Kubernetes 生命周期 钩子 pod hook
Pod Hook
Kubernetes 为我们的容器提供了生命周期钩子,就是我们说的Pod Hook,Pod Hook 是由 kubelet 发起的,当容器中的进程启动前或者容器中的进程终止之前运行,这是包含在容器的生命周期之中。我们可以同时为 Pod 中的所有容器都配置 hook。
Kubernetes 为我们提供了两种钩子函数:
- PostStart:这个钩子在容器创建后立即执行。但是,并不能保证钩子将在容器
ENTRYPOINT之前运行,因为没有参数传递给处理程序。主要用于资源部署、环境准备等。不过需要注意的是如果钩子花费太长时间以至于不能运行或者挂起, 容器将不能达到running状态。(PostStart 可以在容器启动之后就执行。但需要注意的是,此 hook 和容器里的 ENTRYPOINT 命令的执行顺序是不确定的。) - PreStop:这个钩子在容器终止之前立即被调用。它是阻塞的,意味着它是同步的, 所以它必须在删除容器的调用发出之前完成。主要用于优雅关闭应用程序、通知其他系统等。如果钩子在执行期间挂起, Pod阶段将停留在
running状态并且永不会达到failed状态。(PreStop 则在容器被终止之前被执行,是一种阻塞式的方式。执行完成后,Kubelet 才真正开始销毁容器。)
如果PostStart或者PreStop钩子失败, 它会杀死容器。所以我们应该让钩子函数尽可能的轻量。当然有些情况下,长时间运行命令是合理的, 比如在停止容器之前预先保存状态。
prestop
当用户请求删除含有 pod 的资源对象时,K8S 为了让应用程序优雅关闭(即让应用程序完成正在处理的请求后,再关闭软件),K8S提供两种信息通知:
- 默认:K8S 通知 node 执行
docker stop命令,docker 会先向容器中PID为1的进程发送系统信号SIGTERM,然后等待容器中的应用程序终止执行,如果等待时间达到设定的超时时间,或者默认超时时间(30s),会继续发送SIGKILL的系统信号强行 kill 掉进程。 - 使用 pod 生命周期(利用
PreStop回调函数),它执行在发送终止信号之前。
默认所有的优雅退出时间都在30秒内。kubectl delete 命令支持 --grace-period=<seconds>选项,这个选项允许用户用他们自己指定的值覆盖默认值。值’0’代表 强制删除 pod. 在 kubectl 1.5 及以上的版本里,执行强制删除时必须同时指定 --force --grace-period=0。
强制删除一个 pod 是从集群状态还有 etcd 里立刻删除这个 pod。 当 Pod 被强制删除时, api 服务器不会等待来自 Pod 所在节点上的 kubelet 的确认信息:pod 已经被终止。在 API 里 pod 会被立刻删除,在节点上, pods 被设置成立刻终止后,在强行杀掉前还会有一个很小的宽限期。
同 readinessProbe一样,hook 也有类似的 Handler:
-
Exec 用来执行 Shell 命令;
-
HTTPGet 可以执行 HTTP 请求。
我们来看个例子:
[root@k8s-master ~]# mkdir -p /data/nginx/html
[root@k8s-master ~]# cat hook.yml
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
namespace: default
spec:
containers:
- name: lifecycle-demo-container
image: nginx:1.19
ports:
- containerPort: 80
volumeMounts:
- name: message
mountPath: /usr/share/nginx/html
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/nginx/html/index.html"]
preStop:
exec:
command: ["/bin/sh","-c","echo Hello from the preStop handler > /usr/share/nginx/html/index.html"]
volumes:
- name: message
hostPath:
path: /data/nginx/html
[root@k8s-master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
lifecycle-demo 1/1 Running 0 13s 10.244.0.18 k8s-master <none> <none>
[root@k8s-master ~]# curl 10.244.0.18:80
Hello from the postStart handler
[root@k8s-master html]# cat index.html
Hello from the postStart handler如果将容器销毁 ,PreStop这个钩子在容器终止之前立即被调用,可以看到结果如下
[root@k8s-master ~]# kubectl delete -f hook.yml
pod "lifecycle-demo" deleted
[root@k8s-master html]# cat index.html
Hello from the preStop handler我们可以借助preStop以优雅的方式停掉 Nginx 服务,从而避免强制停止容器,造成正在处理的请求无法响应。
preStop:
exec:
command: ["/usr/sbin/nginx","-s","quit"]
总结
创建容器后,Kubernetes立即发送postStart事件。但是,不能保证在调用Container的入口点之前先调用postStart处理程序。postStart处理程序相对于Container的代码异步运行,但是Kubernetes对容器的管理会阻塞,直到postStart处理程序完成。在postStart处理程序完成之前,容器的状态不会设置为RUNNING。
Kubernetes会在容器终止之前立即发送preStop事件。除非Pod的宽限期到期,否则Kubernetes对Container的管理将一直保持到preStop处理程序完成为止。
注意: Kubernetes仅在Pod终止时才发送preStop事件。这意味着在Pod完成时不会调用preStop挂钩。
Ingress Controller 的yml文件里面定义(使用钩子在程序关闭之前做了一定的处理)
lifecycle:
preStop:
exec:
command:
- /wait-shutdown
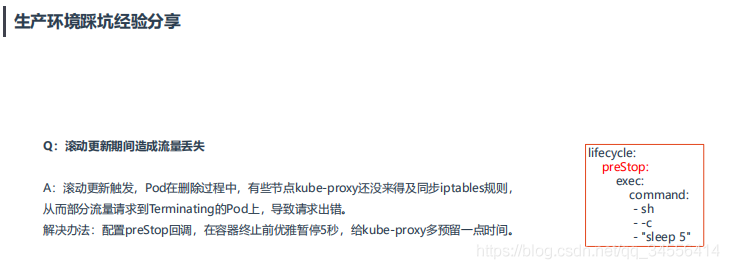
Q:滚动更新期间造成流量丢失
A:滚动更新触发,Pod在删除过程中,有些节点kube-proxy还没来得及同步iptables规则,从而部分流量请求到Terminating的Pod上,导致请求出错。
解决办法:配置preStop回调,在容器终止前优雅暂停5秒,给kube-proxy多预留一点时间。
当我们更新deployment的镜像的时候,会触发滚动更新,这是默认的升级策略,关掉一个处于term状态,也就是不能处理请求,马上关闭了
Kubeproxy是负责更新规则的,是有周期性的更新规则,如果还没有来得及更新规则还是用的之前的IP,那么后面来的流量再分配过来就会失效导致请求的出错
这个问题的产生是下线一个pod与kube-proxy刷新转发的规则这个时间差并不是保持同步的,也就是这个pod被下线掉了,马上就如kube-proxy去更新转发的规则。这不是同步的,因为kube-proxy是周期性的去同步
这种情况主要适用于走service的服务,微服务没有走service是没有的,部署单体应用是很容易碰见这种情况
目录 返回
首页