Ceph ceph在普罗米修斯当中的监控指标
6.1. Ceph : Embedded exporter (13 rules)
# 6.1.1. Ceph State
Ceph instance unhealthy
- alert: CephState
expr: ceph_health_status != 0
for: 0m
labels:
severity: critical
annotations:
summary: Ceph State (instance {
{ $labels.instance }})
description: "Ceph instance unhealthy\n VALUE = {
{ $value }}\n LABELS = {
{ $labels }}"
# 6.1.2. Ceph monitor clock skew
Ceph monitor clock skew detected. Please check ntp and hardware clock settings
- alert: CephMonitorClockSkew
expr: abs(ceph_monitor_clock_skew_seconds) > 0.2
for: 2m
labels:
severity: warning
annotations:
summary: Ceph monitor clock skew (instance {
{ $labels.instance }})
description: "Ceph monitor clock skew detected. Please check ntp and hardware clock settings\n VALUE = {
{ $value }}\n LABELS = {
{ $labels }}"
# 6.1.4. Ceph OSD Down
Ceph Object Storage Daemon Down
- alert: CephOsdDown
expr: ceph_osd_up == 0
for: 0m
labels:
severity: critical
annotations:
summary: Ceph OSD Down (instance {
{ $labels.instance }})
description: "Ceph Object Storage Daemon Down\n VALUE = {
{ $value }}\n LABELS = {
{ $labels }}"
# 6.1.5. Ceph high OSD latency
Ceph Object Storage Daemon latency is high. Please check if it doesn't stuck in weird state.
- alert: CephHighOsdLatency
expr: ceph_osd_perf_apply_latency_seconds > 5
for: 1m
labels:
severity: warning
annotations:
summary: Ceph high OSD latency (instance {
{ $labels.instance }})
description: "Ceph Object Storage Daemon latency is high. Please check if it doesn't stuck in weird state.\n VALUE = {
{ $value }}\n LABELS = {
{ $labels }}"
# 6.1.6. Ceph OSD low space
Ceph Object Storage Daemon is going out of space. Please add more disks.
- alert: CephOsdLowSpace
expr: ceph_osd_utilization > 90
for: 2m
labels:
severity: warning
annotations:
summary: Ceph OSD low space (instance {
{ $labels.instance }})
description: "Ceph Object Storage Daemon is going out of space. Please add more disks.\n VALUE = {
{ $value }}\n LABELS = {
{ $labels }}"
# 6.1.7. Ceph OSD reweighted
Ceph Object Storage Daemon takes too much time to resize.
- alert: CephOsdReweighted
expr: ceph_osd_weight < 1
for: 2m
labels:
severity: warning
annotations:
summary: Ceph OSD reweighted (instance {
{ $labels.instance }})
description: "Ceph Object Storage Daemon takes too much time to resize.\n VALUE = {
{ $value }}\n LABELS = {
{ $labels }}"
# 6.1.8. Ceph PG down
Some Ceph placement groups are down. Please ensure that all the data are available.
- alert: CephPgDown
expr: ceph_pg_down > 0
for: 0m
labels:
severity: critical
annotations:
summary: Ceph PG down (instance {
{ $labels.instance }})
description: "Some Ceph placement groups are down. Please ensure that all the data are available.\n VALUE = {
{ $value }}\n LABELS = {
{ $labels }}"
# 6.1.9. Ceph PG incomplete
Some Ceph placement groups are incomplete. Please ensure that all the data are available.
- alert: CephPgIncomplete
expr: ceph_pg_incomplete > 0
for: 0m
labels:
severity: critical
annotations:
summary: Ceph PG incomplete (instance {
{ $labels.instance }})
description: "Some Ceph placement groups are incomplete. Please ensure that all the data are available.\n VALUE = {
{ $value }}\n LABELS = {
{ $labels }}"
# 6.1.10. Ceph PG inconsistant
Some Ceph placement groups are inconsitent. Data is available but inconsistent across nodes.
- alert: CephPgInconsistant
expr: ceph_pg_inconsistent > 0
for: 0m
labels:
severity: warning
annotations:
summary: Ceph PG inconsistant (instance {
{ $labels.instance }})
description: "Some Ceph placement groups are inconsitent. Data is available but inconsistent across nodes.\n VALUE = {
{ $value }}\n LABELS = {
{ $labels }}"
# 6.1.11. Ceph PG activation long
Some Ceph placement groups are too long to activate.
