ELK logstash过滤插件Grok的使用
过滤插件:Grok
如果业务项目都能够按照json格式输出的话那么处理起来会很容易,那么使用之前的json插件就可以快速解析为结构化的数据。但是有些日志的格式就不符合json格式也不能自定义,那么kv json插件就用不到的。
Grok插件可以支持正则,能够从非结构化的日志当中提取出关键字段,负责将非结构化数据解析为结构化的数据,logstash默认支持了很多正则
Grok插件:如果采集的日志格式是非结构化的,可以写正则表 达式提取,grok是正则表达式支持的实现。 常用字段:
- match 正则匹配模式
- patterns_dir 自定义正则模式文件
Logstash内置的正则匹配模式,在安装目录下可以看到,路径:
[root@localhost ~]# cat /usr/local/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/grok-patterns
USERNAME [a-zA-Z0-9._-]+
USER %{USERNAME}
EMAILLOCALPART [a-zA-Z][a-zA-Z0-9_.+-=:]+
正则匹配模式语法格式:%{SYNTAX:SEMANTIC}
- SYNTAX 模式名称,模式文件中的第一列
- SEMANTIC 匹配文件的字段名
例如: %{IP:client}
如何使用其内置的正则匹配模式?
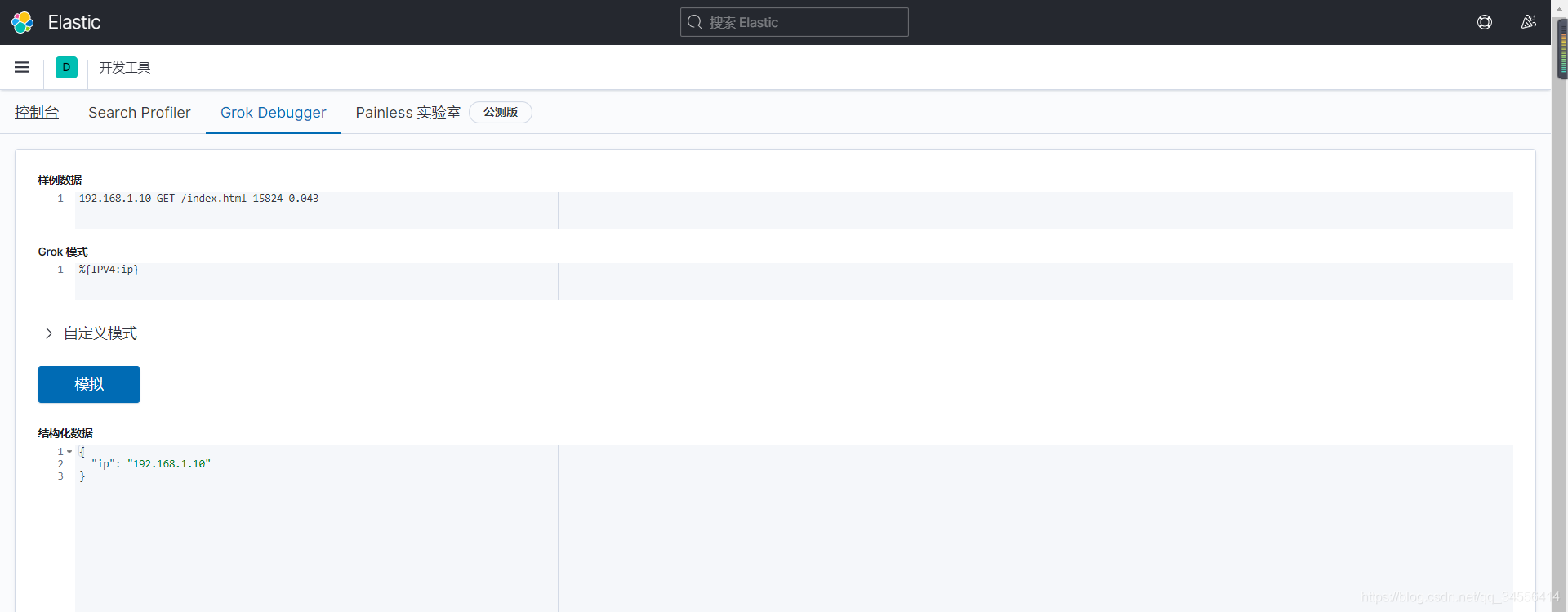
这里是kiban内置对grok表达式测试的功能
请求的客户端ip 请求的方法 请求的uri 返回数据大小 相应时间
192.168.1.10 GET /index.html 15824 0.043
现在使用grok的内置正则匹配模式,怎么取出来?
