Docker 深入剖析 Linux 容器
今天的内容主要分成以下三个部分:
- 资源隔离和限制;
- 容器镜像的构成;
- 容器引擎的构成;
前两个部分就是资源隔离和限制还有容器镜像的构成,第三部分会以一个业界比较成熟的容器引擎为例去讲解一下容器引擎的构成。
容器
容器是一种轻量级的虚拟化技术,因为它跟虚拟机比起来,它少了一层 hypervisor 层。先看一下下面这张图,这张图简单描述了一个容器的启动过程。
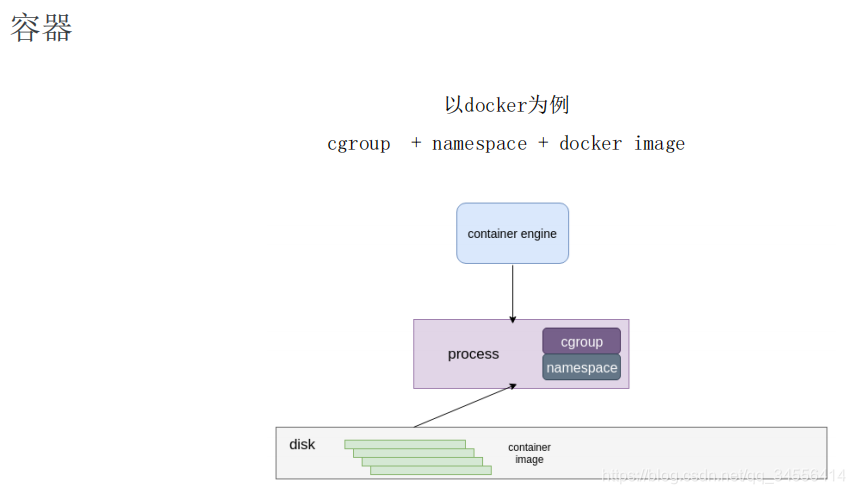
最下面是一个磁盘,容器的镜像是存储在磁盘上面的。上层是一个容器引擎,容器引擎可以是 docker,也可以是其它的容器引擎。引擎向下发一个请求,比如说创建容器,然后这时候它就把磁盘上面的容器镜像,运行成在宿主机上的一个进程。
对于容器来说,最重要的是怎么保证这个进程所用到的资源是被隔离和被限制住的,在 Linux 内核上面是由 cgroup 和 namespace 这两个技术来保证的。接下来以 docker 为例,来详细介绍一下资源隔离和容器镜像这两部分内容。
一、资源隔离和限制
namespace
namespace 是用来做资源隔离的,在 Linux 内核上有七种 namespace,docker 中用到了前六种。第七种 cgroup namespace 在 docker 本身并没有用到,但是在 runC 实现中实现了 cgroup namespace。
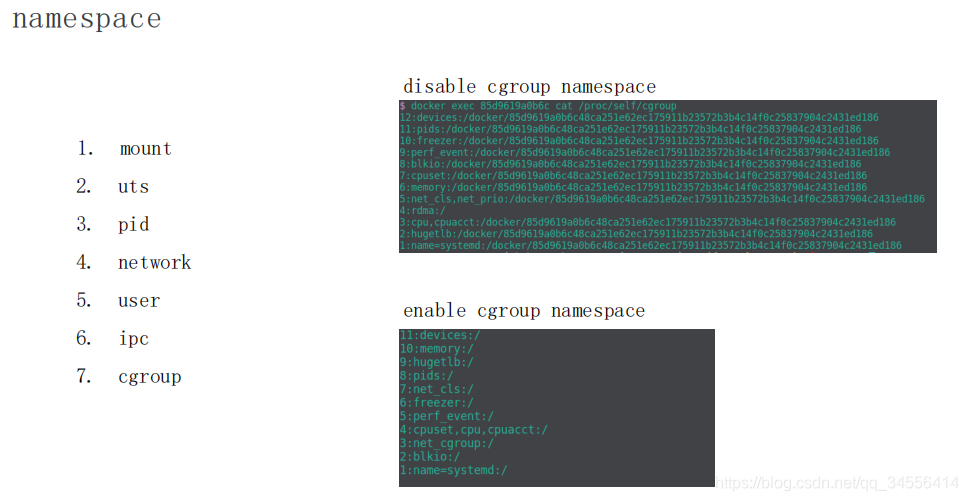
我们先从头看一下:
- 第一个是 mout namespace。mout namespace 就是保证容器看到的文件系统的视图,是容器镜像提供的一个文件系统,也就是说它看不见宿主机上的其他文件,除了通过 -v 参数 bound 的那种模式,是可以把宿主机上面的一些目录和文件,让它在容器里面可见的。
- 第二个是 uts namespace,这个 namespace 主要是隔离了 hostname 和 domain。
- 第三个是 pid namespace,这个 namespace 是保证了容器的 init 进程是以 1 号进程来启动的。
- 第四个是网络 namespace,除了容器用 host 网络这种模式之外,其他所有的网络模式都有一个自己的 network namespace 的文件。
- 第五个是 user namespace,这个 namespace 是控制用户 UID 和 GID 在容器内部和宿主机上的一个映射,不过这个 namespace 用的比较少。
- 第六个是 IPC namespace,这个 namespace 是控制了进程兼通信的一些东西,比方说信号量。
- 第七个是 cgroup namespace,上图右边有两张示意图,分别是表示开启和关闭 cgroup namespace。用 cgroup namespace 带来的一个好处是容器中看到的 cgroup 视图是以根的形式来呈现的,这样的话就和宿主机上面进程看到的 cgroup namespace 的一个视图方式是相同的。另外一个好处是让容器内部使用 cgroup 会变得更安全。
这里我们简单用 unshare 示例一下 namespace 创立的过程。容器中 namespace 的创建其实都是用 unshare 这个系统调用来创建的。
容器中常用的 cgroup
接下来看一下容器中常用的 cgroup。Linux 内核本身是提供了很多种 cgroup,但是 docker 容器用到的大概只有下面六种:

