Docker安装部署MySQL+Canal+Kafka+Camus+HIVE数据实时同步
Docker安装部署MySQL+Canal+Kafka+Camus+HIVE数据实时同步
因为公司业务需求要将mysql的数据实时同步到hive中,在网上找到一套可用的方案,即MySQL+Canal+Kafka+Camus+HIVE的数据流通方式,因为是首次搭建,所以暂时使用伪分布式的搭建方案。
一、安装docker
安装docker的教程网上一搜一大把,请参考:
二、docker安装MySQL
安装教程网上也有很多,请参考:
1. 开启 Binlog 写入功能
安装完成后,要配置MySQL,开启binlog的写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下:
vim /etc/my.cnf
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不能和 canal 的 slaveId 重复
#重启MySQL数据库
service mysql restart
2. 创建并授权canal用户
授权 canal 连接 MySQL账号具有作为 MySQL slave的权限,如果已有账户可直接 grant
CREATE USER canal IDENTIFIED BY 'canal';
GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' IDENTIFIED BY 'mypassword' WITH GRANT OPTION;
#一定要刷新权限
FLUSH PRIVILEGES;
三、docker安装zookeeper
安装kafka的前置条件是安装zookeeper,
在DockerHub中搜索到官方镜像直接拉取
docker pull zookeeper
然后执行
docker run -d --name=zookeeper -p 2181:2181 --privileged=true --restart always -v /etc/localtime:/etc/localtime zookeeper
开放2181端口,因为是单机模式的,暂不需要做其他配置
四、docker安装kafka
1. 安装kafka
在DockerHub中搜索到stars最多的一个kafka镜像是:wurstmeister/kafka,拉取镜像
docker pull wurstmeister/kafka
然后执行
docker run -d --restart=always --privileged=true --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 \
-e KAFKA_ZOOKEEPER_CONNECT=192.168.0.188:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://124.xx.xx.xxx:9092 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -v /etc/localtime:/etc/localtime -t wurstmeister/kafka
参数说明:
-e KAFKA_BROKER_ID=0 在kafka集群中,每个kafka都有一个BROKER_ID来区分自己
-e KAFKA_ZOOKEEPER_CONNECT=192.168.0.188:2181 配置zookeeper管理kafka的路径192.168.0.188:2181,内网通讯IP
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://124.xx.xx.xxx:9092 把kafka的地址端口注册给zookeeper
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 配置kafka的监听端口
-v /etc/localtime:/etc/localtime 容器时间同步虚拟机的时间
2. 验证kafka是否可用
进入docker容器
docker exec -it kafka /bin/bash
本窗口作为消息生产者,输入
kafka-console-producer.sh --broker-list 192.168.0.188:9092 --topic test
再打开一个窗口作为消息的消费者,输入
kafka-console-consumer.sh --bootstrap-server 192.168.0.188:9092 --topic test --from-beginning
注意,此处的IP为自己服务器的IP,不要照搬!
