Kubernetes HPA 使用详解
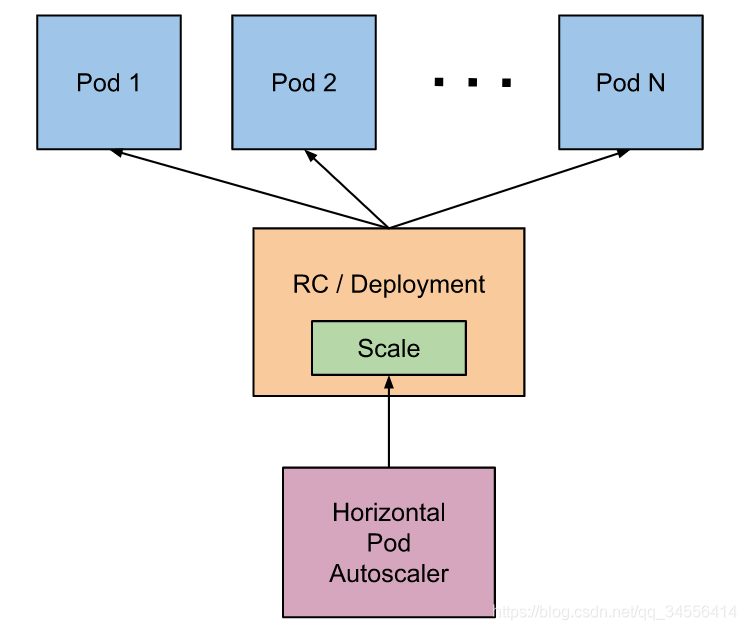
在前面的学习中我们使用用一个 kubectl scale 命令可以来实现 Pod 的扩缩容功能,但是这个毕竟是完全手动操作的,要应对线上的各种复杂情况,我们需要能够做到自动化去感知业务,来自动进行扩缩容。为此,Kubernetes 也为我们提供了这样的一个资源对象:Horizontal Pod Autoscaling(Pod 水平自动伸缩),简称HPA,HPA 通过监控分析一些控制器控制的所有 Pod 的负载变化情况来确定是否需要调整 Pod 的副本数量,这是 HPA 最基本的原理:
HPA
我们可以简单的通过 kubectl autoscale 命令来创建一个 HPA 资源对象,HPA Controller默认30s轮询一次(可通过 kube-controller-manager 的--horizontal-pod-autoscaler-sync-period 参数进行设置),查询指定的资源中的 Pod 资源使用率,并且与创建时设定的值和指标做对比,从而实现自动伸缩的功能。
Metrics Server
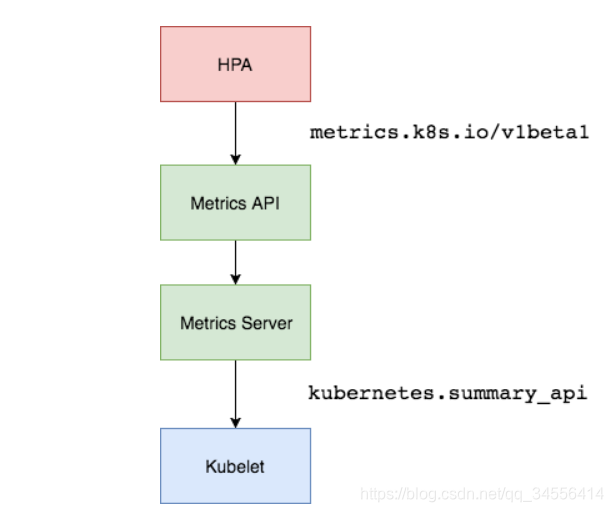
在 HPA 的第一个版本中,我们需要 Heapster 提供 CPU 和内存指标,在 HPA v2 过后就需要安装 Metrcis Server 了,Metrics Server 可以通过标准的 Kubernetes API 把监控数据暴露出来,有了 Metrics Server 之后,我们就完全可以通过标准的 Kubernetes API 来访问我们想要获取的监控数据了:
https://10.96.0.1/apis/metrics.k8s.io/v1beta1/namespaces/<namespace-name>/pods/<pod-name>比如当我们访问上面的 API 的时候,我们就可以获取到该 Pod 的资源数据,这些数据其实是来自于 kubelet 的 Summary API 采集而来的。不过需要说明的是我们这里可以通过标准的 API 来获取资源监控数据,并不是因为 Metrics Server 就是 APIServer 的一部分,而是通过 Kubernetes 提供的 Aggregator 汇聚插件来实现的,是独立于 APIServer 之外运行的。
HAP Metrics Server
聚合 API
Aggregator 允许开发人员编写一个自己的服务,把这个服务注册到 Kubernetes 的 APIServer 里面去,这样我们就可以像原生的 APIServer 提供的 API 使用自己的 API 了,我们把自己的服务运行在 Kubernetes 集群里面,然后 Kubernetes 的 Aggregator 通过 Service 名称就可以转发到我们自己写的 Service 里面去了。这样这个聚合层就带来了很多好处:
- 增加了 API 的扩展性,开发人员可以编写自己的 API 服务来暴露他们想要的 API。
- 丰富了 API,核心 kubernetes 团队阻止了很多新的 API 提案,通过允许开发人员将他们的 API 作为单独的服务公开,这样就无须社区繁杂的审查了。