- 第一个是 CPU,CPU 一般会去设置 cpu share 和 cupset,控制 CPU 的使用率。
- 第二个是 memory,是控制进程内存的使用量。
- 第三个 device ,device 控制了你可以在容器中看到的 device 设备。
- 第四个 freezer。它和第三个 cgroup(device)都是为了安全的。当你停止容器的时候,freezer 会把当前的进程全部都写入 cgroup,然后把所有的进程都冻结掉,这样做的目的是,防止你在停止的时候,有进程会去做 fork。这样的话就相当于防止进程逃逸到宿主机上面去,是为安全考虑。
- 第五个是 blkio,blkio 主要是限制容器用到的磁盘的一些 IOPS 还有 bps 的速率限制。因为 cgroup 不唯一的话,blkio 只能限制同步 io,docker io 是没办法限制的。
- 第六个是 pid cgroup,pid cgroup 限制的是容器里面可以用到的最大进程数量。
不常用的 cgroup
也有一部分是 docker 容器没有用到的 cgroup。容器中常用的和不常用的,这个区别是对 docker 来说的,因为对于 runC 来说,除了最下面的 rdma,所有的 cgroup 其实都是在 runC 里面支持的,但是 docker 并没有开启这部分支持,所以说 docker 容器是不支持下图这些 cgroup 的。

二、容器镜像
docker images
接下来我们讲一下容器镜像,以 docker 镜像为例去讲一下容器镜像的构成。

docker 镜像是基于联合文件系统的。简单描述一下联合文件系统:大概的意思就是说,它允许文件是存放在不同的层级上面的,但是最终是可以通过一个统一的视图,看到这些层级上面的所有文件。
以 overlay 为例
存储流程
接下来我们以 overlay 这个文件系统为例,看一下 docker 镜像是怎么在磁盘上进行存储的。先看一下下面这张图,简单地描述了 overlay 文件系统的工作原理 。

最下层是一个 lower 层,也就是镜像层,它是一个只读层。右上层是一个 upper 层,upper 是容器的读写层,upper 层采用了写实复制的机制,也就是说只有对某些文件需要进行修改的时候才会从 lower 层把这个文件拷贝上来,之后所有的修改操作都会对 upper 层的副本进行修改。
upper 并列的有一个 workdir,它的作用是充当一个中间层的作用。也就是说,当对 upper 层里面的副本进行修改时,会先放到 workdir,然后再从 workdir 移到 upper 里面去,这个是 overlay 的工作机制。
最上面的是 mergedir,是一个统一视图层。从 mergedir 里面可以看到 upper 和 lower 中所有数据的整合,然后我们 docker exec 到容器里面,看到一个文件系统其实就是 mergedir 统一视图层。
文件操作
接下来我们讲一下基于 overlay 这种存储,怎么对容器里面的文件进行操作?

先看一下读操作,容器刚创建出来的时候,upper 其实是空的。这个时候如果去读的话,所有数据都是从 lower 层读来的。
写操作如刚才所提到的,overlay 的 upper 层有一个写实数据的机制,对一些文件需要进行操作的时候,overlay 会去做一个 copy up 的动作,然后会把文件从 lower 层拷贝上来,之后的一些写修改都会对这个部分进行操作。
然后看一下删除操作,overlay 里面其实是没有真正的删除操作的。它所谓的删除其实是通过对文件进行标记,然后从最上层的统一视图层去看,看到这个文件如果做标记,就会让这个文件显示出来,然后就认为这个文件是被删掉的。这个标记有两种方式:
- 一种是 whiteout 的方式。
- 第二个就是通过设置目录的一个扩展权限,通过设置扩展参数来做到目录的删除。
目录 返回
首页