在生产者窗口输入消息,消费者窗口收到相同的消息即为成功
五、docker安装canal
1. 拉取镜像
在DockerHub中搜索到官方镜像直接拉取
docker pull canal/canal-server
2. 构建容器
docker run -d --restart=always --name canal -p 11111:11111 -v /etc/localtime:/etc/localtime canal/canal-server
3. 进入容器
docker exec -it canal /bin/bash
4. 编辑配置文件
有两个配置文件,此处只列出需要修改的部分
(1).修改instance配置文件
vi /home/admin/canal-server/conf/example/instance.properties
修改部分配置
# mysql主库的连接地址
canal.instance.master.address=xxx.xxx.x.xxx:3306
# mysql主库的账号密码编码方式
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
# 需要监听的表
canal.instance.filter.regex=orders\\..*,users\\..*,goods\\..*
# topic的生成方式
canal.mq.topic=otherMsg
# 需要根据表名自动在kafka上生成的topic名称
canal.mq.dynamicTopic=users\\.user_detail;orders\\.order_detail
canal.instance.filter.regex
监控哪些表的正则配置:
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
所有表:.* or .*\\…*
canal schema下所有表: canal\\…*
canal下的以canal打头的表:canal\\.canal.*
canal schema下的一张表:canal.test1
多个规则组合使用:canal\\…*,mysql.test1,mysql.test2 (逗号分隔)
注意:此过滤条件只针对row模式的数据有效(mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤)
canal.mq.topic配置的是不符合canal.instance.filter.regex条件的binlog消息要推送到的topic,如果不配置此项,canal会有循环报错信息但不影响使用
canal.mq.dynamicTopic配置规则:
表达式如果只有库名则匹配库名的数据都会发送到对应名称topic;例如库名为examp2,则自动生成的topic名为examp2
如果是库名.表名则匹配的数据会发送到以’库名_表名’为名称的topic;例如exmaple3.\\mytest,则自动生成的topic名为exmaple3_mytest
如要指定topic名称,则可以配置:以topic名 ‘:’ 正则规则作为配置, 多个topic配置之间以 ';'隔开, message会发送到所有符合规则的topic
canal.mq.dynamicTopic=example4:mytest3.user
可以解释为mytest3(库名)下的user(表名)的binlog消息发送到example4(topic)中
(2).修改canal配置文件
vi /home/admin/canal-server/conf/canal.properties
修改部分配置
#这里的IP如果是外网访问就填写外网IP,内网访问就填写内网IP
#zookeeper的连接地址
canal.zkServers = xxx.xx.xx.xxx:2181
#如果系统是1个cpu,需要设置为false
canal.instance.parser.parallel = true
#连接模式选择kafka
canal.serverMode = kafka
#kafka的连接地址
kafka.bootstrap.servers = xxx.xx.xx.xxx:9092
kafka.batch.size = 32768
kafka.linger.ms = 150
kafka.max.request.size = 2097152
kafka.buffer.memory = 33554432
kafka.retries = 2
输入exit退出容器,然后重启canal
docker restart canal
(3).查看日志
查看canal日志
cat /home/admin/canal-server/logs/canal/canal.log
2021-04-29 17:53:18.030 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## set default uncaught exception handler
2021-04-29 17:53:18.058 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## load canal configurations
2021-04-29 17:53:18.180 [main] WARN org.apache.kafka.clients.producer.ProducerConfig - The configuration 'kerberos.enable' was supplied but isn't a known config.
2021-04-29 17:53:18.181 [main] WARN org.apache.kafka.clients.producer.ProducerConfig - The configuration 'kerberos.krb5.file' was supplied but isn't a known config.
2021-04-29 17:53:18.181 [main] WARN org.apache.kafka.clients.producer.ProducerConfig - The configuration 'kerberos.jaas.file' was supplied but isn't a known config.
2021-04-29 17:53:18.182 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## start the canal server.
2021-04-29 17:53:18.340 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[172.17.0.2(172.17.0.2):11111]
2021-04-29 17:53:19.457 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## the canal server is running now ......
查看instance日志
cat /home/admin/canal-server/logs/example/example.log
2021-04-29 17:53:18.681 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [canal.properties]
2021-04-29 17:53:18.684 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [example/instance.properties]
2021-04-29 17:53:18.840 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [canal.properties]
2021-04-29 17:53:18.840 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [example/instance.properties]
2021-04-29 17:53:19.428 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example
2021-04-29 17:53:19.435 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table filter : ^ums_users\..*$|
2021-04-29 17:53:19.435 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table black filter : ^mysql\.slave_.*$
2021-04-29 17:53:19.453 [main] INFO c.a.otter.canal.instance.core.AbstractCanalInstance - start successful....