- 开发分阶段实验性 API,新的 API 可以在单独的聚合服务中开发,当它稳定之后,在合并会 APIServer 就很容易了。
- 确保新 API 遵循 Kubernetes 约定,如果没有这里提出的机制,社区成员可能会被迫推出自己的东西,这样很可能造成社区成员和社区约定不一致。
需要指出的是, Metrics Server 并不是 kube-apiserver 的一部分,而是通过 Aggregator 这种插件机制,在独立部署的情况下同 kube-apiserver 一起统一对外服务的。
这里,Aggregator APIServer 的工作原理,可以用如下所示的一幅示意图来表示清楚:
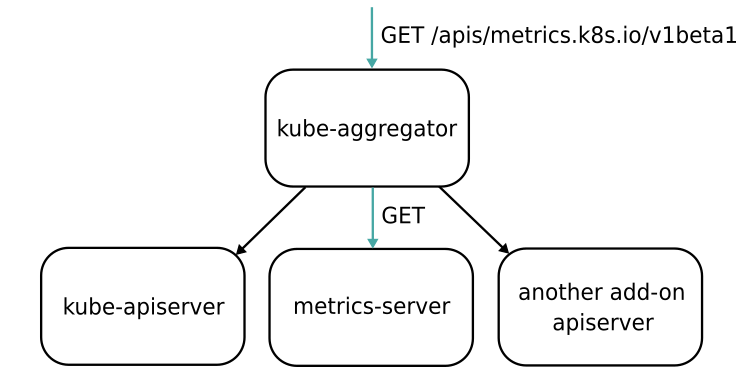
可以看到,当 Kubernetes 的 API Server 开启了 Aggregator 模式之后,你再访问 apis/metrics.k8s.io/v1beta1 的时候,实际上访问到的是一个叫作 kube-aggregator 的代理。而 kube-apiserver,正是这个代理的一个后端,而 Metrics Server,则是另一个后端。
而且,在这个机制下,你还可以添加更多的后端给这个 kube-aggregator。所以 kube-aggregator 其实就是一个根据 URL 选择具体的 API 后端的代理服务器。通过这种方式,我们就可以很方便地扩展 Kubernetes 的 API 了。
而 Aggregator 模式的开启也非常简单:
- 如果你是使用 kubeadm 或者官方的 kube-up.sh 脚本部署 Kubernetes 集群的话,Aggregator 模式就是默认开启的
- 如果是手动 DIY 搭建的话,你就需要在 kube-apiserver 的启动参数里加上如下所示的配置:
--requestheader-client-ca-file=<path to aggregator CA cert>
--requestheader-allowed-names=front-proxy-client
--requestheader-extra-headers-prefix=X-Remote-Extra
---requestheader-group-headers=X-Remote-Group
--requestheader-username-headers=X-Remote-User
--proxy-client-cert-file=<path to aggregator proxy cert>
--proxy-client-key-file=<path to aggregator proxy key>而这些配置的作用,主要就是为 Aggregator 这一层设置对应的 Key 和 Cert 文件。而这些文件的生成,就需要你自己手动完成了,具体流程请参考这篇官方文档。
Aggregator 功能开启之后,你只需要将 Metrics Server 的 YAML 文件部署起来
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
目录 返回
首页