IPV4 (?<![0-9])(?:(?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5]))(?![0-9])
%{IPV4:client_ip}IPV4 内置正则表达式第一列的名称 冒号后面跟着的是你将匹配的结果保存在日志数据的字段名是什么,这个字段名会存在es里为我们在kibana里面去查询,所以这个字段要取名有意义
WORD \b\w+\b 匹配文本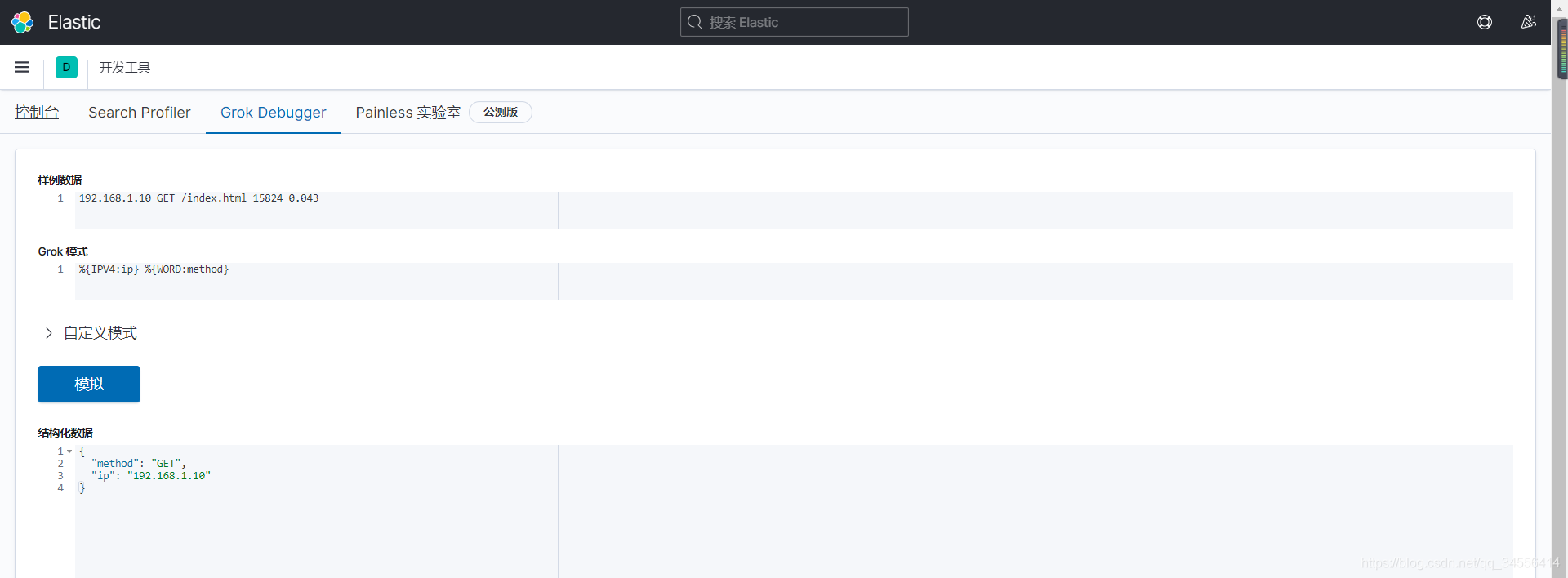
再匹配,这里是uri
URIPATHPARAM %{URIPATH}(?:%{URIPARAM})? 匹配uri路径 将数字配匹
将数字配匹
NUMBER (?:%{BASE10NUM})
%{IPV4:ip} %{WORD:method} %{URIPATHPARAM:uri} %{NUMBER:bytes} %{NUMBER:durtion}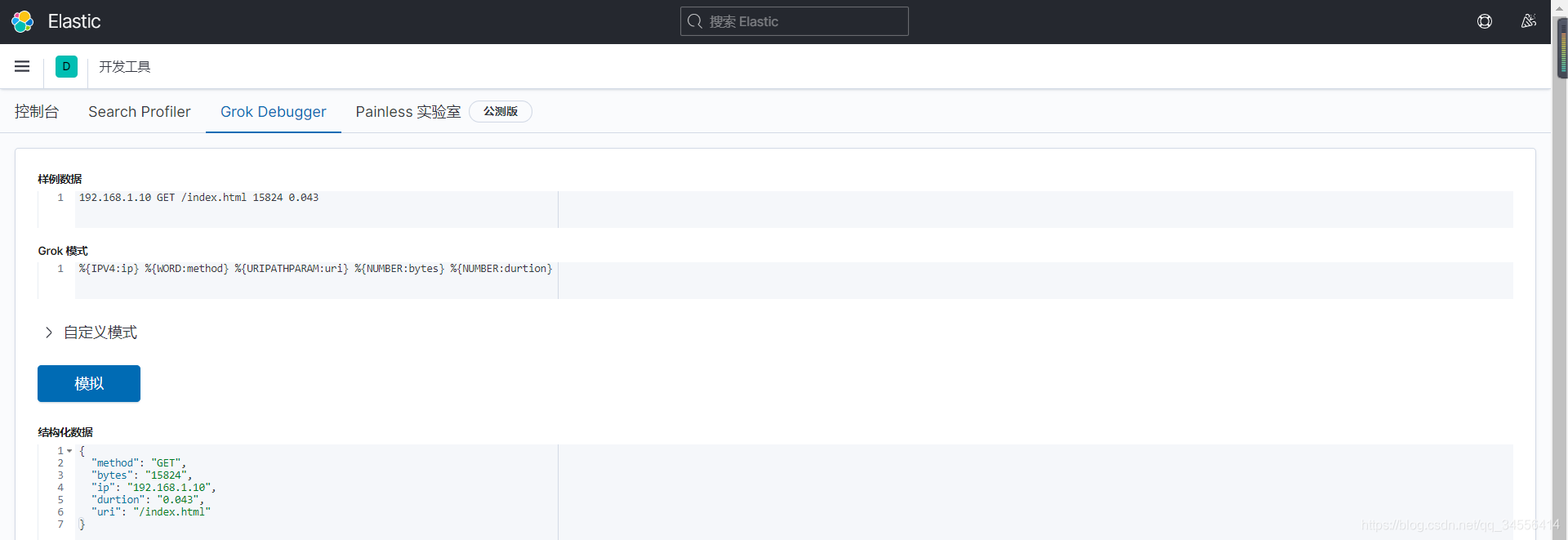
