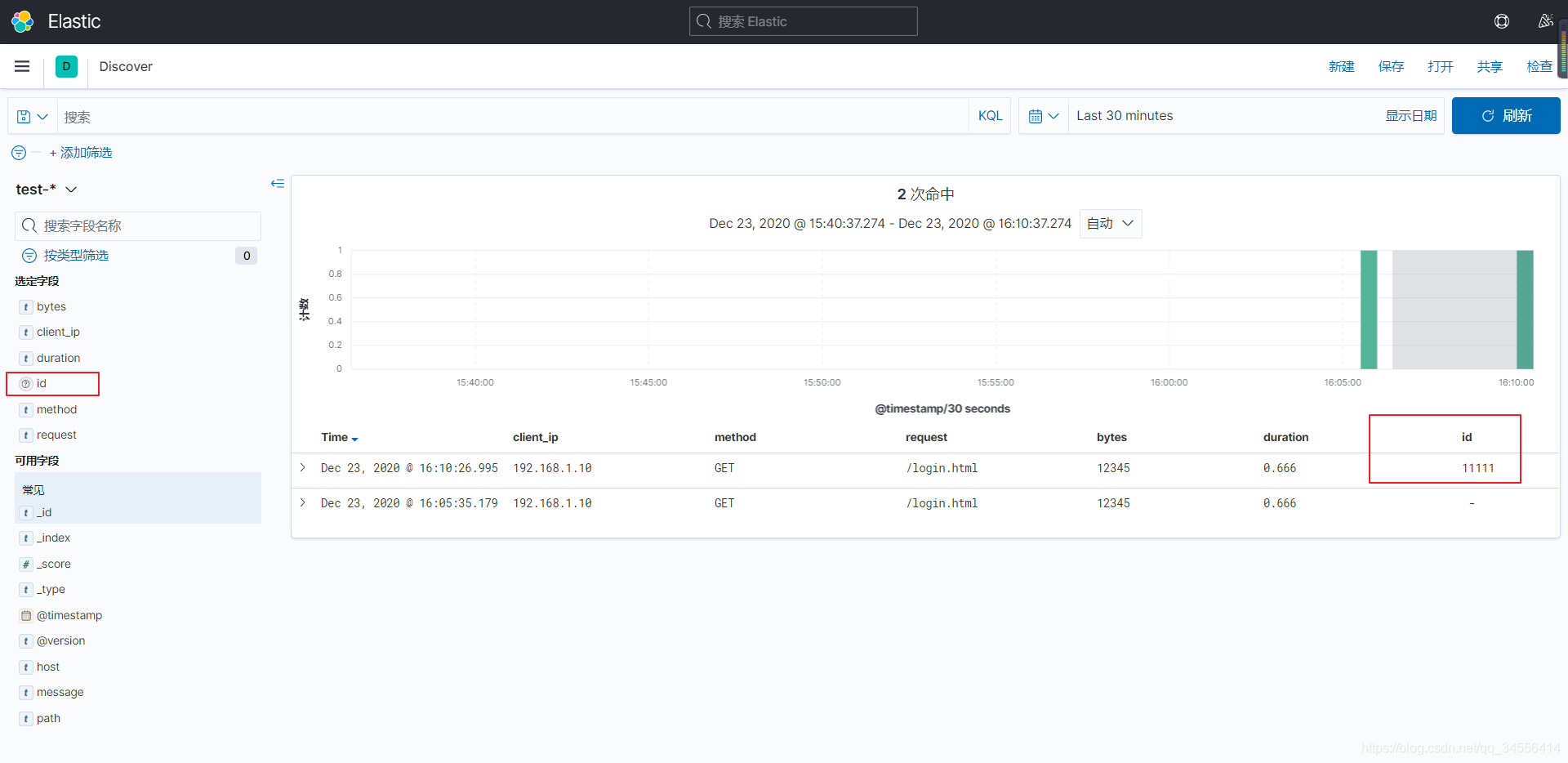
192.168.1.10 GET /login.html 12345
(?<ip>\d+\.\d+\.\d+\.\d+) (?<method>\w+) (?<request>/.*) (?<bytes>\d+)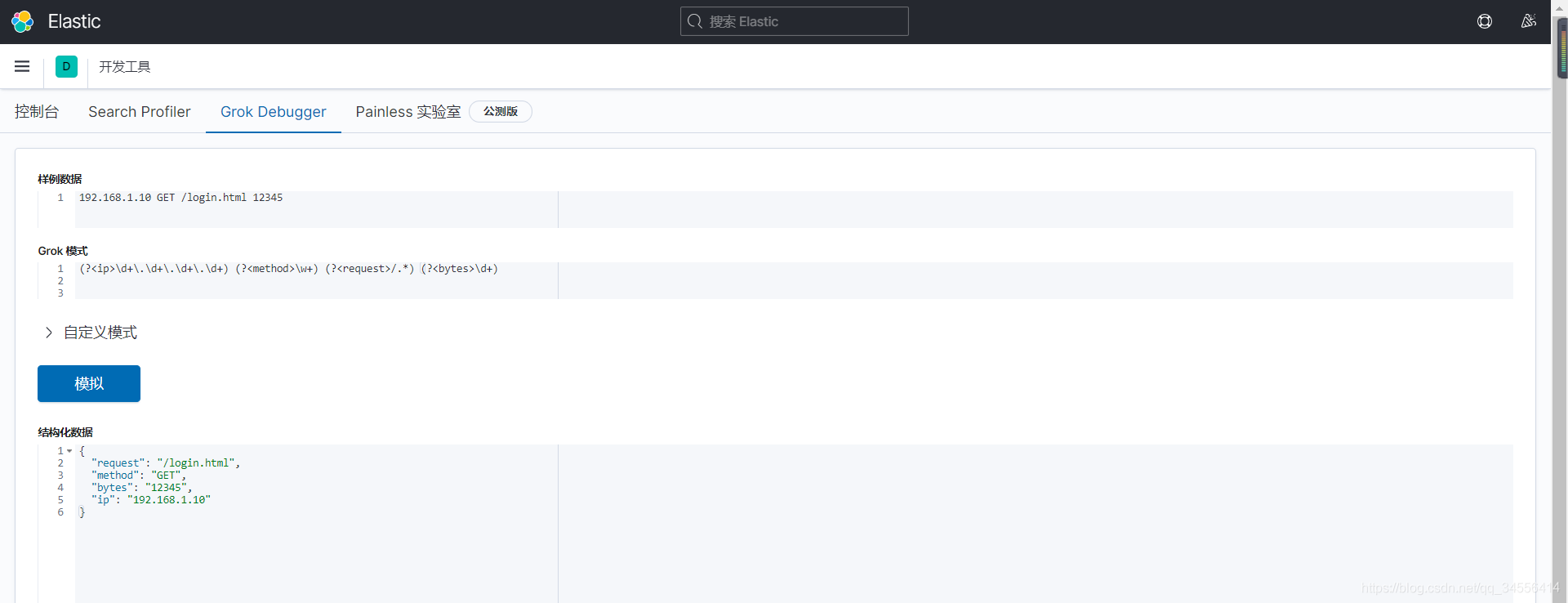
可以看到根据我们写的正则也可以进行字段的过滤,其他日志类型也可以写类似的
Grok多模式匹配(兼容多种日志)
如果一个日志文件下有多个日志格式怎么办?例如项目新版本添加一个日志字段,需要兼容旧日志匹配 使用多模式匹配,写多个正则表达式,只要满足其中一条就能匹配成功
例如:
# cat /opt/patterns
CID [0-9]{5,6}
TAG \w+filter {
grok {
patterns_dir =>"/opt/patterns"
match => [
"message", "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} %{CID:cid}",
"message", "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} %{EID:eid} %{TAG:tag}"
]
}
}Elasticsearch
grok {
match => ["message", "\[%{TIMESTAMP_ISO8601:timestamp}\]\[%{DATA:loglevel}%{SPACE}\]\[%{DATA:source}%{SPACE}\]%{SPACE}\[%{DATA:node}\]%{SPACE}\[%{DATA:index}\] %{NOTSPACE} \[%{DATA:updated-type}\]",
"message", "\[%{TIMESTAMP_ISO8601:timestamp}\]\[%{DATA:loglevel}%{SPACE}\]\[%{DATA:source}%{SPACE}\]%{SPACE}\[%{DATA:node}\] (\[%{NOTSPACE:Index}\]\[%{NUMBER:shards}\])?%{GREEDYDATA}"]
}
目录 返回
首页