2021-04-29 17:53:19.485 [destination = example , address = /192.168.0.174:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> begin to find start position, it will be long time for reset or first position
2021-04-29 17:53:19.485 [destination = example , address = /192.168.0.174:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - prepare to find start position just last position
{"identity":{"slaveId":-1,"sourceAddress":{"address":"192.168.0.174","port":3306}},"postion":{"gtid":"","included":false,"journalName":"mysql-bin.000010","position":320990133,"serverId":1,"timestamp":1619689785000}}
2021-04-29 17:53:19.854 [destination = example , address = /192.168.0.174:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> find start position successfully, EntryPosition[included=false,journalName=mysql-bin.000010,position=320990133,serverId=1,gtid=,timestamp=1619689785000] cost : 361ms , the next step is binlog dump
(4).验证
在被监控的表中修改一个数据,打开kafka,查看topic列表
kafka-topics.sh --list --zookeeper 192.168.0.188:2181
如果发现有自动生成的topic
oms_orders_order
oms_orders_order_detail
则输入
kafka-console-consumer.sh --bootstrap-server 192.168.0.188:9092 --topic oms_orders_order_detail --from-beginning
可以看到canal发送到kafka中的binlog消息
{"data":[{"id":"4"}],"database":"oms_orders","es":1618901851000,"id":165,"isDdl":false,"mysqlType":{"id":"int(10) unsigned"},
"old":[{}],"pkNames":["id"],"sql":"","sqlType":{"id":4},"table":"order_detail","ts":1618901851514,"type":"UPDATE"}
注意:以上IP均需要根据实际填写,如果失败,网络相关的问题建议检查云服务器的网络安全组是否放开相应的端口,虚拟机的话检查防火墙是否关闭,遇到其他问题请自行检索
六、docker安装HIVE
1. 注意事项
Hive是基于Hadoop环境搭建的,所以要注意Hive和Hadoop版本的对应情况,具体可以查阅
版本对应关系文档Hadoop2和Hadoop3端口是有变化的,一定要根据版本号开放相应的端口,具体如下:
Hadoop2 → Hadoop3
Namenode 端口:
NNPorts Namenode 8020 → 9820
NNPorts NN HTTP UI 50070 → 9870
NNPorts NN HTTPS UI 50470 → 9871
Secondary NN 端口:
SNN ports SNN HTTP 50091 → 9869
SNN ports SNN HTTP UI 50090 → 9868
Datanode 端口:
DN ports DN IPC 50020 → 9867
DN ports DN 50010 → 9866
DN ports DN HTTP UI 50075 → 9864
DN ports Namenode 50475 → 9865
一定要注意版本和端口,本次搭建采用的hadoop-3.2.2和hive-3.1.2
2. docker安装Hive
采用远程模式安装hive,也就是将Mysql数据库独立出来,将元数据保存在远端独立的Mysql服务器中。
创建网桥
docker network create hadoop
获取Hadoop-hive项目的配置
git clone https://github.com/Nan-official/hadoop-hive.git
构建镜像
docker build -t hadoop-hive:1.0 .
运行镜像
cd /hadoop-hive
bash start-container.sh
这一步会直接进入到docker容器的master节点中,然后分别执行
vim /usr/local/hadoop/sbin/start-dfs.sh
vim /usr/local/hadoop/sbin/stop-dfs.sh
将
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
添加到文件头部,然后分别执行
vim /usr/local/hadoop/sbin/start-yarn.sh
vim /usr/local/hadoop/sbin/stop-yarn.sh
将
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
添加到文件头部。
关闭安全模式
hadoop dfsadmin -safemode leave
配置hive-site.xml文件
vim /usr/local/hive/conf/hive-site.xml
注意:请根据实际情况修改mysql地址,用户名和密码。由于mysql是ip访问的,需要关闭ssl连接,所以一定要添加useSSL=false
hive元数据库初始化
/usr/local/hive/bin/schematool -dbType mysql -initSchema
如果成功会看到:
更改jar包
#删除hive的低版本guava包
rm -rf /usr/local/hive/lib/guava-14.0.1-jre.jar
#复制Hadoop高版本guava包到hive中
cp /usr/local/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/hive/lib/
输入exit退出容器,然后重启
docker restart hadoop-master
3. 开启Hadoop
进入容器
docker exec -it hadoop-master /bin/bash
然后输入
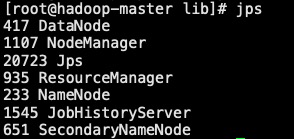
bash start-hadoop.sh
输入jps查看所有节点是否启动如下:
运行wordcount测试
bash run-wordcount.sh
成功后如下:
...