这里不使用grok做过滤
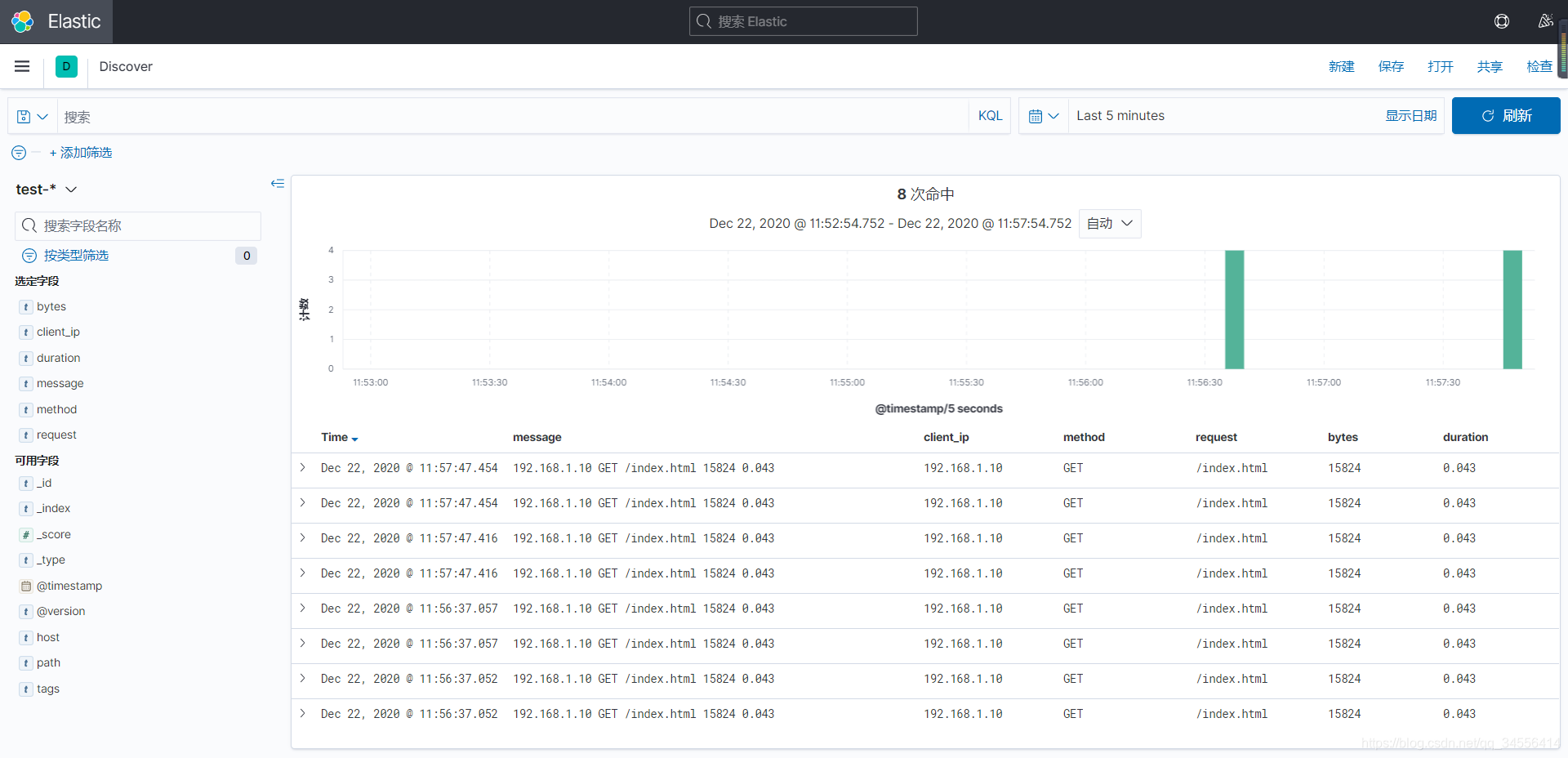
[root@localhost ~]# echo "192.168.1.10 GET /index.html 15824 0.043" >> /var/log/test.log可以看到在Kibana里面meaasge还是保存了原始的字段
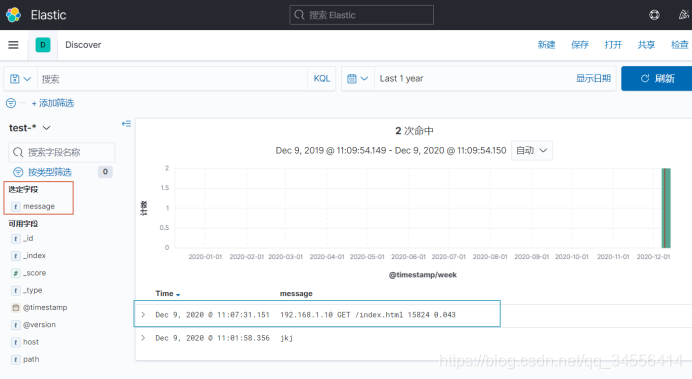
这行日志为非结构化的日志,就不利于我们去查询了,比如请求时间大于1S的请求,要进行优化处理。所以要将非结构化的日志转化为结构化的日志,将关键的信息转化为字段,这样就可以针对某个字段进行针对性查询。
[root@localhost ~]# cat /usr/local/logstash/conf.d/test.conf
input {
file {
path => "/var/log/test.log"
}
}
filter {
grok {
match => {
"message" => "%{IPV4:client_ip} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"
}
}
}
output {
elasticsearch {
hosts => ["192.168.179.102:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
[root@localhost ~]# echo "192.168.1.10 GET /login.html 12345 0.666" >> /var/log/test.log可以看到根据字段可以组合起来进行查询这就是做结构化日志最重要的目的
目录 返回
首页