- alert: CephPgActivationLong
expr: ceph_pg_activating > 0
for: 2m
labels:
severity: warning
annotations:
summary: Ceph PG activation long (instance {
{ $labels.instance }})
description: "Some Ceph placement groups are too long to activate.\n VALUE = {
{ $value }}\n LABELS = {
{ $labels }}"
# 6.1.12. Ceph PG backfill full
Some Ceph placement groups are located on full Object Storage Daemon on cluster. Those PGs can be unavailable shortly. Please check OSDs, change weight or reconfigure CRUSH rules.
- alert: CephPgBackfillFull
expr: ceph_pg_backfill_toofull > 0
for: 2m
labels:
severity: warning
annotations:
summary: Ceph PG backfill full (instance {
{ $labels.instance }})
description: "Some Ceph placement groups are located on full Object Storage Daemon on cluster. Those PGs can be unavailable shortly. Please check OSDs, change weight or reconfigure CRUSH rules.\n VALUE = {
{ $value }}\n LABELS = {
{ $labels }}"
# 6.1.13. Ceph PG unavailable
Some Ceph placement groups are unavailable.
- alert: CephPgUnavailable
expr: ceph_pg_total - ceph_pg_active > 0
for: 0m
labels:
severity: critical
annotations:
summary: Ceph PG unavailable (instance {