input file1.txt:
Hello Hadoop
input file2.txt:
Hello Docker
wordcount output:
Docker 1
Hadoop 1
Hello 2
wordcount的执行速度取决于机器性能
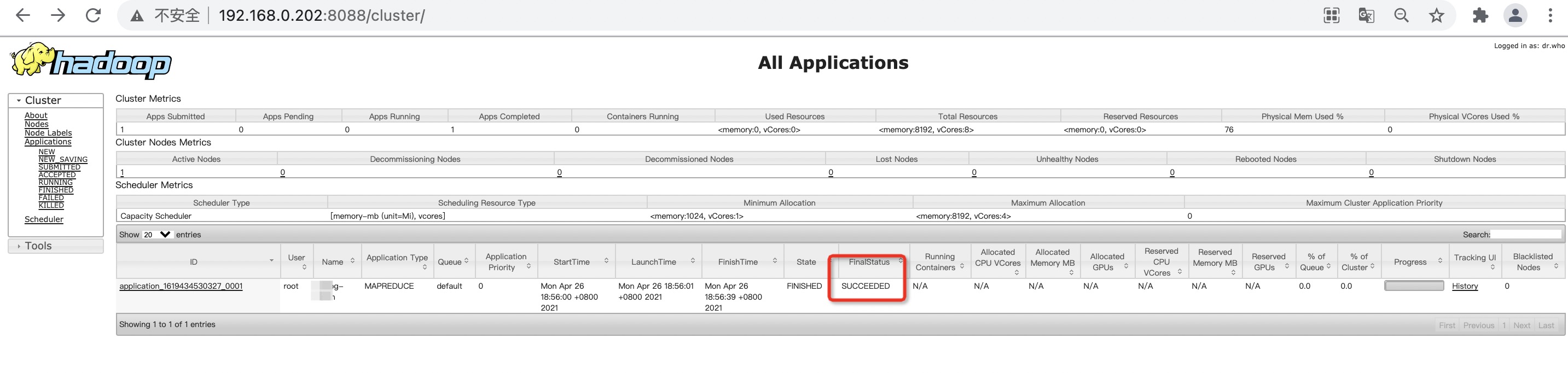
在浏览器输入
http://192.168.0.202:8088/cluster/
可以查看此次运算是否成功:
使用hdfs 管理页面,查看刚刚创建的数据
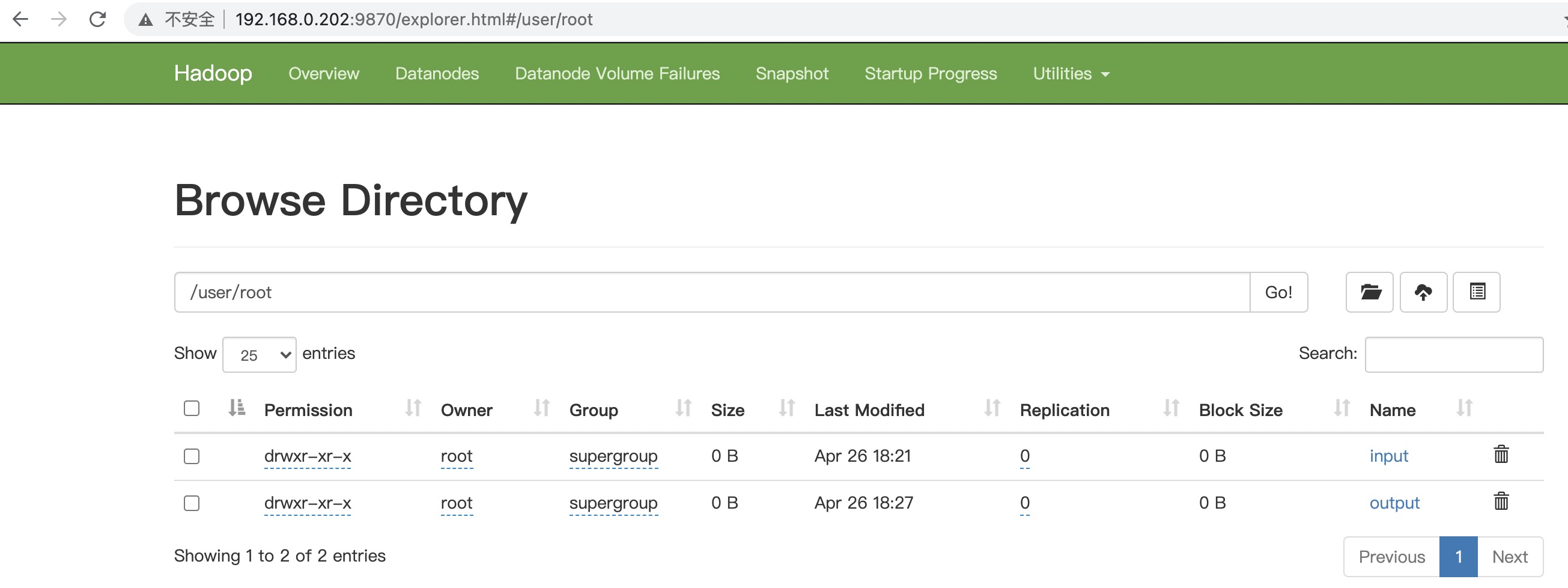
在浏览器输入
http://192.168.0.202:9870/explorer.html#/user/root
查看刚刚创建的数据:
注意:以上IP根据自己的实际情况进行修改,只有在hdfs管理器中才能看到生成的数据,直接在容器内是无法看到的,不要因为在容器内无法看到数据就以为执行失败了
七、集成Camus
1. 自定义binlog落地方式
Camus的官方Git地址:https://github.com/confluentinc/camus
将Camus源码clone到本地后,在com.linkedin.camus.etl.kafka.common下新建一个自定义的CanalBinlogRecordWriterProvider,代码如下
package com.linkedin.camus.etl.kafka.common;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.parser.Feature;
import com.linkedin.camus.coders.CamusWrapper;
import com.linkedin.camus.etl.IEtlKey;
import com.linkedin.camus.etl.RecordWriterProvider;
import com.linkedin.camus.etl.kafka.mapred.EtlMultiOutputFormat;
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.DefaultCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.io.compress.SnappyCodec;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.ReflectionUtils;
import java.io.DataOutputStream;
import java.io.IOException;
import java.util.Map;
@Slf4j
public class CanalBinlogRecordWriterProvider implements RecordWriterProvider {
protected String recordDelimiter = null;
public static final String ETL_OUTPUT_RECORD_DELIMITER = "etl.output.record.delimiter";
public static final String DEFAULT_RECORD_DELIMITER = "\n";
private boolean isCompressed = false;
private CompressionCodec codec = null;
private String extension = "";
public CanalBinlogRecordWriterProvider(TaskAttemptContext context) {
Configuration conf = context.getConfiguration();
if (recordDelimiter == null) {
recordDelimiter = conf.get(ETL_OUTPUT_RECORD_DELIMITER, DEFAULT_RECORD_DELIMITER);
}
isCompressed = FileOutputFormat.getCompressOutput(context);
if (isCompressed) {
Class<? extends CompressionCodec> codecClass = null;
if ("snappy".equals(EtlMultiOutputFormat.getEtlOutputCodec(context))) {
codecClass = SnappyCodec.class;
} else if ("gzip".equals((EtlMultiOutputFormat.getEtlOutputCodec(context)))) {
codecClass = GzipCodec.class;
} else {
codecClass = DefaultCodec.class;
}
codec = ReflectionUtils.newInstance(codecClass, conf);
extension = codec.getDefaultExtension();
}
}
static class CanalBinlogRecordWriter extends RecordWriter<IEtlKey, CamusWrapper> {
private DataOutputStream outputStream;
private String fieldDelimiter;
private String rowDelimiter;
public CanalBinlogRecordWriter(DataOutputStream outputStream, String fieldDelimiter, String rowDelimiter) {
this.outputStream = outputStream;
this.fieldDelimiter = fieldDelimiter;
this.rowDelimiter = rowDelimiter;
}
@Override
public void write(IEtlKey key, CamusWrapper value) throws IOException, InterruptedException {
log.info("IEtlKey key:"+key.toString()+" CamusWrapper value: " + value.toString());
if (value == null) {
return;
}
String recordStr = (String) value.getRecord();
JSONObject record = JSON.parseObject(recordStr, Feature.OrderedField);
if (record.getString("isDdl").equals("true")) {
return;
}
log.info("record:" + record.toJSONString());
JSONArray data = record.getJSONArray("data");
if (data != null && data.size() > 0){
for (int i = 0; i < data.size(); i++) {
JSONObject obj = data.getJSONObject(i);
if (obj != null) {
StringBuilder fieldsBuilder = new StringBuilder();
fieldsBuilder.append(record.getLong("id"));
fieldsBuilder.append(fieldDelimiter);
fieldsBuilder.append(record.getLong("es"));
fieldsBuilder.append(fieldDelimiter);
fieldsBuilder.append(record.getLong("ts"));
fieldsBuilder.append(fieldDelimiter);
fieldsBuilder.append(record.getString("type"));
for (Map.Entry<String, Object> entry : obj.entrySet()) {
fieldsBuilder.append(fieldDelimiter);
fieldsBuilder.append(entry.getValue());
}
fieldsBuilder.append(rowDelimiter);
outputStream.write(fieldsBuilder.toString().getBytes());
log.info("fieldsBuilder.toString()" + fieldsBuilder.toString());
}
}
}
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
outputStream.close();
}
}
@Override
public String getFilenameExtension() {
return "";