{ $labels.instance }})
description: "Some Ceph placement groups are unavailable.\n VALUE = {
{ $value }}\n LABELS = {
{ $labels }}"
在普罗米修斯当作使用
[root@localhost prometheus]# vim prometheus.yml
rule_files:
- "rules/*.yml"
- job_name: 'ceph_cluster'
static_configs:
- targets: ['192.168.179.104:9283']
labels:
instance: ceph[root@localhost prometheus]# cd rules/
[root@localhost rules]# ls ceph.yml
ceph.yml
[root@localhost rules]# cat ceph.yml
groups:
- name: ceph
rules:
- alert: CephState
expr: ceph_health_status != 0
for: 0m
labels:
severity: critical
annotations:
summary: Ceph State (instance {
{ $labels.instance }})
description: "Ceph instance unhealthy\n VALUE = {
{ $value }}\n LABELS = {
{ $labels }}"
- alert: CephMonitorClockSkew
expr: abs(ceph_monitor_clock_skew_seconds) > 0.2
for: 2m
labels:
severity: warning
annotations:
summary: Ceph monitor clock skew (instance {
{ $labels.instance }})
description: "Ceph monitor clock skew detected. Please check ntp and hardware clock settings\n VALUE = {
{ $value }}\n LABELS = {
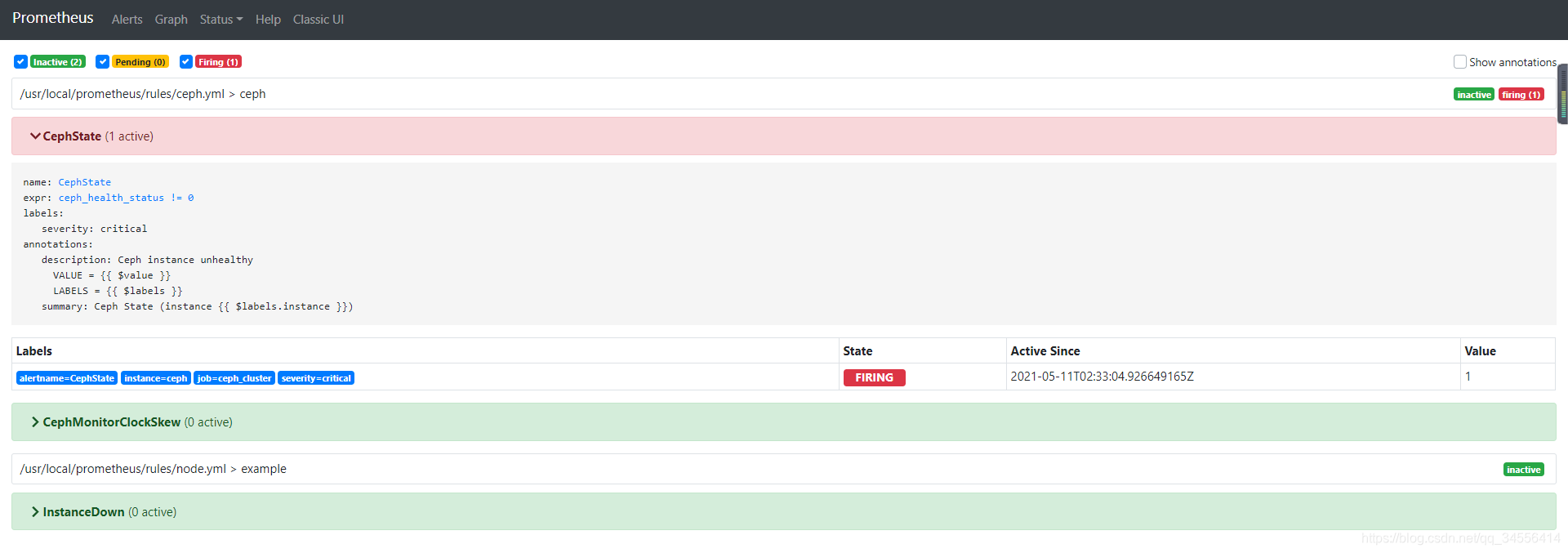
{ $labels }}"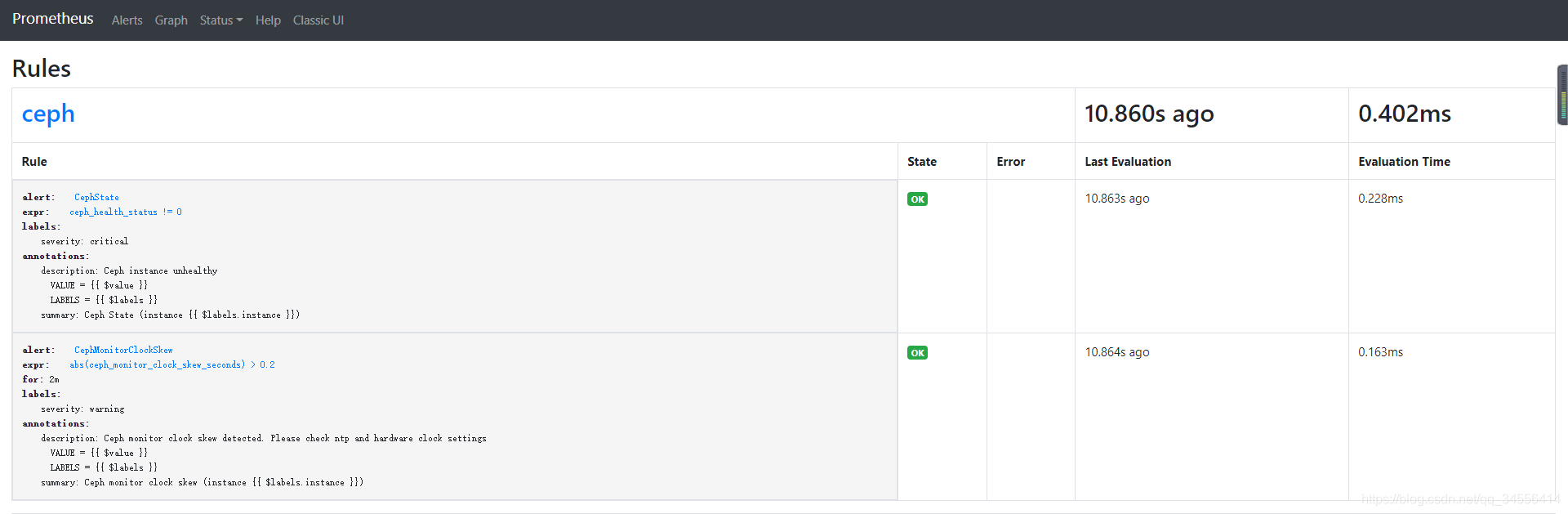
目录 返回
首页