}
@Override
public RecordWriter<IEtlKey, CamusWrapper> getDataRecordWriter(
TaskAttemptContext context,
String fileName,
CamusWrapper data,
FileOutputCommitter committer
) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
String rowDelimiter = conf.get("etl.output.record.delimiter", "\n");
Path path = new Path(committer.getWorkPath(), EtlMultiOutputFormat.getUniqueFile(context, fileName, getFilenameExtension()));
FileSystem fs = path.getFileSystem(conf);
FSDataOutputStream outputStream = fs.create(path, false);
return new CanalBinlogRecordWriter(outputStream, "\t", rowDelimiter);
}
}
2. 配置Camus
定义完provider之后,将其配置到配置文件camus.properties中,此配置文件在camus-confluent-master/camus-example/src/main/resources/camus.properties,
每一个properties就代表了一个Camusjob(本质上是MR job),配置信息如下:
# Kafka brokers kafka的ip
kafka.brokers=xxx.xx.xx.xxx:9092
# job名称
camus.job.name=binlog-fetch
# Kafka数据落地到HDFS的位置。Camus会按照topic名自动创建子目录
etl.destination.path=/usr/local/camus/exec/topic
# HDFS上用来保存当前Camus job执行信息的位置,如offset、错误日志等
# base.path是基础路径,其它路径要在base.path之下
etl.execution.base.path=/usr/local/camus/exec
# HDFS上保存Camus job执行历史的位置
etl.execution.history.path=/usr/local/camus/exec/history
# 即core-site.xml中的fs.defaultFS参数
fs.default.name=hdfs://hadoop-master:9000
# Kafka消息解码器,默认有JsonStringMessageDecoder和KafkaAvroMessageDecoder
# Canal的Binlog是JSON格式的。当然我们也可以自定义解码器
camus.message.decoder.class=com.linkedin.camus.etl.kafka.coders.JsonStringMessageDecoder
# 落地到HDFS时的写入器,默认支持Avro、SequenceFile和字符串
# 这里我们采用一个自定义的WriterProvider,代码在后面
# etl.record.writer.provider.class=com.linkedin.camus.etl.kafka.coders.JsonStringMessageDecoder
etl.record.writer.provider.class=com.linkedin.camus.etl.kafka.common.CanalBinlogRecordWriterProvider
# JSON消息中的时间戳字段,用来做分区的
# 注意这里采用Binlog的业务时间,而不是日志时间
camus.message.timestamp.field=es
# 时间戳字段的格式
camus.message.timestamp.format=unix_milliseconds
# 时间分区的类型和格式,默认支持小时、天,也可以自定义时间
etl.partitioner.class=com.linkedin.camus.etl.kafka.partitioner.TimeBasedPartitioner
etl.destination.path.topic.sub.dirformat='pt_hour'=YYYYMMddHH
# 拉取过程中MR job的mapper数
mapred.map.tasks=20
# 按照时间戳字段,一次性拉取多少个小时的数据过后就停止,-1为不限制
kafka.max.pull.hrs=-1
# 时间戳早于多少天的数据会被抛弃而不入库
kafka.max.historical.days=3
# 每个mapper的最长执行分钟数,-1为不限制
kafka.max.pull.minutes.per.task=-1
# Kafka topic白名单和黑名单,白名单必填
kafka.blacklist.topics=oms_orders_orders,oms_orders_order_detail
kafka.whitelist.topics=
kafka.client.name=camus
# 设定输出数据的压缩方式,支持deflate、gzip和snappy
mapred.output.compress=false
# etl.output.codec=gzip
# etl.deflate.level=6
# 设定时区,以及一个时间分区的单位
etl.default.timezone=Asia/Shanghai
etl.output.file.time.partition.mins=60
3. Camus job的执行和调度
(1). 通过hadoop jar命令来执行Camus job
具体方式为:
将代码导入IDE中,添加provider并修改完properties之后,在camus-etl-kafka的pom文件中加入
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.linkedin.camus.etl.kafka.CamusJob</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
然后使用maven install进行打包,将target中内存占用最大的jar包以及camus-confluent-master/camus-example/src/main/resources下的camus.properties和log4j.xml
一同上传到hive的docker容器的任意文件夹内,在该文件夹中使用命令:
hadoop jar camus-etl-kafka-5.0.0-SNAPSHOT.jar com.linkedin.camus.etl.kafka.CamusJob -P camus.properties
执行Camus job
(2). 使用camus-run工具执行
项目内直接提供了camus-run工具,将修改完毕的camus项目直接上传到hive的docker容器中的任意文件夹内,将camus.properties上传到同一文件夹中,然后在camus项目的根目录文件夹内使用命令:
bin/camus-run -P camus.properties
执行Camus job。
(3). 通过Crontab调度
参考:
Crontab命令详解
4. 数据从hadoop到hive,执行如下脚本:
date_string=$(date '+%Y/%m/%d/%H')
partion=$(date '+%Y-%m-%d_%H')
topic='topic名称'
table_name='要生成的表名'
filePath="/usr/local/camus/exec/topic/"$date_string"/"
hive<<EOF
create table if not exists $table_name(
date TIMESTAMP,
node STRING,
status STRING
)
PARTITIONED BY(dt STRING)
row format delimited
fields terminated by '|'
STORED AS TEXTFILE;
load data inpath '$filePath' into table $table_name partition (dt='$partion');
EOF
注意:以上脚本要根据自身需求做相应更改
参考文档
https://www.jianshu.com/p/2dae7b13ce2f
https://blog.csdn.net/weixin_44861708/article/details/115044638
https://www.jianshu.com/p/4c4213385368
https://www.cnblogs.com/coding-now/p/14660571.html
https://blog.csdn.net/qq_32923745/article/details/78286385
https://www.cnblogs.com/xiao987334176/p/13213966.html
目录 返回
首页